标签:存储空间 oracl src 性能 例子 索引 btree bsp 而不是
想要了解Mysql的索引类型,还得先看看SqlServer是怎样索引的。
SqlServer 将索引分为:
聚集索引,非聚集索引
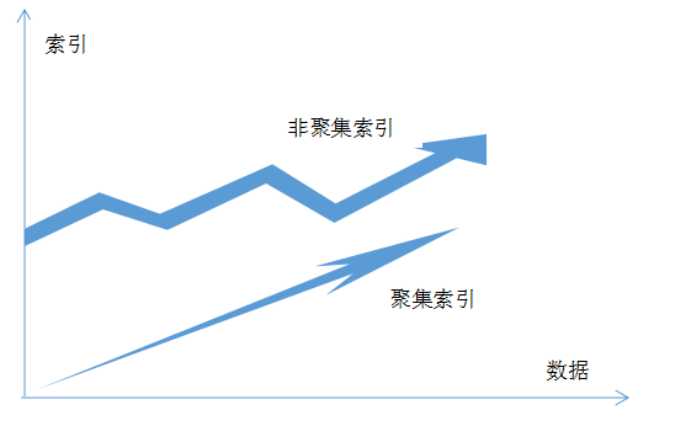
从图中可以看出,聚集索引顺序和数据内容的顺序一致,而非聚集索引顺序与数据内容无关。
网上看到的一个很好的栗子:
我们买的词典,有两种目录:
1. 按字母表查询的目录
2. 按偏旁部首查询的目录
我们会发现,
用第一种方式查询字典,目录显示的字母顺序,与字典内容出现的顺序正好一致。(聚集索引)
用第二种方式查询字典,目录显示的笔画顺序,与字典内容完全不一致。(非聚集索引)
但是,这个例子有不恰当的地方~!
因为我们不管是通过字母查询,还是偏旁部首查询结果都是结果所在的页数。
但是,这与两种索引的实际情况全都不一致,
聚集索引查询后,“无需翻页再次查找”,直接找到目的值。
非聚集索引查询后,可能需要再进行一次聚集索引查询(二次查询)。
组成成分上:
聚集索引:键值(叶子节点)就是实实在在的表中数据
非聚集索引: 键值(叶子结点),为逻辑指针(另一索引页)。
查找方式上:
聚集索引:数据是连贯的,即范围性查找时,只需找到起始和结束即可。
非聚集索引:数据是分散的,在范围性查找时,需要通过指针一个一个去查。
使用场景总结:
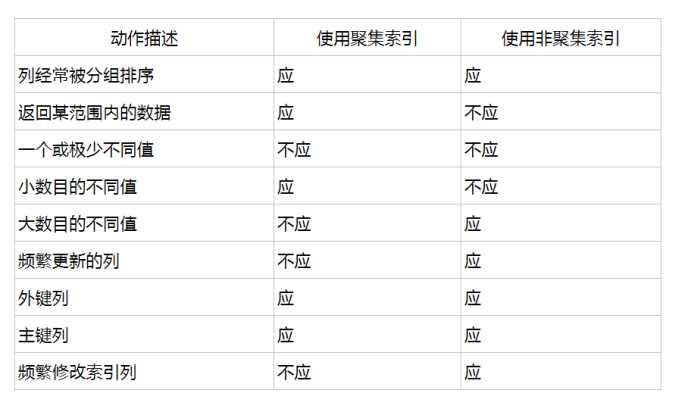
很重要的一点:
大部分非聚集索引想要取到数据,需要通过聚集索引
非聚集索引它查出来的是一个指向数据的指针,因此它需要在到真正的存储数据的地方把数据取出来。怎么取呢?靠的就是聚集索引。
举一个栗子帮忙理解:
你生病了头痛,去看医生。
1. 医生给你开了一个方子,叫你拿着去找药房。
2. 药房凭着你拿着的单子给你抓药。(二次查询)
这里的“方子” 就是指针,我们需要的是药而不是“方子”。所以将它作为聚集索引,去到药房查找。
多说一点:
一张表对外只有一种顺序,所有只允许存在一种聚集索引。
如果一张表没有聚集索引,那么它被称为“堆集”(Heap)。这样的表中的数据行没有特定的顺序,所有的新行将被添加的表的末尾位置。
聚集索引的好处:
1)数据行是按主键顺序存储在一起的,读取少量的磁盘页面就可以把相邻主键的数据读出来。
2)索引和数据都保存在一棵B tree中,从索引中读取数据较快
3)使用覆盖索引的查询可以使用包含在叶子节点的主键值。
聚集索引的缺点:
1)更新clustered index列代价是昂贵的,因为要强制把每个更新的数据行移到新位置
2)按主键顺序插入新行是一种好方法,否则更新主键或插入到随机插入性能开销比较大。
谈索引使用的误区
1、主键就是聚集索引
是极端错误的,是对聚集索引的一种浪费。
这是个很常见的错误,不过大家忽略这个原因,来自Mysql的“善意”。
大家常用的Mysql的两个引擎:
1.InnoDB 自动将聚集索引与主键绑定
2.MyIsam 全部都是非聚集索引
所以,在Mysql 中CLUTERED关键字根本不起作用,但是他在SqlServer和Ooracle中是有用的~!
