标签:行修改 val headers result 设置 secure pre 响应 userinfo
18.4 操作 excel 文件
Python 中一般使用 xlrd 库来读取 Excel 文件, xlrd 库是 Python 的第三方库。
Xlrd 库跟其他第三方库一样,都是通过 pip install xlrd 命令来安装。
安装成功之后,在 C:\Python34\Lib\site-packages 下可以看到相应的Xlrd 库目录。
以下是xlrd 库下的相应模块方法
备注:喜欢研究的同学,可以去研究 xlrd 库下的相应模块的实现原理。
例如:读取 result.xls 的数据。
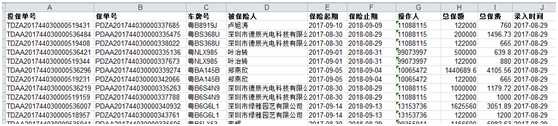
程序实现:
#导入 xlrd 库
import xlrd
# 打开 Excel 读取文件,open_workbook()为打开 Excel文件的方法,参数为:文件名
result_file =xlrd.open_workbook("./result.xls")

代码实现:
#导入 xlrd 库
import xlrd
# 打开 Excel 读取文件,open_workbook()为打开 Excel文件的方法,参数为:文件名
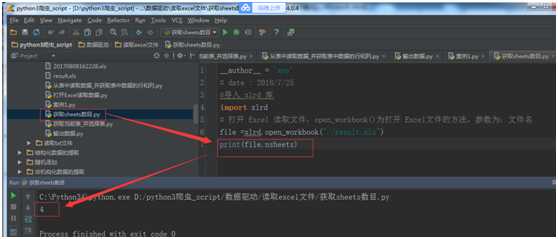
file =xlrd.open_workbook("./result.xls")
print(file.nsheets)
运行结果:
代码实现:
#导入 xlrd 库
import xlrd
# 打开 Excel 读取文件,open_workbook()为打开 Excel文件的方法,参数为:文件名
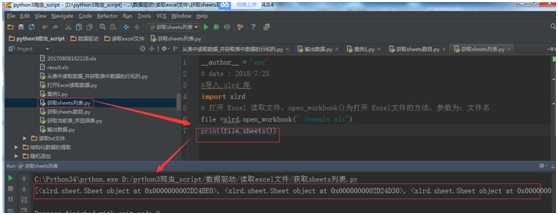
file =xlrd.open_workbook("./result.xls")
print(file.sheets())
运行结果:
代码实现:
#导入 xlrd 库
import xlrd
# 打开 Excel 读取文件,open_workbook()为打开 Excel文件的方法,参数为:文件名
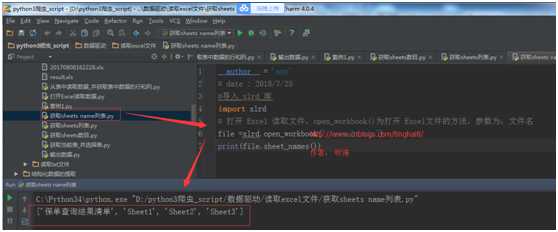
file =xlrd.open_workbook("./result.xls")
print(file.sheet_names())
运行结果:
代码实现:
#导入 xlrd 库
import xlrd
# 打开 Excel 读取文件,open_workbook()为打开 Excel文件的方法,参数为:文件名
file =xlrd.open_workbook("./result.xls")
print(file.sheets())
sheet1 = file.sheets()[0] #sheets返回一个sheet列表
sheet2 = file.sheet_by_index(0) #通过索引顺序获取
sheet3 = file.sheet_by_name(‘保单查询结果清单‘) #通过名称获取
代码实现:
#导入 xlrd 库
import xlrd
# 打开 Excel 读取文件,open_workbook()为打开 Excel文件的方法,参数为:文件名
file =xlrd.open_workbook("result.xls")
# 获取当前文件的表
shxrange = range(file.nsheets)
try:
sh = file.sheet_by_name("保单查询结果清单")
except:
print("no sheet in %s named ‘保单查询结果清单‘",format("result.xls"))
# 获取行数
nrows =sh.nrows
# 获取列数
ncols = sh.ncols
#打印表格的行数和列数
print("nrows{0},ncols{1}".format(nrows,ncols))
运行结果:
代码实现:
#导入 xlrd 库
import xlrd
# 打开 Excel 读取文件,open_workbook()为打开 Excel文件的方法,参数为:文件名
file =xlrd.open_workbook("result.xls")
# 获取当前文件的表
shxrange = range(file.nsheets)
try:
sh = file.sheet_by_name("保单查询结果清单")
print(sh)
except:
print("no sheet in %s named ‘保单查询结果清单‘",format("result.xls"))
#获取第一行
print(sh.row(1))
#获取第一行值列表
print(sh.row_values(1))
#获取第一列
print(sh.col(1))
#获取第一列值列表
print(sh.col_values(1))
运行结果:

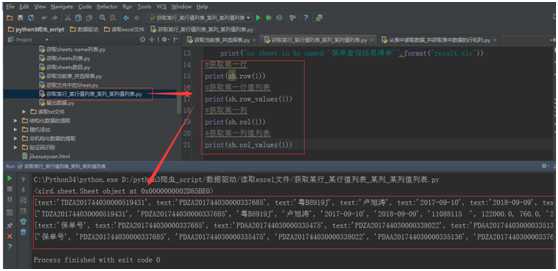
