标签:format 解决 stop 对比 连接 constrain 修改 方向 justify
Mysql
目录
sudo apt-get install mysql-server mysql-client
然后按照提示输入
service mysql start
service mysql stop
service mysql restart
sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf
将bind-address=127.0.0.1注释
grant all privileges on *.* to ‘root‘@‘%‘ identified by ‘mysql‘ with grant option;
flush privileges;
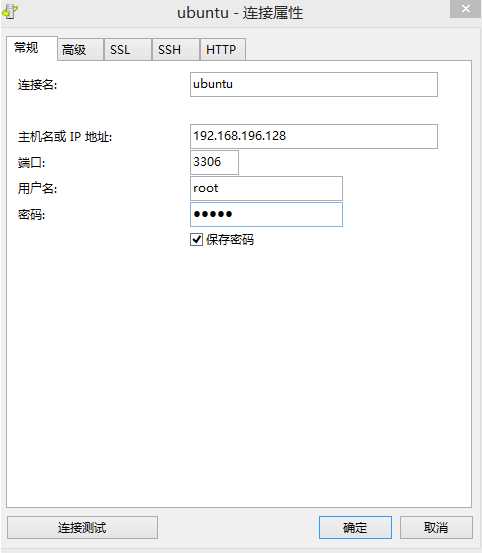
mysql -uroot -p
回车后输入密码,当前设置的密码为mysql
quit或exit

查看版本:select version();
显示当前时间:select now();
mysql -hip地址 -uroot -p
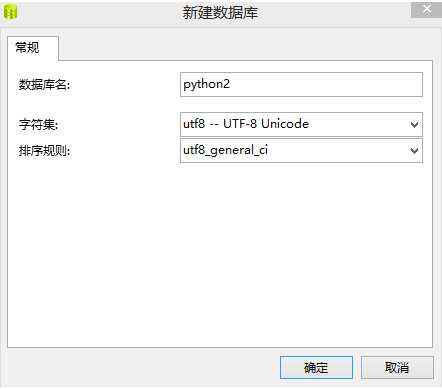
create database 数据库名 charset=utf8;
drop database 数据库名;
use 数据库名;
select database();
show tables;
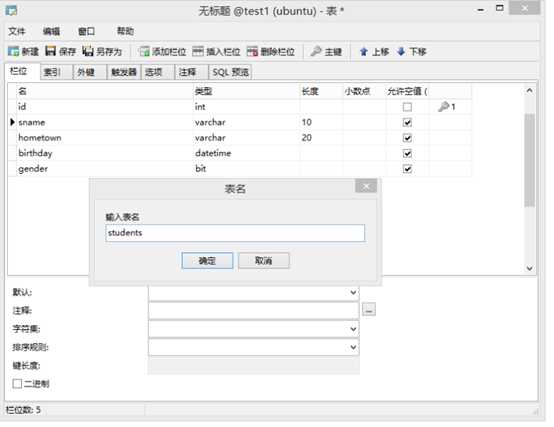
alter table 表名 add|change|drop 列名 类型;
如:
alter table students add birthday datetime;
drop table 表名;
desc 表名;
rename table 原表名 to 新表名;
show create table ‘表名‘;
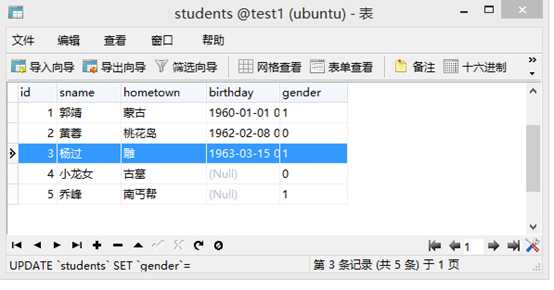
select * from 表名
全列插入:insert into 表名 values(...)
缺省插入:insert into 表名(列1,...) values(值1,...)
同时插入多条数据:insert into 表名 values(...),(...)...;
或insert into 表名(列1,...) values(值1,...),(值1,...)...;
update 表名 set 列1=值1,... where 条件
delete from 表名 where 条件
alter table students add isdelete bit default 0;
如果需要删除则
update students isdelete=1 where ...;
sudo -s
cd /var/lib/mysql
mysqldump –uroot –p 数据库名 > ~/Desktop/备份文件.sql;
按提示输入mysql的密码
mysql -uroot –p 数据库名 < ~/Desktop/备份文件.sql
根据提示输入mysql密码
select * from 表名 where 条件;
select * from students where id>3;
select * from subjects where id<=4;
select * from students where sname!=‘黄蓉‘;
select * from students where isdelete=0;
select * from students where id>3 and gender=0;
select * from students where id<4 or isdelete=0;
select * from students where sname like ‘黄%‘;
select * from students where sname like ‘黄_‘;
select * from students where sname like ‘黄%‘ or sname like ‘%靖%‘;
select * from students where id in(1,3,8);
select * from students where id between 3 and 8;
select * from students where id between 3 and 8 and gender=1;
select * from students where hometown is null;
select * from students where hometown is not null;
select * from students where hometown is not null and gender=0;
select count(*) from students;
select max(id) from students where gender=0;
select min(id) from students where isdelete=0;
select sum(id) from students where gender=1;
select avg(id) from students where isdelete=0 and gender=0;
select 列1,列2,聚合... from 表名 group by 列1,列2,列3...
select gender as 性别,count(*)
from students
group by gender;
select hometown as 家乡,count(*)
from students
group by hometown;
select 列1,列2,聚合... from 表名
group by 列1,列2,列3...
having 列1,...聚合...
