标签:eth unit air 归一化 进一步 span 计算 地方 ever
一、ID3决策树概述
ID3决策树是另一种非常重要的用来处理分类问题的结构,它形似一个嵌套N层的IF…ELSE结构,但是它的判断标准不再是一个关系表达式,而是对应的模块的信息增益。它通过信息增益的大小,从根节点开始,选择一个分支,如同进入一个IF结构的statement,通过属性值的取值不同进入新的IF结构的statement,直到到达叶子节点,找到它所属的“分类”标签。
它的流程图是一课无法保证平衡的多叉树,每一个父节点都是一个判断模块,通过判断,当前的向量会进入它的某一个子节点中,这个子节点是判断模块或者终止模块(叶子节点),当且仅当这个向量到达叶子节点,它也就找到了它的“分类”标签。
ID3决策树和KNN的区别不同,它通过一个固定的训练集是可以形成一颗永久的“树”的,这课树可以进行保存并且运用到不同的测试集中,唯一的要求就是测试集和训练集需要是结构等价的。这个训练过程就是根据训练集创建规则的过程,这也是机器学习的过程。
ID3决策树的一个巨大缺陷是:它将产生过度匹配问题。这里在不讨论信息增益的前提下,有这样一个例子:人的属性中有性别和年龄两个属性,由于人的性别只有男和女两种,年龄有很多种分支,当它有超过两个分支的时候,在用信息增益选择新的属性的时候,会选择年龄而不是性别,因为ID3决策树在使用信息增益来划分数据集的时候会倾向于选择属性分支更多的一个;另外一个缺陷是,人的年龄假定为1~100,如果不进行离散化,即区间的划分,那么在选择年龄这个属性的时候,这棵决策树会产生最多100个分支,这是非常可怕而且浪费空间和效率的,考虑这 样一种情况:两个人的其他所有属性完全相同,他们的分类都是"A",然而在年龄这一个树节点中分支了,而这个年龄下有一个跟这两个人很像,却不属于“A”类别的人,由于ID3决策树无法处理连续性数据,那么这两个人很有可能被划分到两个分类中,这是不合理的,这也是下一节的C4.5决策树考虑的问题。
前面提到了信息增益,这是ID3决策树划分数据集的根本。这里在理论上解释一下信息增益和香农熵,下面会在训练算法的时候,通过算法和数据来解释信息增益和香农熵。
首先解释一个熵的概念:熵指的是一个系统“内在的混乱程度”,在这里也就是代表信息的“有序程度”。熵增的方向就是信息混乱度越大的方向,熵减的方向就是信息趋于“有序”的方向,所以说我们要划分数据集来使得数据集局部愈发趋于“有序化”。之所以是说数据集局部,是因为ID3在进行数据集划分的时候,选择一个使信息增益最大,即熵减最多的特征进行划分,而后该属性在后续的划分中将不再被考虑,所以这是一个递归的过程,也是一个不断局部化数据集的过程。
信息增益(Information Gain):对于某一种划分的信息增益可以表示为“期望信息 - 该种划分的香农熵”。它的公式可以表示为:IG(T)=H(C)-H(C|T)。其中C代表的是分类或者聚类C,T代表的是则是当前选择进行划分的特征。这条公式表示了:选择特征T进行划分,则其信息增益为数据集的期望信息减去选择该特征T进行划分后的期望信息。这里要明确的是:期望信息就是香农熵。熵是信息的期望,所以熵的表示应该为所有信息出现的概率和其期望的总和,即:
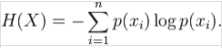
当我们把这条熵公式转换为一个函数:calculateEntropy(dataSet,feature = NULL)的时候,上面这个计算过程可以变成以下的伪代码:
1 while dataSet != NULL: 2 feat = -1 3 for i in range(featureNum): 4 IG = calculateEntropy(dataSet) - calculateEntropy(dataSet,feature[i]) 5 if IG > IGMAX: 6 IGMAX = IG 7 feat = feature[i] 8 #IGMAX此时保存的即为最大的信息增益,feat保存的即为最大的信息增益所对应的特征 9 dataSet = dataSet - feature[i]#这里不是减法,而是在数据集中去除该列
由上面的伪代码,也可以理解到“信息增益最大的时候,熵减最多”。这里的数学理解就是:信息增益的公式可以看作A - B,其中B是改变的,A是一个常量,那么B越小A - B的值就会越大,B越小则代表熵越小,当B达到最小的时候,A - B最大,此时熵最小,也即是熵减最多。
二、准备数据集
Python3实现机器学习经典算法的数据集都采用了著名的机器学习仓库UCI(http://archive.ics.uci.edu/ml/datasets.html),其中分类系列算法采用的是Adult数据集(http://archive.ics.uci.edu/ml/datasets/Adult),测试数据所在网址:http://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data,训练数据所在网址:http://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.test。
Adult数据集通过收集14个特征来判断一个人的收入是否超过50K,14个特征及其取值分别是:
age: continuous.
