标签:读取数据 好处 ret mod 练习 environ 存储 rem 删除
time模块:
时间戳:表示的是从1970年1月1日00:00:00开始按秒计算的偏移量,返回类型为float类型
格式化时间字符串(Format String)
结构化的时间(struct_time):struct_time元组共有9个元素(年月日时分秒,一年中的第几周,一年中的第几天,夏令时)

# print(time.time())#1533962144.060534 # print(time.localtime())#time.struct_time(tm_year=2018, tm_mon=8, tm_mday=11, tm_hour=12, tm_min=36, tm_sec=4, tm_wday=5, tm_yday=223, tm_isdst=0) # print(time.localtime(1533962144.060534))#time.struct_time(tm_year=2018, tm_mon=8, tm_mday=11, tm_hour=12, tm_min=35, tm_sec=44, tm_wday=5, tm_yday=223, tm_isdst=0) # print(time.gmtime()) # UTC时区的struct_time # print(time.strftime("%Y-%m-%d %X"))#2018-08-11 12:37:32 把一个代表时间的元组或者struct_time转化为格式化的时间字符串 # print(time.strftime("%Y-%m-%d %H:%M:%S"))#2018-08-11 12:54:11 # print(time.strptime(‘2012-10-10‘,‘%Y-%m-%d‘))把格式化时间转换为结构化 # mktime(t) : 将一个struct_time结构化时间转化为时间戳。 # print(time.mktime(time.localtime()))#1533962846.0 #格林威治时间 #asctime([t]) : 把一个表示时间的元组或者struct_time表示为这种形式:‘Sun Jun 20 23:21:05 1993‘ # print(time.ctime())#Sat Aug 11 12:50:17 2018 把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式
datetime模块:
包含如下类:
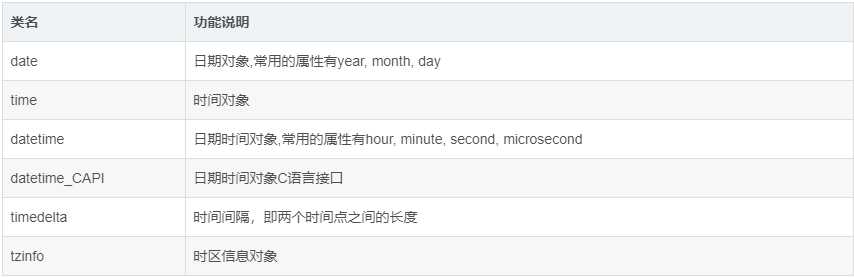
# datetime模块 import datetime print(datetime.datetime.now())#2018-08-11 13:08:02.573983 # print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天 # print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天 # print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时 # print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分 print (datetime.datetime.now() + datetime.timedelta(days=30,hours=1,minutes=1,seconds=1)) # 替换时间:replace 可替换某个时间的值 res = datetime.datetime.now() res = res.replace(year=1997) print(res)
# print(random.random())# 用于产生一个 0<=x<1 之间的随机浮点数 开闭 # print(random.randint(1,8))# random.randint(a, b),用于生成一个指定范围内的整数 开开 # print(random.randrange(1,8,3))# random.randrange([start], stop[, step]) # print(random.choice([1,2,32,3,2,"哈哈"]))#random.choice(sequence)从中选一个 # print(random.sample([1,2,32,3,2,"哈哈"],2)) #random.sample(sequence, k),从指定序列中随机获取指定长度的片断。sample函数不会修改原有序列 # res = [1,2,32,3,2,"哈哈"] # random.shuffle(res) #打乱原有列表中的元素 # print(res)
#注 :sequence在python不是一种特定的类型,而是泛指一系列的类型。list, tuple, 字符串都属于sequence
用来处理Python运行时配置以及资源,从而可以与前当程序之外的系统环境交互,如:Python解释器。
import sys print(sys.argv)#[‘D:/练习/时间至json模块/时间模块.py‘] print(sys.version)#3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)] print(sys.maxsize)#最大的int值 print(sys.path)#返回模块的搜索路径 print(sys.platform)#返回操作系统平台名称 # sys.exit() #(0是正常退出,其他为异常)