代码实现:
#导入 xlrd 库
import xlrd
# 打开 Excel 读取文件,open_workbook()为打开 Excel文件的方法,参数为:文件名
file =xlrd.open_workbook("result.xls")
# 获取当前文件的表
shxrange = range(file.nsheets)
try:
sh = file.sheet_by_name("保单查询结果清单")
print(sh)
except:
print("no sheet in %s named ‘保单查询结果清单‘",format("result.xls"))
#获取单元格的值
cell = sh.cell(1,1)
print(cell)
cell_value1 = sh.cell_value(1,1)
print(cell_value1)
cell_value2 = sh.cell(1,1).value
print(cell_value2)
运行结果:

注意:用xlrd读取excel是不能对其进行操作的:xlrd.open_workbook()方法返回xlrd.Book类型,是只读的,不能对其进行操作。
案例1:获取result.xls文件下的保单查询结果清单表数据
代码实现:
#导入 xlrd 库
import xlrd
# 打开 Excel 读取文件,open_workbook()为打开 Excel文件的方法,参数为:文件名
file =xlrd.open_workbook("result.xls")
# 获取当前文件的表
shxrange = range(file.nsheets)
try:
sh = file.sheet_by_name("保单查询结果清单")
except:
print("no sheet in %s named ‘保单查询结果清单‘",format("result.xls"))
# 获取行数
nrows =sh.nrows
# 获取列数
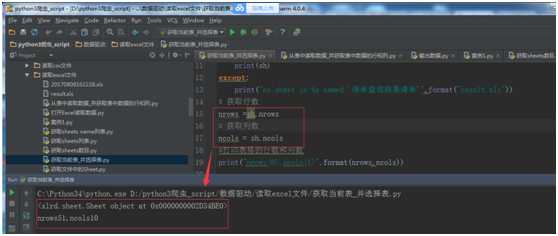
ncols = sh.ncols
#打印表格的行数和列数
print("nrows{0},ncols{1}".format(nrows,ncols))
#获取第二行第一列数据(第一行是标题)
cell_value = sh.cell_value(1,0)
print(cell_value)
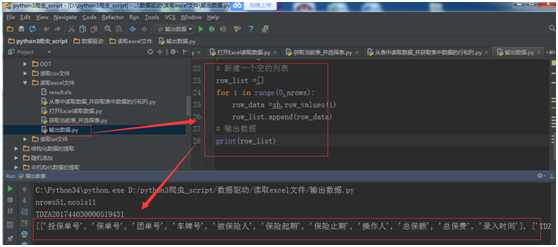
# 新建一个空的列表
row_list =[]
for i in range(0,nrows):
row_data =sh.row_values(i)
row_list.append(row_data)
# 输出数据
print(row_list)
运行结果:
案例2:xlrd读取Excel中的日期。
#导入 xlrd 库
import xlrd
# 打开 Excel 读取文件,open_workbook()为打开 Excel文件的方法,参数为:文件名
file =xlrd.open_workbook("./result.xls")
# 获取当前文件的表
shxrange = range(file.nsheets)
try:
sh = file.sheet_by_name("保单查询结果清单")
except:
print("no sheet in %s named ‘保单查询结果清单‘",format("result.xls"))
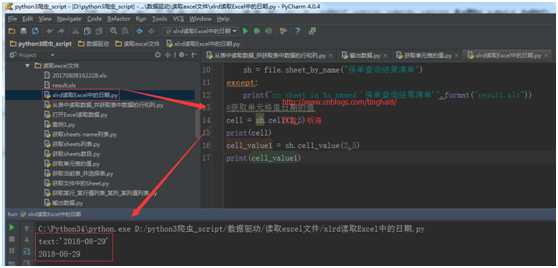
#获取单元格的值
cell = sh.cell(2,5)
print(cell)
cell_value1 = sh.cell_value(2,5)
print(cell_value1)
运行结果:
Xlrd 库只读,如果想新建一个test.xls文件,就需要安装 xlwt 库,跟其他第三方库一样,都是通过 pip install xlwt 命令来安装。
安装成功之后,在 C:\Python34\Lib\site-packages 下可以看到相应的 xlwt 库目录。
程序实现:
from xlwt import *
book = Workbook(encoding=‘utf-8‘)
sheet = book.add_sheet(‘Sheet1‘)
book.save(‘myExcel.xls‘)
运行结果:
Workbook 类可以有 encoding 和 style_compression 参数。
【encoding】:设置字符编码,
【style_compression】:表示是否压缩。
这样设置:w = Workbook(encoding=‘utf-8‘),就可以在excel中输出中文了。默认是ascii。
格式:sheet.write(r, c, label="", style=Style.default_style)
(1)简单写入。
程序实现:
from xlwt import *
book = Workbook(encoding=‘utf-8‘)
sheet = book.add_sheet(‘Sheet1‘)
# 在sheet1 中简单插入内容
sheet.write(0, 0, label = ‘Row 0, Column 0 Value‘)
# 保存内容
book.save(‘test1.xls‘)
运行结果:

(2)设置格式写入。
代码实现:
from xlwt import *
import xlwt
book = Workbook(encoding=‘utf-8‘)
sheet = book.add_sheet(‘Sheet1‘)
# 设置格式
font = xlwt.Font() # 字体
font.name = ‘Times New Roman‘
font.bold = True
font.underline = True
font.italic = True
style = xlwt.XFStyle() # 创建一个格式
style.font = font # 设置格式字体
# 在sheet1 中插入格式化的内容
sheet.write(1, 0, label = ‘Formatted value‘, style) # Apply the Style to the Cell
# 保存内容
book.save(‘test2.xls‘)
备注:这个例子,需要运行的机器有对应的字体。
(3)写入日期。
程序实现:
from xlwt import *
import xlwt
import time
book = Workbook(encoding=‘utf-8‘)
sheet = book.add_sheet(‘Sheet1‘)
style = xlwt.XFStyle()
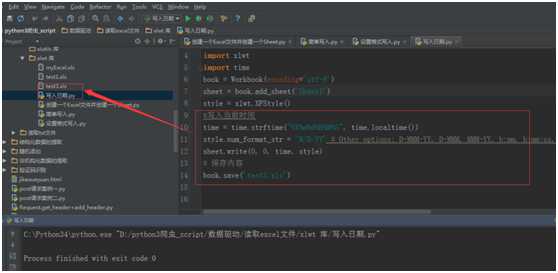
#写入当前时间
time = time.strftime("%Y%m%d%H%M%S", time.localtime())
style.num_format_str = ‘M/D/YY‘ # Other options: D-MMM-YY, D-MMM, MMM-YY, h:mm, h:mm:ss, h:mm, h:mm:ss, M/D/YY h:mm, mm:ss, [h]:mm:ss, mm:ss.0
sheet.write(0, 0, time, style)
# 保存内容
book.save(‘test3.xls‘)
运行结果:
(4)写入公式。
程序实现:
from xlwt import *
import xlwt
book = Workbook(encoding=‘utf-8‘)
sheet = book.add_sheet(‘Sheet1‘)
#写入公式
sheet.write(0, 0, 5) # Outputs 5
sheet.write(0, 1, 2) # Outputs 2
sheet.write(1, 0, xlwt.Formula(‘A1*B1‘)) # 输出 "10" (A1[5] * A2[2])
sheet.write(1, 1, xlwt.Formula(‘SUM(A1,B1)‘)) # 输出 "7" (A1[5] + A2[2])
# 保存内容
book.save(‘test4.xls‘)
运行结果:


(5)写入链接。
程序实现:
from xlwt import *
import xlwt
book = Workbook(encoding=‘utf-8‘)
sheet = book.add_sheet(‘Sheet1‘)
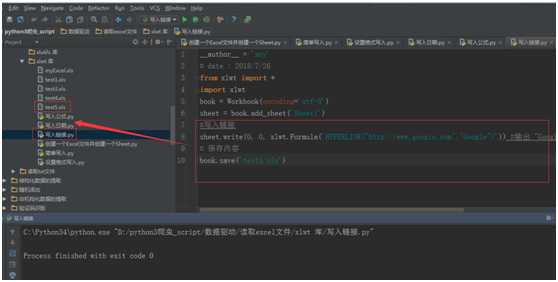
#写入链接
sheet.write(0, 0, xlwt.Formula(‘HYPERLINK("http://www.google.com";"Google")‘)) #输出 "Google"链接到http://www.google.com
# 保存内容
book.save(‘test5.xls‘)
运行结果:
如果想修改一个test.xls文件内容,就需要安装 xlutils 库,跟其他第三方库一样,也是通过 pip install xlutils 命令来安装。

安装成功之后,在 C:\Python34\Lib\site-packages 下可以看到相应的 xlutils 库目录。
原理:复制一个 xlrd.Book 对象,生成一个 xlwt.Workbook 对象,可以对 xlwt.Workbook 进行修改。
例子:
第一步:先新建一个test1.xls文件,在里面写入4条数据。
程序实现:
from xlwt import *
from xlrd import open_workbook
from xlutils.copy import copy
#新建一个 test1.xls 的文件,并在新建的文件里写入内容。