workclass: Private, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov, Without-pay, Never-worked.
fnlwgt: continuous.
education: Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc-acdm, Assoc-voc, 9th, 7th-8th, 12th, Masters, 1st-4th, 10th, Doctorate, 5th-6th, Preschool.
education-num: continuous.
marital-status: Married-civ-spouse, Divorced, Never-married, Separated, Widowed, Married-spouse-absent, Married-AF-spouse.
occupation: Tech-support, Craft-repair, Other-service, Sales, Exec-managerial, Prof-specialty, Handlers-cleaners, Machine-op-inspct, Adm-clerical, Farming-fishing, Transport-moving, Priv-house-serv, Protective-serv, Armed-Forces.
relationship: Wife, Own-child, Husband, Not-in-family, Other-relative, Unmarried.
race: White, Asian-Pac-Islander, Amer-Indian-Eskimo, Other, Black.
sex: Female, Male.
capital-gain: continuous.
capital-loss: continuous.
hours-per-week: continuous.
native-country: United-States, Cambodia, England, Puerto-Rico, Canada, Germany, Outlying-US(Guam-USVI-etc), India, Japan, Greece, South, China, Cuba, Iran, Honduras, Philippines, Italy, Poland, Jamaica, Vietnam, Mexico, Portugal, Ireland, France, Dominican-Republic, Laos, Ecuador, Taiwan, Haiti, Columbia, Hungary, Guatemala, Nicaragua, Scotland, Thailand, Yugoslavia, El-Salvador, Trinadad&Tobago, Peru, Hong, Holand-Netherlands.
最终的分类标签有两个:>50K, <=50K.
下一步是分析数据:
1、数据预处理:
上面提到了,ID3是无法处理连续型数据的,所以连续型数据应该在数据预处理这一步进行清理,处理方法有两种:
1、直接清洗掉:这也是所采用的方法,因为转换离散数据的前提是,对于连续型数据的划分要足够好,比如年龄、身高等的划分,5划分和10划分之间的差距是非常大的,不管哪一种划分都会破坏数据原本的结构,所以这里采用的是直接清洗掉数据的方法,对于连续数据的使用延迟到C4.5和CART的实现中:
1 def precondition(mydate):#清洗连续型数据 2 #continuous:0,2,4,10,11,12 3 for each in mydate: 4 del(each[0]) 5 del(each[1]) 6 del(each[2]) 7 del(each[7]) 8 del(each[7]) 9 del(each[7])
这里要注意在Python中用del清洗数据的时候,某一个数据被del了,它的索引为i,那么del执行完成后 i+1 的值的索引会变为i,如上所示连续型数据所在的列为0,2,4,10,11,12,但是需要清除的列应该是0,1,2,7,7,7。
2、将连续型数据转换为离散数据:
这里的实现方法可以根据自己的划分构造一个和KNN一样的字典,然后扫描一次数据集,将数据集中的连续数据转换为离散的数据。
2、数据清洗:
数据中含有大量的不确定数据,这些数据在数据集中已经被转换为‘?’,但是它仍旧是无法使用的,数据挖掘对于这类数据进行数据清洗的要求规定,如果是可推算数据,应该推算后填入;或者应该通过数据处理填入一个平滑的值,然而这里的数据大部分没有相关性,所以无法推算出一个合理的平滑值;所以所有的‘?’数据都应该被剔除而不应该继续使用。为此我们要用一段代码来进行数据的清洗:
1 def cleanOutData(dataSet):#数据清洗 2 for row in dataSet: 3 for column in row: 4 if column == ‘?‘ or column==‘‘: 5 dataSet.remove(row)
这段代码只是示例,它有它不能处理的数据集!比如上述这段代码是无法处理相邻两个向量都存在‘?’的情况的!修改思路有多种,一种是循环上述代码N次直到没有‘?‘的情况,这种算法简单易实现,只是给上述代码加了一层循环,然而其复杂度为O(N*len(dataset));另外一种实现是每次找到存在‘?‘的列,回退迭代器一个距离,大致的伪代码为:
1 def cleanOutData(dataSet): 2 for i in range(len(dataSet)): 3 if dataSet[i].contain(‘?‘): 4 dataSet.remove(dataSet[i]) ( dataSet.drop(i) ) 5 i-=1