注:如果python中导入的package或module不在环境变量PATH中,那么可以使用sys.path将要导入的package或module加入到PATH环境变量中。
实现模拟进度条:
""" 当程序要进行耗时操作时例如 读写 网络传输 需要给用户提示一个进度信息 "[********* ]" "[********* ]" "[************ ]" "[****************]" """ # print("[* ]") # print("[** ]") print("[%-10s]" % ("*" * 1)) print("[%-10s]" % ("*" * 2)) print("[%-10s]" % ("*" * 3)) print("[%-10s]" % ("*" * 4)) # 比例 0 - 1 0.5 def progress(percent,width=30): percent = percent if percent <= 1 else 1 text = ("\r[%%-%ds]" % width) % ("*" * int((width * percent))) text = text + "%d%%" text = text % (percent * 100) print( text , end="") # 模拟下载 # 文件大小 import time file_size = 10240 # 已经下载大小 cur_size = 0 while True: time.sleep(0.5) cur_size += 1021 progress(cur_size / file_size) if cur_size >= file_size: print() print("finish") break
import os print(os.getcwd())#获取当前?工作?目录,即当前python脚本?工作的?目录路路径 os.chdir(‘dirname‘)# 改变当前脚本?工作?目录;相当于shell下cd print(os.curdir)#返回当前?目录,就是一个‘.‘ os.pardir 获取当前?目录的?父?目录字符串串名:(‘..‘) os.makedirs(‘dirname1/dirname2‘)#生成多层递归目录 os.removedirs(‘dirname1‘)#若?目录为空,则删除,并递归到上?一级?目录 os.mkdir(‘dirname‘)#?生成单级?目录;相当于shell中mkdir dirname os.rmdir(‘dirname‘) #删除单级空?目录,若?目录不不为空则?无法删除,报错;相 当于shell中rmdir dirname print(os.listdir(‘dirname‘))#列列出指定?目录下的所有?文件和?子?目录,包括隐藏?文件, 并以列列表?方式打印 os.remove(‘1.py‘) #删除?一个?文件 os.rename("oldname","newname") 重命名?文件/?目录 os.stat(‘path/filename‘) 获取?文件/?目录信息 print(os.stat(‘D:\练习\时间至json模块\时间模块.py‘)) print(os.name ) #输出字符串串指示当前使?用平台。win->‘nt‘; Linux->‘posix‘ print(os.sep) #输出操作系统特定的路路径分隔符,win下为"\",Linux下为"/" os.linesep #输出当前平台使?用的?行行终?止符,win下为"\t\n",Linux下为"\n" print(os.pathsep)#输出?用于分割?文件路路径的字符串串 win下为;,Linux下为: os.system("bash command")# 运?行行shell命令,直接显示 print(os.environ) #获取系统(计算机)环境变量量 os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 os.path.getsize(path) 返回path的大小
该模块拥有许多文件、文件夹、压缩包等处理功能
import shutil # shutil.copyfileobj(open(‘old.xml‘,‘r‘), open(‘new.xml‘, ‘w‘)) # shutil.copyfileobj(fsrc, fdst[, length])(copyfileobj方法只会拷贝文件内容)将文件内容拷贝到另一个文件中 # shutil.copyfile(‘f1.log‘, ‘f2.log‘)(copyfile只拷贝文件内容) # shutil.copy(‘f1.log‘, ‘f2.log‘) 拷贝文件和权限 # shutil.copystat (src, dst) 拷?贝?文件状态信息 后访问 后修改 权限 提供两 个?文件路路径 # shutil.move (src, dst) 移动?目录和?文件 # shutil.ignore_patterns(*patterns)忽略指定的文件。通常配合下面的copytree()方法使用。 # shutil.copytree (src, dst, symlinks=False, ignore=None) 拷?贝?目录 # symlinks:指定是否复制软链接。小心陷入死循环。 # ignore:指定不参与复制的文件,其值应该是一个ignore_patterns()方法。 # copy_function:指定复制的模式 # shutil.rmtree 删除?目录 可以设置忽略略?文件