book = Workbook(encoding=‘utf-8‘)
sheet = book.add_sheet(‘Sheet1‘)
sheet.write(0, 0, label = ‘name‘)
sheet.write(0, 1, label = ‘age‘)
sheet.write(1, 0, label = ‘xiao‘)
sheet.write(1, 1, label = ‘18‘)
book.save(‘test1.xls‘)
运行结果:

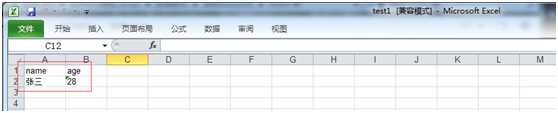
第二步:修改test1.xls文件内容。
程序实现:
from xlwt import *
from xlrd import open_workbook
from xlutils.copy import copy
#第二步:打开文件,修改文件内容
book = open_workbook(‘test1.xls‘)
wb = copy(book) #wb即为xlwt.WorkBook对象
ws = wb.get_sheet(0) #通过get_sheet()获取的sheet有write()方法
ws.write(1, 0, ‘张三‘)
ws.write(1, 1, ‘28‘)
wb.save(‘test1.xls‘)
运行结果:
教育局招生管理系统登录接口用例参数化实现步骤:
(一)编写完整的接口测试用例
1、打开抓包工具:fiddler。
2、登录教育局招生管理系统。
3、抓取登录http请求。
4、分析登录http请求(请求地址、是否重定向、get请求还是post请求、请求的头信息、请求的response)。
5、数据的处理(处理抓取到的头信息)
6、编写接口代码。
7、接口测试结果断言验证。
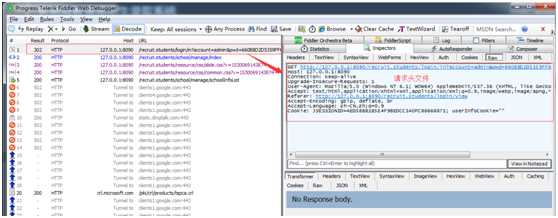
第一步:下面对fiddler抓取到的数据进行分析。
【请求方法】:带参数的get
【请求地址】:http://127.0.0.1:8090/recruit.students/login/in?account=admin&pwd=660B8D2D5359FF6F94F8D3345698F88C
【请求头信息】:
Host: 127.0.0.1:8090
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Referer: http://127.0.0.1:8090/recruit.students/login/view
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: JSESSIONID=AED5BBB1B5E4F9BEDCC3A0FC88668871; userInfoCookie=""
【请求的response】:空
请求的 response 为空是因为登录的时候,做了跳转,状态码为:302,跳转到了
http://127.0.0.1:8090/recruit.students/school/manage/index 这个地址,这个状态码为200。
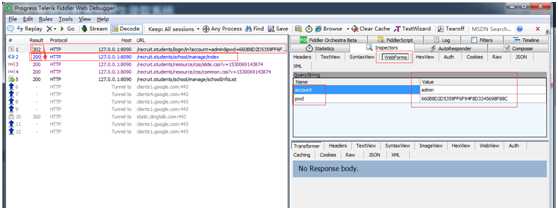
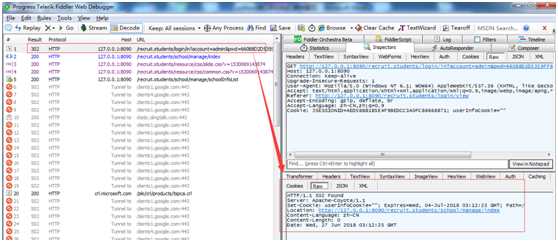
查看http://127.0.0.1:8090/recruit.students/school/manage/index 这个地址请求的response,返回的是登陆后的信息。
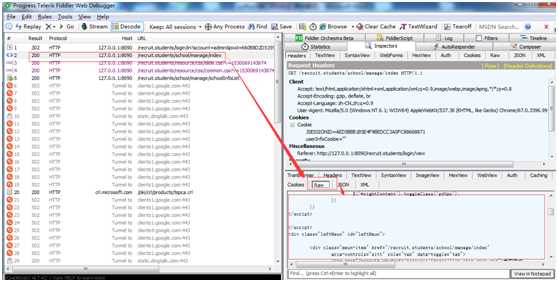
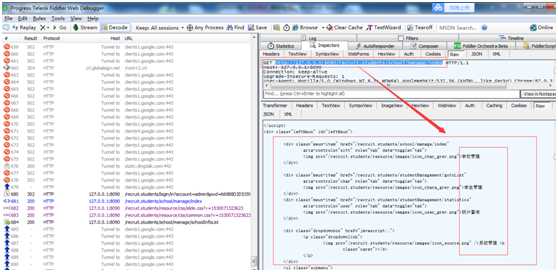
通过分析,我们是清楚的了解到这个接口的情况。
第二步:接着还需要请求头信息的处理,去掉一些没用的请求头信息,保留如下:
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Referer": "http://127.0.0.1:8090/recruit.students/login/view",
【Connection】:如果只是测试登录接口,这个参数可以去掉,如果需要测试登录之后新建学校,那这个头信息就需要保留。
【User-Agent】:模拟用户利用浏览器访问Web网站的真实行为,每个接口都需要。
【Referer】:登录重定向的时候用到。
第三步:最后编写代码实现。
程序实现:
import requests
url="http://127.0.0.1:8090/recruit.students/login/in?"
#把请求头信息进行处理,去掉一些没用的,保留一些有用头信息·
headers = {
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Referer": "http://127.0.0.1:8090/recruit.students/login/view",