上述代码的复杂度为O(n)非常快速,但是这种修改迭代器的方式会引起编译器的报错,对于这种报错可以选择修改编译器使其忽略,但是不建议使用这种回退迭代器的写法。
3、数据归一化:
决策树这样的概念模型不需要进行数据归一化,因为它关心的是向量的分布情况和向量之间的条件概率而不是变量的值,进行数据归一化更难以进行划分数据集,因为Double类型的判等非常难做且不准确。
4、数据集读入:
综合上诉的预处理和数据清洗的过程,数据集读入的过程为:
1 def createDateset(filename): 2 with open(filename, ‘r‘)as csvfile: 3 dataset= [line.strip().split(‘, ‘) for line in csvfile.readlines()] #读取文件中的每一行 4 dataset=[[int(i) if i.isdigit() else i for i in row] for row in dataset] #对于每一行中的每一个元素,将行列式数字化并且去除空白保证匹配的正确完成 5 cleanoutdata(dataset) #清洗数据 6 del (dataset[-1]) #去除最后一行的空行 7 precondition(dataset) #预处理数据 8 labels=[‘workclass‘,‘education‘, 9 ‘marital-status‘,‘occupation‘, 10 ‘relationship‘,‘race‘,‘sex‘, 11 ‘native-country‘] 12 return dataset,labels 13 14 def cleanoutdata(dataset):#数据清洗 15 for row in dataset: 16 for column in row: 17 if column == ‘?‘ or column==‘‘: 18 dataset.remove(row) 19 break 20 21 def precondition(mydate):#清洗连续型数据 22 #continuous:0,2,4,10,11,12 23 for each in mydate: 24 del(each[0]) 25 del(each[1]) 26 del(each[2]) 27 del(each[7]) 28 del(each[7]) 29 del(each[7])
这里是先进行预处理还是先进行数据清洗取决于所使用的数据集中,连续型数据和脏数据哪种更多,先处理更少的那一种能有效地减少处理量。
三、训练算法
训练算法既是构造ID3决策树的过程,构造的原则为:如果某个树分支下的数据全部属于同一类型,则已经正确的为该分支以下的所有数据划分分类,无需进一步对数据集进行分割,如果数据集内的数据不属于同一类型,则需要继续划分数据子集,该数据子集划分后作为一个分支继续进行当前的判断。
用伪代码表示如下:
if 数据集中所有的向量属于同一分类:
return 分类标签
else:
if 属性特征已经使用完:
进行投票决策
return 票数最多的分类标签
else:
寻找信息增益最大的数据集划分方式(找到要分割的属性特征T)
根据属性特征T创建分支
for 属性特征T的每个取值
成为当前树分支的子树
划分数据集(将T属性特征的列丢弃或屏蔽)
return 分支(新的数据集,递归)
根据上面的伪代码,就可以一步一步地完善代码:
1、寻找信息增益最大的数据集划分方式(找到要分割的属性特征T):
1 #计算香农熵/期望信息 2 def calculateEntropy(dataSet): 3 ClassifyCount = {}#分类标签统计字典,用来统计每个分类标签的概率 4 for vector in dataSet: 5 clasification = vector[-1] #获取分类 6 if not clasification not in ClassifyCount.keys():#如果分类暂时不在字典中,在字典中添加对应的值对 7 ClassifyCount[clasification] = 0 8 else: 9 ClassifyCount[clasification] += 1 #计算出现次数 10 shannonEntropy=0.0 11 for key in ClassifyCount: 12 probability=float(ClassifyCount[key]) / dataSet.shape[0] #计算概率 13 shannonEntropy -= probability * log(probability,2) #香农熵的每一个子项都是负的 14 return shannonEntropy 15 16 #选择最好的数据集划分方式 17 def chooseBestSplitWay(dataSet): 18 HC = calculateEntropy(dataSet)#计算整个数据集的香农熵(期望信息),即H(C),用来和每个feature的香农熵进行比较 19 bestfeatureIndex = -1 #最好的划分方式的索引值,因为0也是索引值,所以应该设置为负数 20 gain=0.0 #信息增益=期望信息-熵,gain为最好的信息增益,IG为各种划分方式的信息增益 21 for feature in range(len(dataSet[0]) -1 ): #计算feature的个数,由于dataset中是包含有类别的,所以要减去类别 22 featureListOfValue=[vector[feature] for vector in dataSet] #对于dataset中每一个feature,创建单独的列表list保存其取值,其中是不重复的 23 addFeatureValue(featureListOfValue,feature) #增加在训练集中有,测试集中没有的属性特征的取值 24 unique=set(featureListOfValue) 25 HTC=0.0 #保存HTC,即H(T|C) 26 for value