为什么说是对资源的浪费?
因为聚集索引与数据的顺序对应,使用聚集索引的最大好处就是能够根据查询要求,迅速缩小查询范围,避免全表扫描。
而如果只将毫无意义的 id 设为聚集索引,我们在条件查询时很难再用到聚集索引。
下面是网上摘抄的比对图:
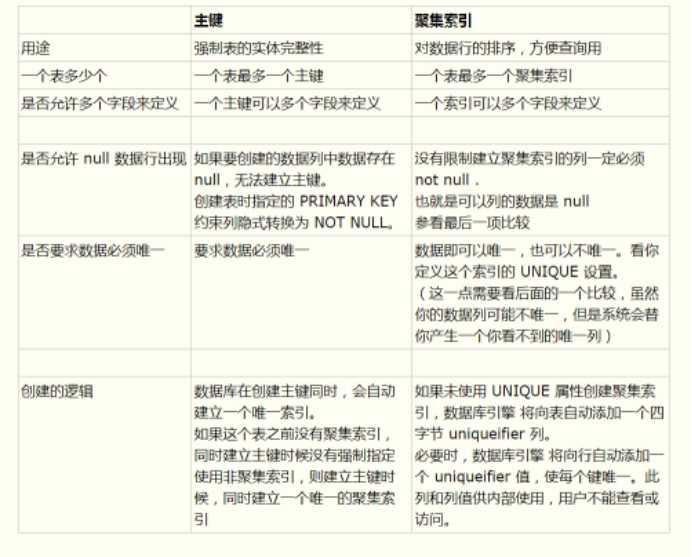
2、只要建立索引就能显著提高查询速度
不行,只有适合的索引才能提升效率。
举个很简单的栗子,如果建立索引的字段中有大量的重复数据,则这个索引的效率将十分低下。
3.聚集索引加入的字段越多越好吗
不是,我们通常只在聚集索引中加入常用的列且数目为1
4.是不是聚集索引就一定要比非聚集索引性能优呢?
不是,通常说条件越多的(覆盖索引)要优于聚集索引
5.在数据库中通过什么描述聚集索引与非聚集索引的?
索引是通过Btree 树的形式进行描述的,
聚集索引的叶节点就是最终的数据节点,而非聚集索引的叶节仍然是索引节点,但它有一个指向最终数据的指针。
6.在主键是创建聚集索引的表在数据插入上为什么比主键上创建非聚集索引表速度要慢?
1.聚集索引由于索引叶节点就是数据页,所以如果想检查主键的唯一性,需要遍历所有数据节点
2.非聚集索引由于索引上已经包含了主键值,所以查找主键唯一性,只需要遍历所有的索引页就行(索引的存储空间比实际数据要少),
7.用聚合索引比用一般的主键作order by时速度快,特别是在小数据量情况下
这里,用聚合索引比用一般的主键作order by时,速度快了3/10。
事实上,如果数据量很小的话,用聚集索引作为排序列要比使用非聚集索引速度快得明显的多;而数据量如果很大的话,如10万以上,则二者的速度差别不明显。
上面提到“覆盖索引”甚至优于聚集索引,为什么?
覆盖索引
非聚集索引的重要的特性。
上面,我们说你还要拿着“方子” 再找一次药房这杯称之为“二次查询”
但是,如果你的方子直接写清楚了对应药房的多少号,那你就可以自己取了。
怎么写清楚?这就要用到覆盖索引。
我们说,
如果一个索引包含(或者覆盖)了所有需要查询的字段(列)的值,我们称之为“覆盖索引”。
key(last_name, first_name, birthday) 对于 select last_name,first_name from people 就是覆盖索引。
可以这么说“覆盖索引”就是Mysql中的组合索引的全匹配形式。
覆盖索引的优缺点很明显:
优:
1、索引项通常比记录要小,所以MySQL访问更少的数据
2、索引都按值的大小顺序存储,相对于随机访问记录,需要更少的I/O
3、大多数据引擎能更好的缓存索引,比如MyISAM只缓存索引
4、覆盖索引对于InnoDB表尤其有用,免去了二次查询
缺:
苛刻的查询条件,由于是字段组合查询,维护起来相当麻烦
注意
1、覆盖索引也并不适用于任意的索引类型,索引必须存储列的值
2、Hash 和full-text索引不存储值,因此MySQL只能使用B-TREE
3、并且不同的存储引擎实现覆盖索引都是不同的
4、并不是所有的存储引擎都支持它们
5、如果要使用覆盖索引,一定要注意SELECT 列表值取出需要的列,不可以是SELECT *,因为如果将所有字段一起做索引会导致索引文件过大,查询性能下降,不能为了利用覆盖索引而这么做
标签:存储空间 oracl src 性能 例子 索引 btree bsp 而不是
原文地址:https://www.cnblogs.com/oldma/p/9472360.html