}
# URL参数
payload = {‘account‘: ‘admin‘,‘pwd‘:‘660B8D2D5359FF6F94F8D3345698F88C‘}
# 发送Post请求
response = requests.post(url,headers = headers,data=payload)
# 查看响应内容,response.text 返回的是Unicode格式的数据
print(response.text)
# 查看响应码
print(response.status_code)
(二)新建一个data.xls文件,组织测试用例参数。

(三)编写一个readExcel方法。
程序实现:
import requests
import xlrd
def readExcel(rowx, filePath=‘data.xls‘):
‘‘‘
读取excel中数据并且返回
:parameter filePath:xlsx文件名称
:parameter rowx:在excel中的行数
‘‘‘
book = xlrd.open_workbook(filePath)
sheet = book.sheet_by_index(0)
return sheet.row_values(rowx)
#提取第一个测试用例数据
print("第一行数据内容:",readExcel(2))
#查看数据的类型
print("数据类型:{0}:".format(type(readExcel(2))))
# 从列表中提取url
url = readExcel(2)[3]
print(url)
# 从列表中提取data参数
data = readExcel(2)[4]
print(data)
运行结果:

(四)测试用例数据参数化。
完整程序:
import requests
from bs4 import BeautifulSoup
import xlrd
import json
def readExcel(rowx, filePath=‘data.xls‘):
‘‘‘
读取excel中数据并且返回
:parameter filePath:xlsx文件名称
:parameter rowx:在excel中的行数
‘‘‘
book = xlrd.open_workbook(filePath)
sheet = book.sheet_by_index(0)
return sheet.row_values(rowx)
#提取第一个测试用例数据
print("第一行数据内容:",readExcel(2))
#查看数据的类型
print("数据类型:{0}:".format(type(readExcel(2))))
# 从列表中提取url
url = readExcel(2)[3]
print(url)
# 从列表中提取data参数
# 由于JSON中,标准语法中,不支持单引号,属性或者属性值,都必须是双引号括起来,用字符串方法replace("‘",‘\"‘)进行处理
data1 =readExcel(2)[4].replace("‘",‘\"‘)
#因为请求参数数据类型是字典,所以进行了反序列化的处理。
data = json.loads(data1)
print(data)
print(type(data))
print("---------------------------------------------")
#招生系统接口例子
headers = {
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Referer": "http://127.0.0.1:8090/recruit.students/login/view",
}
# URL参数
payload = data
# 发送get请求
response = requests.get(url,headers = headers,params=payload)
# 打印请求response后的URL
print(response.url)
# 查看响应内容,response.text 返回的是Unicode格式的数据
print(response.text)
# 查看响应码
print(response.status_code)运行结果:
运行结果:

提取Excel表数据注意的几点:
1、需要明确提取excel 表中那个sheet的数据。
2、一个测试用例按行去提取。
3、从Excel表提取的行数据,是一个列表,列表的元素是字符串,如果接口参数类型如果是字典类型,需要反序列化的处理(json.loads())。
4. JSON中,标准语法中,不支持单引号,属性或者属性值,都必须是双引号括起来,用字符串方法replace("‘",‘\"‘)进行处理。
上面已经实现了通过读取Excel表数据进行参数化,大家可能会说,代码看起来很乱!确实是有点乱,接下来我们对上面的代码进行优化。
第一步:定义一个读取 Excel 表的 readExcel() 方法,参数:rowx 。