in unique: 27 subDataSet = splitDataset(dataSet,feature,value) #划分数据集 28 probability = len(subDataSet) / float(len(dataSet)) #求得当前类别的概率 29 HTC += probability * calculateEntropy(subDataSet) #计算当前类别的香农熵,并和HTC想加,即H(T|C) = H(T1|C)+ H(T2|C) + … + H(TN|C) 30 IG=HC-HTC #计算对于该种划分方式的信息增益 31 if(IG > gain): 32 gain = IG 33 bestfeatureIndex = feature 34 return bestfeatureIndex 35 36 37 def addFeatureValue(featureListOfValue,feature): 38 for featureValue in feat[feature]: #feat保存的是所有属性特征的所有可能的取值,其结构为feat = [ [val1,val2,val3,…,valn], [], [], [], … ,[] ] 39 featureListOfValue.append(featureValue)
这里需要解释的地方有几个:
1)信息增益的计算:
经过前面对信息增益的计算,来到这里应该很容易能看得懂这段代码了。IG表示的是对于某一种划分方式的信息增益,由上面公式可知:IG = HC - HTC,HC和HTC的计算基于相同的函数calculateEntropy(),唯一不同的是,HC的计算相对简单,因为它是针对整个数据集(子集)的;HTC的计算则相对复杂,由条件概率得知HTC可以这样计算:
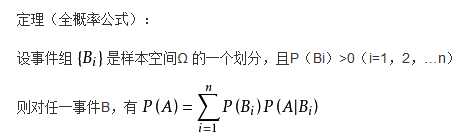
所以我们可以反复调用calculateEntropy()函数,然后对于每一次计算结果进行累加,这就可以得到HTC。
2)addFeatureValue()函数
增加这一个函数的主要原因是:在测试集中可能出现训练集中没有的特征的取值的情况,这在我所使用的adlut数据集中是存在的。庆幸的是,adult数据集官方给出了每种属性特征可能出现的所有的取值,这就创造了解决这个机会的条件。如上所示,在第二部分准备数据集中,每个属性特征的取值已经给出,那我们就可以在创建保存某一属性特征的所有不重复取值的时候加上没有存在的,但是可能出现在测试集中的取值。这就是addFeatureValue()的功用了。
2、划分数据集
其实在上一步就已经使用到了划分数据集了,它没有像我上面给到的流程那样,在创建子树后才划分数据集,而是先进行划分,然后再进行创建子树,原因在于划分数据集后计算信息增益会变的更加通用,可以仅仅使用calculateEntropy()这个函数,而不需要在calculateEntropy()函数的前面增加一个划分条件,所以我们应该将“划分数据集”提前到“寻找最好的属性特征之后”立刻进行:
1 #划分数据集 2 def splitDataSet(dataSet,featureIndex,value): 3 newDataSet=[] 4 for vec in dataSet: #将选定的feature的列从数据集中去除 5 if vec[featureIndex] == value: 6 rest = vec[:featureIndex] 7 rest.extend(vec[featureIndex + 1:]) 8 newDataSet.append(rest) 9 return newDataSet
划分数据集的方式就是将0~传入的featureIndex的所有的列复制到新的rest列表中,然后跳过这一列,从下一列开始到最后一列extend到列表的末尾中,然后再将这个rest列表作为新的数据集传回。
3、投票表决:
增加投票表决这个过程主要是因为:创建分支的过程就是创建树的过程,而这个过程无论是原始数据集,还是数据集的子集,都应该是基于相同的依据来进行创建的,所以这里采用的递归的方式来创建树,这就存在一个递归的结束条件。这个算法的递归结束条件应该是:使用完所有的数据集的属性,并且已经根据所有的属性的取值构建了其所有的子树,所有的子树下都达到所有的分类。但是存在这样一种情况:已经处理了数据集的所有属性特征,但是分类标签并不是唯一的,比如孪生兄弟性格不一样,他们的所有属性特征可能相同,可是分类标签并不一样,这就需要一个算法来保证在这里能得到一个表决结果,它代表了依据这些属性特征,所能达到的分类结果中,“最有可能”出现的一个,所以采用的是投票表决的算法:
1 #返回出现次数最多的类别,避免产生所有特征全部用完无法判断类别的情况 2 def majority(classList): 3 classificationCount = {} 4 for i in classList: 5 if not i in classificationCount.keys(): 6 classificationCount[i] = 0 7 else: 8 classificationCount[i] += 1 9 sortedClassification = sorted(dict2list(classificationCount),key = operator.itemgetter(1),reverse = True) 10 return sortedClassification[0][0]
这里唯一需要注意的是排序过程:因为dict无法进行排序,所以代码dict应该转换为list来进行排序:
1 #dict字典转换为list列表 2 def dict2list(dic:dict): 3 keys = dic.keys() 4 values = dic.values() 5 lst = [(key,value)for key,value in zip(keys,values)] 6 return lst
4、树创建:
树创建的过程就是将上面的局部串接成为整体的过程,它也是上面的创建分支过程的实现:
1 #创建树 2 def createTree(dataSet,labels): 3 classificationList = [feature[-1] for feature in dataSet] #产生数据集中的分类列表,保存的是每一行的分类 4 if classificationList.count(classificationList[0]) == len(classificationList): #如果分类别表中的所有分类都是一样的,则直接返回当前的分类 5 return classificationList[0] 6 if len(dataSet[0]) == 1: #如果划分数据集已经到了无法继续划分的程度,即已经使用完了全部的feature,则进行决策 7 return majority(classificationList) 8 bestFeature = chooseBestSplitWay(dataSet) #计算香农熵和信息增益来返回最佳的划分方案,bestFeature保存最佳的划分的feature的索引 9 bestFeatureLabel = labels[bestFeature] #取出上述的bestfeature的具体值 10 Tree = {bestFeatureLabel:{}} 11 del(labels[bestFeature]) #删除当前进行划分是使用的feature避免下次继续使用到这个feature来划分 12 featureValueList = [feature[bestFeature]for feature in dataSet] #对于上述取出的bestFeature,取出数据集中属于当前feature的列的所有的值 13 uniqueValue = set(featureValueList) #去重 14 for value in uniqueValue: #对于每一个feature标签的value值,进行递归构造决策树 15 subLabels = labels[:] 16 Tree[bestFeatureLabel][value] = createTree(splitDataSet(dataSet,bestFeature,value),subLabels) 17 return Tree
算法同我上面所写出来的流程一样,先进行两次判断:
1)是否余下所有的取值都是同类?
2)是否已经用完了所有的属性特征?
这两个判断都是终结这个递归算法的根本。而后就是取得对于“原始数据集”的最佳分割方案,然后对于这个分割方案,构建出分支,把这个方案所得到的bestFeature的所有可能的取值构建新的下属分支即子树,自此,“原始数据集”的操作就结束了,下面都是对于这个数据集进行一次或多次划分的子集的分支构建方案了。而在进行递归调用创建子树的时候,传入的labels应该是已经复制过的labels,否则,由于Python不是值传递而是引用传递的原因,在子树创建中将影响到父节点的labels。
自此,我们的ID3决策树就已经构建完成,现在我们完全可以得到一棵独立的决策树,它是离线的。看看我们的树长什么样:

这只是一部分……事实上,运行完成这棵树的耗时非常长,因为数据集非常大,在没有使用分布式的计算的前提下,我们最好要把这棵树保存在本地上,然后下次进行测试算法的时候读取离线的树,而不是再次生成,《机器学习实战》中给我们提供了这样一种保存树的方式:
5、保存树(读取树):
1 def storetree(inputree,filename): 2 fw = open(filename, ‘wb‘) 3 pickle.dump(inputree, fw) 4 fw.close() 5 6 def grabTree(filename): 7 fr = open(filename, ‘rb‘) 8 return pickle.load(fr)
它借用pickle模块来直接将树保存下来,但是这个保存下来的树不是可视化的。
四、测试算法
树已经构造完成了,下一步就是使用这棵树的过程了,这也是测试算法的过程。我们的树是一个字典,所以我们测试算法的过程应该是循着这个字典查值的过程:
1、预处理、清洗测试集
预处理和清洗过程和上面对训练集的过程是一样的。
2、测试过程
测试过程需要一个classify()函数和一个count()函数。classify()函数负责将上面构造树的代码所构造出来的树接受,并且根据传入的向量进行分类,然后返回预测的分类标签,count()函数负责计算这个数据集的正确率:
1 #测试算法 2 def classify(inputTree,featLabels,testVector): 3 root = list(inputTree.keys())[0] #取出树的第一个标签,即树的根节点 4 dictionary = inputTree[root] #取出树的第一个标签下的字典 5 featIndex = featLabels.index(root) 6 for key in dictionary.keys(): #对于这个字典 7 if testVector[featIndex] == key: 8 if type(dictionary[key]).__name__ == ‘dict‘: #如果还有一个新的字典 9 classLabel = classify(dictionary[key],featLabels,testVector) #递归向下寻找到非字典的情况,此时是叶子节点,叶子节点保存的肯定是类别 10 else: 11 classLabel=dictionary[key] #叶子节点,返回类别 12 return classLabel 13 14 def test(myTree,labels,filename,sum,correct,error): 15 for line in dataSet: 16 result=classify(myTree,labels,line)+‘.‘ 17 if result==line[8]: #如果测试结果和类别相同 18 correct = correct + 1 19 else : 20 error = error + 1 21 print("准确率:%f"% correct / sum ) 22 return sum,correct,error