压缩与解压缩:
shutil 可以打包 但是?无法解包 并且打包也是调?用tarfile 和 zipFile完成 ,解压需要按照格式调?用对应的模块
打包:
import shutil
#将
/Users/jerry/PycharmProjects/package/packa ge1下的文件打包放置 /test/目录
shutil.make_archive("test","tar","/Users/jerry/PycharmProjects/package/packa ge1")
ZipFile和TarFile
import zipfile # 压缩 z = zipfile.ZipFile(‘zfj.zip‘, ‘w‘) z.write(‘a.log‘) z.write(‘data.data‘) z.close() # 解压 z = zipfile.ZipFile(‘laxi.zip‘, ‘r‘) z.extractall() z.close()
import tarfile # 压缩 tar = tarfile.open(‘your.tar‘,‘w‘) tar.add(‘/Users/wupeiqi/PycharmProjects/bbs2.log‘, arcname=‘bbs2.log‘) tar.add(‘/Users/wupeiqi/PycharmProjects/cmdb.log‘, arcname=‘cmdb.log‘) tar.close() # 解压 tar = tarfile.open(‘your.tar‘,‘r‘) tar.extractall() # 可设置解压地址 tar.close()
注:zipfile压缩不会保留文件状态信息,tarfile会保留
1.序列化:把对象(变量)从内存中变成可存储或传输的过程称之为序列化.反之则称之为反序列化
2.序列化的好处
1.数据持久保存
2.跨平台数据交互
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式
encoding(序列化):把python对象转换成json字符串
decoding(反序列化):把json字符串转换成python对象import json
# dumps把特定的对象序列化处理为字符串,外形和原来的长的一样,如果直接将dict类型的数据写入json文件中会发生报错 # dic = {"name":‘zfj‘,"age" : 18} # dic1 = json.dumps(dic) # print(type(dic))#<class ‘dict‘> # print(dic1)# {"name": "zfj", "age": 18} # rdic = json.loads(dic1)#反序列化 # print(rdic) name_emb = {‘a‘: ‘1111‘, ‘b‘: ‘2222‘, ‘c‘: ‘3333‘, ‘d‘: ‘4444‘} # 数据转成str,并写入到json文件中 json.dump(name_emb, open(‘db.json‘, "a")) # 注:json.load() 用于从json文件中读取数据
jsObj = json.load(open(‘db.json‘)) print(jsObj) print(type(jsObj))
与json模块不同的是pickle模块序列化和反序列化的过程叫:pickling和unpickling
pickling:将python对象转换为字节流的过程
unpickling:将字节流二进制文件或字节对象转换成python对象的过程
import pickle dic = {"name":‘zfj‘,"age" : 18} # dumps&loads # 序列化 # dic1 = pickle.dumps(dic) # print(dic1)#b‘\x80\x03}q\x00(X\x04\x00\x00\x00nameq\x01X\x03\x00\x00\x00zfjq\x02X\x03\x00\x00\x00ageq\x03K\x12u.‘ # print(type(dic1))#<class ‘bytes‘> #反序列化 # rdic = pickle.loads(dic1) # print(rdic)#{‘name‘: ‘zfj‘, ‘age‘: 18} # dump&load # 序列化 with open(‘pickle.txt‘, ‘wb‘) as f: pickle.dump(dic, f) # 反序列化 with open(‘pickle.txt‘, ‘rb‘) as f: rdic = pickle.load(f) print(rdic)
总结:
json是可以在不同语言之间交换数据的,而pickle只在python之间使用。
json只能序列化最基本的数据类型,而pickle可以序列化所有的数据类型,包括类,函数都可以序列化。
python-时间模块,random、os、sys、shutil、json和pickle模块
标签:读取数据 好处 ret mod 练习 environ 存储 rem 删除
原文地址:https://www.cnblogs.com/mangM/p/9460502.html