def readExcel(rowx):
‘‘‘
读取excel中数据并且返回
:parameter filePath:xlsx文件名称
:parameter rowx:在excel中的行数
‘‘‘
book = xlrd.open_workbook(‘data.xls‘)
sheet = book.sheet_by_index(0)
return sheet.row_values(rowx)
第二步:定义一个获取请求 URL 的方法 getUrl(),参数:rowx 。
def getUrl(rowx):
‘‘‘
获取请求URL
:parameter rowx:在excel中的行数
‘‘‘
return readExcel(rowx)[3]
第三步:定义一个获取请求参数的方法 getData(),参数:rowx 。
def getData(rowx):
‘‘‘
获取请求参数
:parameter rowx:在excel中的行数
‘‘‘
# 由于JSON中,标准语法中,不支持单引号,属性或者属性值,都必须是双引号括起来,用字符串方法replace("‘",‘\"‘)进行处理
data1 = readExcel(rowx)[4].replace("‘", ‘\"‘)
# 因为请求参数数据类型是字典,所以进行了反序列化的处理。
data = json.loads(data1)
return data
第四步:用 unittest 单元测试框架编写测试用例。
完整的程序如下:
import requests
from bs4 import BeautifulSoup
import xlrd
import json
import unittest
def readExcel(rowx):
‘‘‘
读取excel中数据并且返回
:parameter filePath:xlsx文件名称
:parameter rowx:在excel中的行数
‘‘‘
book = xlrd.open_workbook(‘data.xls‘)
sheet = book.sheet_by_index(0)
return sheet.row_values(rowx)
def getUrl(rowx):
‘‘‘
获取请求URL
:parameter rowx:在excel中的行数
‘‘‘
return readExcel(rowx)[3]
def getData(rowx):
‘‘‘
获取请求参数
:parameter rowx:在excel中的行数
‘‘‘
# 由于JSON中,标准语法中,不支持单引号,属性或者属性值,都必须是双引号括起来,用字符串方法replace("‘",‘\"‘)进行处理
data1 = readExcel(rowx)[4].replace("‘", ‘\"‘)
# 因为请求参数数据类型是字典,所以进行了反序列化的处理。
data = json.loads(data1)
return data
class Test(unittest.TestCase):
def setup(self):
print("------开始执行用例--------")
def teardown(self):
print("------用例执行结束--------")
def test_case1(self):
url = getUrl(2)
payload = getData(2)
headers = {
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Referer": "http://127.0.0.1:8090/recruit.students/login/view",
}
# 发送get请求
response = requests.get(url,headers=headers,params=payload)
# 打印请求response后的URL
print(response.url)
# 查看响应内容,response.text 返回的是Unicode格式的数据
print(response.text)
# 查看响应码
print(response.status_code)
if __name__ == ‘__main__‘:
unittest.main(verbosity=2)
运行结果:
通过上面的优化之后,可能有些人还是觉得一个文件代码太多,层级不明显,不好维护,那好,我们接着继续优化。
第一步,在当前项目目录下新建一个 Data-Driven 文件夹,把数据文件 data.xls 放到这个目录下,同时,还需要新建一个 __init__.py 的空白文件(该文件的主要作用是初始化Python包)。在__init__.py文件中编写内容
from Data_Driven.data_driven import Data_Excel
第二步:在 Data-Driven 文件夹下,新建一个 data_driven.py 文件,在文件中编写代码。
import xlrd