由于构建树的时候,我们采用的是字典包含字典的过程,所以当我们找到一个字典的键(Key),可以直接判断它的值(Value)是否仍旧是一个字典,如果是,则说明它下面还有分支,还有子树,否则说明这已经到达了叶子节点,可直接获取到分类标签。这个classify()也是一个递归向下查找的过程,它通过第一个参数,将树不断地进行剪枝,最后达到只剩下一个叶子节点的目的。
看看结果 :

跟官方的数据进行对比(官方的是错误率):
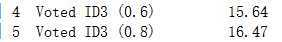
五、完整代码
1 #encoding=utf-8 2 from math import log 3 import operator 4 import pickle 5 6 #读取数据集 7 def createDateset(filename): 8 with open(filename, ‘r‘)as csvfile: 9 dataset= [line.strip().split(‘, ‘) for line in csvfile.readlines()] #读取文件中的每一行 10 dataset=[[int(i) if i.isdigit() else i for i in row] for row in dataset] #对于每一行中的每一个元素,将行列式数字化并且去除空白保证匹配的正确完成 11 cleanoutdata(dataset) #清洗数据 12 del (dataset[-1]) #去除最后一行的空行 13 precondition(dataset) #预处理数据 14 labels=[‘workclass‘,‘education‘, 15 ‘marital-status‘,‘occupation‘, 16 ‘relationship‘,‘race‘,‘sex‘, 17 ‘native-country‘] 18 return dataset,labels 19 20 def cleanoutdata(dataset):#数据清洗 21 for row in dataset: 22 for column in row: 23 if column == ‘?‘ or column==‘‘: 24 dataset.remove(row) 25 break 26 27 #计算香农熵/期望信息 28 def calculateEntropy(dataSet): 29 ClassifyCount = {}#分类标签统计字典,用来统计每个分类标签的概率 30 for vector in dataSet: 31 clasification = vector[-1] #获取分类 32 if not clasification not in ClassifyCount.keys():#如果分类暂时不在字典中,在字典中添加对应的值对 33 ClassifyCount[clasification] = 0 34 else: 35 ClassifyCount[clasification] += 1 #计算出现次数 36 shannonEntropy=0.0 37 for key in ClassifyCount: 38 probability=float(ClassifyCount[key]) / dataSet.shape[0] #计算概率 39 shannonEntropy -= probability * log(probability,2) #香农熵的每一个子项都是负的 40 return shannonEntropy 41 42 # def addFetureValue(feature): 43 44 #划分数据集 45 def splitDataSet(dataSet,featureIndex,value): 46 newDataSet=[] 47 for vec in dataSet:#将选定的feature的列从数据集中去除 48 if vec[featureIndex] == value: 49 rest = vec[:featureIndex] 50 rest.extend(vec[featureIndex + 1:]) 51 newDataSet.append(rest) 52 return newDataSet 53 54 55 def addFeatureValue(featureListOfValue,feature): 56 feat = [[ ‘Private‘, ‘Self-emp-not-inc‘, ‘Self-emp-inc‘, 57 ‘Federal-gov‘, ‘Local-gov‘, ‘State-gov‘, ‘Without-pay‘, ‘Never-worked‘], 58 [],[],[],[],[]] 59 for featureValue in feat[feature]: #feat保存的是所有属性特征的所有可能的取值,其结构为feat = [ [val1,val2,val3,…,valn], [], [], [], … ,[] ] 60 featureListOfValue.append(featureValue) 61 62 #选择最好的数据集划分方式 63 def chooseBestSplitWay(dataSet): 64 HC = calculateEntropy(dataSet)#计算整个数据集的香农熵(期望信息),即H(C),用来和每个feature的香农熵进行比较 65 bestfeatureIndex = -1 #最好的划分方式的索引值,因为0也是索引值,所以应该设置为负数 66 gain=0.0 #信息增益=期望信息-熵,gain为最好的信息增益,IG为各种划分方式的信息增益 