方案一
select count(*)
from students
where gender=1;
-----------------------------------
方案二:
select gender as 性别,count(*)
from students
group by gender
having gender=1;
select * from 表名
order by 列1 asc|desc,列2 asc|desc,...
select * from students
where gender=1 and isdelete=0
order by id desc;
select * from subject
where isdelete=0
order by stitle;
select * from 表名
limit start,count
select * from students
where isdelete=0
limit (n-1)*m,m
select distinct *
from 表名
where ....
group by ... having ...
order by ...
limit star,count
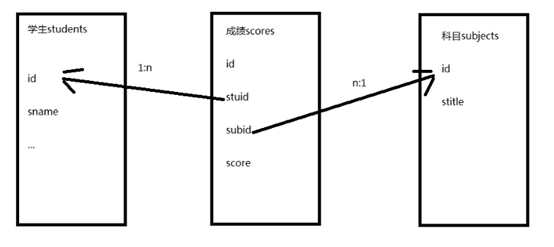
create table scores(
id int primary key auto_increment,
stuid int,
subid int,
score decimal(5,2)
);
alter table scores add constraint stu_sco foreign key(stuid) references students(id);
create table scores(
id int primary key auto_increment,
stuid int,
subid int,
score decimal(5,2),
foreign key(stuid) references students(id),
foreign key(subid) references subjects(id)
);
级联操作的类型包括:
select students.sname,subjects.stitle,scores.score
from scores
inner join students on scores.stuid=students.id
inner join subjects on scores.subid=subjects.id;
select students.sname,avg(scores.score)
from scores
inner join students on scores.stuid=students.id
group by students.sname;
select students.sname,avg(scores.score)
from scores
inner join students on scores.stuid=students.id
where students.gender=1
group by students.sname;
select subjects.stitle,avg(scores.score)
from scores
inner join subjects on scores.subid=subjects.id
group by subjects.stitle;
select subjects.stitle,avg(scores.score),max(scores.score)
from scores
inner join subjects on scores.subid=subjects.id
where subjects.isdelete=0
group by subjects.stitle;
create table areas(
id int primary key,
atitle varchar(20),
pid int,
foreign key(pid) references areas(id)
);
source areas.sql;
select city.* from areas as city
inner join areas as province on city.pid=province.id
where province.atitle=‘山西省‘;
select dis.*,dis2.* from areas as dis
inner join areas as city on city.id=dis.pid
left join areas as dis2 on dis.id=dis2.pid
where city.atitle=‘广州市‘;
select sname,
(select sco.score from scores sco inner join subjects sub on sco.subid=sub.id where sub.stitle=‘语文‘ and stuid=stu.id) as 语文,
(select sco.score from scores sco inner join subjects sub on sco.subid=sub.id where sub.stitle=‘数学‘ and stuid=stu.id) as 数学,
(select sco.score from scores sco inner join subjects sub on sco.subid=sub.id where sub.stitle=‘英语‘ and stuid=stu.id) as 英语
from students stu;
select ascii(‘a‘);
select char(97);
select concat(12,34,‘ab‘);
select length(‘abc‘);
select substring(‘abc123‘,2,3);
select trim(‘ bar ‘);
select trim(leading ‘x‘ FROM ‘xxxbarxxx‘);
select trim(both ‘x‘ FROM ‘xxxbarxxx‘);
select trim(trailing ‘x‘ FROM ‘xxxbarxxx‘);
select space(10);
select replace(‘abc123‘,‘123‘,‘def‘);
select lower(‘aBcD‘);
select abs(-32);
select mod(10,3);
select 10%3;
select floor(2.3);
select ceiling(2.3);
select round(1.6);
select pow(2,3);
select PI();
select rand();
select year(‘2016-12-21‘);
select ‘2016-12-21‘+interval 1 day;
* 获取年%y,返回2位的整数
* 获取月%m,值为1-12的整数
* 获取时%H,值为0-23的整数
* 获取时%h,值为1-12的整数
* 获取分%i,值为0-59的整数
* 获取秒%s,值为0-59的整数
select date_format(‘2016-12-21‘,‘%Y %m %d‘);
select current_date();
select current_time();
select now();
create view stuscore as
select students.*,scores.score from scores
inner join students on scores.stuid=students.id;
select * from stuscore;
show create table students;
alter table ‘表名‘ engine=innodb;
开启begin;
提交commit;
回滚rollback;
终端1:
select * from students;
------------------------
终端2:
begin;
insert into students(sname) values(‘张飞‘);
终端1:
select * from students;
终端2:
commit;
------------------------
终端1:
select * from students;
终端1:
select * from students;
------------------------
终端2:
begin;
insert into students(sname) values(‘张飞‘);
终端1:
select * from students;
终端2:
rollback;
------------------------
终端1:
select * from students;
标签:format 解决 stop 对比 连接 constrain 修改 方向 justify
原文地址:https://www.cnblogs.com/XiaoGuanYu/p/9462066.html