import json
class Data_Excel(object):
def __init__(self):
pass
def readExcel(self,rowx):
‘‘‘
读取excel中数据并且返回
:parameter filePath:xlsx文件名称
:parameter rowx:在excel中的行数
‘‘‘
book = xlrd.open_workbook(‘data.xls‘)
sheet = book.sheet_by_index(0)
return sheet.row_values(rowx)
def getUrl(self,rowx):
‘‘‘
获取请求URL
:parameter rowx:在excel中的行数
‘‘‘
return self.readExcel(rowx)[3]
def getData(self,rowx):
‘‘‘
获取请求参数
:parameter rowx:在excel中的行数
‘‘‘
# 由于JSON中,标准语法中,不支持单引号,属性或者属性值,都必须是双引号括起来,用字符串方法replace("‘",‘\"‘)进行处理
data1 = self.readExcel(rowx)[4].replace("‘", ‘\"‘)
# 因为请求参数数据类型是字典,所以进行了反序列化的处理。
data = json.loads(data1)
return data
if __name__ == "__main__":
#定义一个类对象
t= Data_Excel()
url = t.getUrl(2)
print(url)
payload = t.getData(2)
print(payload)
第三步:编写我们的测试用例。
import os,sys,requests,unittest
sys.path.append("./Data_Driven")
from data_driven import Data_Excel
class Test(unittest.TestCase,Data_Excel):
def setup(self):
print("------开始执行用例--------")
def teardown(self):
print("------用例执行结束--------")
def test_case1(self):
t = Data_Excel()
url = t.getUrl(2)
payload = t.getData(2)
headers = {
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Referer": "http://127.0.0.1:8090/recruit.students/login/view",
}
# 发送get请求
response = requests.get(url,headers=headers,params=payload)
# 打印请求response后的URL
print(response.url)
# 查看响应内容,response.text 返回的是Unicode格式的数据
print(response.text)
# 查看响应码
print(response.status_code)
if __name__ == ‘__main__‘:
unittest.main(verbosity=2)
运行结果:
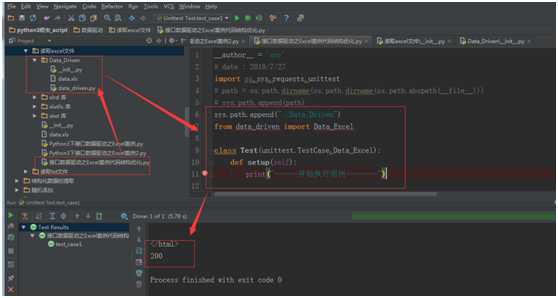
假设路径结构为:
project
?mode
??count.py
??data.py
?test.py
count.py文件里有A类,data.py里有B类,现在想要在test.py中调用count.py和data.py里的方法 。
方法一:
import sys
sys.path.append(“./mode”)
from count import A
from data import B
之后在test.py中直接使用 类名(),方法名() 。
方法二:(推荐)
在 mode 中新建 init.py,内容为空 。
之后在test.py中 。
from model.count import A
from model.new_count import B
之后在test.py中直接使用 类名(),方法名() 。
方法三:
在 model中新建 init.py,内容为 :
from count import A
from new_count import B
之后在test.py中 。
import mode
调用时,mode.类名(),mode.方法名() 。
或
from model import *
调用时,直接使用 类名(),方法名()。
标签:行修改 val headers result 设置 secure pre 响应 userinfo
原文地址:https://www.cnblogs.com/tinghai8/p/9459192.html