67 for feature in range(len(dataSet[0]) -1 ): #计算feature的个数,由于dataset中是包含有类别的,所以要减去类别 68 featureListOfValue=[vector[feature] for vector in dataSet] #对于dataset中每一个feature,创建单独的列表list保存其取值,其中是不重复的 69 addFeatureValue(featureListOfValue,feature) #增加在训练集中有,测试集中没有的属性特征的取值 70 unique=set(featureListOfValue) 71 HTC=0.0 #保存HTC,即H(T|C) 72 for value in unique: 73 subDataSet = splitDataSet(dataSet,feature,value) #划分数据集 74 probability = len(subDataSet) / float(len(dataSet)) #求得当前类别的概率 75 HTC += probability * calculateEntropy(subDataSet) #计算当前类别的香农熵,并和HTC想加,即H(T|C) = H(T1|C)+ H(T2|C) + … + H(TN|C) 76 IG=HC-HTC #计算对于该种划分方式的信息增益 77 if(IG > gain): 78 gain = IG 79 bestfeatureIndex = feature 80 return bestfeatureIndex 81 82 #返回出现次数最多的类别,避免产生所有特征全部用完无法判断类别的情况 83 def majority(classList): 84 classificationCount = {} 85 for i in classList: 86 if not i in classificationCount.keys(): 87 classificationCount[i] = 0 88 else: 89 classificationCount[i] += 1 90 sortedClassification = sorted(dict2list(classificationCount),key = operator.itemgetter(1),reverse = True) 91 return sortedClassification[0][0] 92 93 #dict字典转换为list列表 94 def dict2list(dic:dict): 95 keys=dic.keys() 96 values=dic.values() 97 lst=[(key,value)for key,value in zip(keys,values)] 98 return lst 99 100 #创建树 101 def createTree(dataSet,labels): 102 classificationList = [feature[-1] for feature in dataSet] #产生数据集中的分类列表,保存的是每一行的分类 103 if classificationList.count(classificationList[0]) == len(classificationList): #如果分类别表中的所有分类都是一样的,则直接返回当前的分类 104 return classificationList[0] 105 if len(dataSet[0]) == 1: #如果划分数据集已经到了无法继续划分的程度,即已经使用完了全部的feature,则进行决策 106 return majority(classificationList) 107 bestFeature = chooseBestSplitWay(dataSet) #计算香农熵和信息增益来返回最佳的划分方案,bestFeature保存最佳的划分的feature的索引 108 bestFeatureLabel = labels[bestFeature] #取出上述的bestfeature的具体值 109 Tree = {bestFeatureLabel:{}} 110 del(labels[bestFeature]) #删除当前进行划分是使用的feature避免下次继续使用到这个feature来划分 111 featureValueList = [feature[bestFeature]for feature in dataSet] #对于上述取出的bestFeature,取出数据集中属于当前feature的列的所有的值 112 uniqueValue = set(featureValueList) #去重 113 for value in uniqueValue: #对于每一个feature标签的value值,进行递归构造决策树 114 subLabels = labels[:] 115 Tree[bestFeatureLabel][value] = createTree(splitDataSet(dataSet,bestFeature,value),subLabels) 116 return Tree 117 118 def storeTree(inputree,filename): 119 fw = open(filename, ‘wb‘) 120 pickle.dump(inputree, fw) 121 fw.close() 122 123 def grabTree(filename): 124 fr = open(filename, ‘rb‘) 125 return pickle.load(fr) 126 127 #测试算法 128 def classify(inputTree,featLabels,testVector): 129 root = list(inputTree.keys())[0] #取出树的第一个标签,即树的根节点 130 dictionary = inputTree[root] #取出树的第一个标签下的字典 131 featIndex = featLabels.index(root) 132 for key in dictionary.keys():#对于这个字典 133 if testVector[featIndex] == key: 134 if type(dictionary[key]).__name__ == ‘dict‘: #如果还有一个新的字典 135 classLabel = classify(dictionary[key],featLabels,testVector)#递归向下寻找到非字典的情况,此时是叶子节点,叶子节点保存的肯定是类别 136 else: 137 classLabel=dictionary[key]#叶子节点,返回类别 138 return classLabel 139 140 def test(mytree,labels,filename,sum,correct,error): 141 with open(filename, ‘r‘)as csvfile: 142 dataset=[line.strip().split(‘, ‘) for line in csvfile.readlines()] #读取文件中的每一行 143 dataset=[[int(i) if i.isdigit() else i for i in row] for row in dataset] #对于每一行中的每一个元素,将行列式数字化并且去除空白保证匹配的正确完成 144 cleanoutdata(dataset) #数据清洗 145 del(dataset[0]) #删除第一行和最后一行的空白数据 146 del(dataset[-1]) 147 precondition(dataset) #预处理数据集 148 # clean(dataset) #把测试集中的,不存在于训练集中的数据清洗掉 149 sum = len(dataset) 150 for line in dataset: 151 result=classify(mytree,labels,line)+‘.‘ 152 if result==line[8]: #如果测试结果和类别相同 153 correct = correct + 1 154 else : 155 error = error + 1 156 157 return sum,correct,error 158 159 def precondition(mydate):#清洗连续型数据 160 #continuous:0,2,4,10,11,12 161 for each in mydate: 162 del(each[0]) 163 del(each[1]) 164 del(each[2]) 165 del(each[7]) 166 del(each[7]) 167 del(each[7]) 168 169 # def clean(dataset):#清洗掉测试集中出现了训练集中没有的值的情况 170 # global mydate 171 # for i in range(8): 172 # set1=set() 173 # for row1 in mydate: 174 # set1.add(row1[i]) 175 # for row2 in dataset: 176 # if row2[i] not in set1: 177 # dataset.remove(row2) 178 # set1.clear() 179 180 dataSetName=r"C:\Users\yang\Desktop\adult.data" 181 mydate,label=createDateset(dataSetName) 182 labelList=label[:] 183 184 Tree=createTree(mydate,labelList) 185 186 sum = 0 187 correct = 0 188 error = 0 189 190 storeTree(Tree,r‘C:\Users\yang\Desktop\tree.txt‘) #保存决策树,避免下次再生成决策树 191 192 # Tree=grabTree(r‘C:\Users\yang\Desktop\tree.txt‘)#读取决策树,如果已经存在tree.txt可以直接使用决策树不需要再次生成决策树 193 sum,current,unreco=test(Tree,label,r‘C:\Users\yang\Desktop\adult.test‘,sum,correct,error) 194 # with open(r‘C:\Users\yang\Desktop\trees.txt‘, ‘w‘)as f: 195 # f.write(str(Tree)) 196 print("准确率:%f" % correct / sum)
六、总结
由于ID3决策树还是存在着两个巨大的缺陷,下一节将是实现C4.5决策树,下下节是CART分类回归树,这两种树将弥补这种缺点。另外是使用的Adult数据集的问题,所得到的结果(正确率)超过官方所给的数据,究其原因应该是数据清洗的时候,我把大多数的噪声数据清洗掉了,这对数据集的破坏非常大,其实如果可以的话,还是应该进行填补和填充的。另外就是使用Iris数据集应该可以使得正确率非常高,因为其属性特征的数目不多,取值也不多,ID3决策树在这方面还是趋于一个弱势,所以才会有C4.5,C5.0和CART的出现。C4.5和CART会继续用Python3实现,C5.0试一下哈哈。
原创博客,码字不易,转载注明出处~ github:https://github.com/hahahaha1997/DecisionTree
标签:eth unit air 归一化 进一步 span 计算 地方 ever
原文地址:https://www.cnblogs.com/DawnSwallow/p/9452586.html