标签:.com 过滤 概念 test use bin 第四部分 const 写入
ElasticSearch是目前开源全文搜索引擎的首选,可以快速存储,搜索和分析海量数据。Stack Overflow,Github等都在使用。
Elasticsearch 是使用 Java 编写的,它的内部使用 Lucene 做索引与搜索,但是它使全文检索变得简单, 通过隐藏 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API。
ES提供的Client API:https://www.elastic.co/guide/en/elasticsearch/client/index.html
包含多种语言:

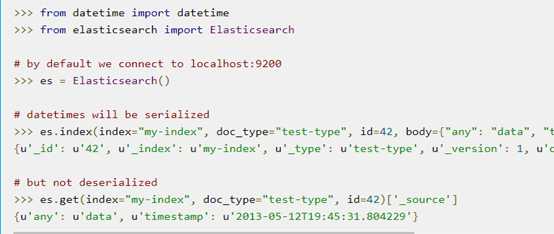
注意:没有C++接口,而我们需要基于c++操作ES
设备IP:10.3.246.224
系统:linux-64
磁盘空间:无 (df –h 发现磁盘没容量了)
du -sh /* | sort –nr :找出系统中占容量最大的文件夹,系统中15scpp这个文件夹占41G
du -sh /15scpp/* | sort -nr :找出15scpp中占容量最大文件夹15scpp_testbin,占31G
确认这个文件夹已无用,rm删除
PS:在Linux中,当我们使用rm在linux上删除了大文件,但是如果有进程打开了这个大文件,却没有关闭这个文件的句柄,那么linux内核还是不会释放这个文件的磁盘空间。找出文件使用进程,kill掉,即可
Elastic 需要 Java 8 环境
Java –version查看java是否安装或现在版本
官网下载jdk-8u181-linux-x64.tar.gz,解压,安装,设置环境变量,这里就不赘述。
下载https://www.elastic.co/downloads/elasticsearch :
elasticsearch-6.3.2.tar.gz
tar解压
因为安全问题elasticsearch 不让用root用户直接运行,所以要创建新用户:
adduser pwrd-es
passwd pwrd-es pwrd-es
chown -R pwrd-es:pwrd-es /home/elasticSearch/elasticsearch-6.3.2
//因为安全问题,不让root用户执行安装,但是其他用户又没有文件操作权限,故而改之
Vim config/elasticSearch.yml
cluster.name: pwrd-es //Elasticsearch会自动发现在同一网段下的Elasticsearch 节点,用这个属性来区分不同的集群,cluster.name相同则自动组建成一个集群
node.name: node-1 //节点名,默认随机指定一个name列表中名字,不能重复
node.master: true //指定该节点是否有资格被选举成为node,默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master
node.data: true //指定该节点是否存储索引数据,默认为true
path.data: /home/elasticSearch/log_export/data //存储数据
path.logs: /home/elasticSearch/log_export/logs //存储日志
network.host: 10.3.246.224 //设置成0.0.0.0 在curl中可以用localhost
http.port: 9200 //监听端口
index.number_of_shards: 5 // 设置默认索引分片个数,默认为5片
index.number_of_replicas: 1 //设置默认索引副本个数,默认为1个副本
vim /etc/sysctl.conf
vm.max_map_count = 655360
sysctl -p
切换用户: su pwrd-es
./elasticsearch
浏览器中输入10.3.246.224:9200
或者
curl ‘http://localhost:9200/?pretty‘
可以看到一个json数据,即为安装成功
PS:pretty是为了json格式化,以至于返回的结果好看一些
Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。
单个 Elastic 实例称为一个节点(node)。一组节点构成一个集群(cluster)
通过cluster.name 属性配置集群的名字,用于唯一标识一个集群,不同的集群,其cluster.name 不同,集群名字相同的所有节点自动组成一个集群。当启动一个结点时,该结点会在当前局域网内自动寻找相同集群名字的主结点;如果找到主结点,该结点加入集群中;如果未找到主结点,该结点成为主结点。
ES基本结构是 : index/type/id -> document (一般以json样式存储数据)
所以Index(索引)是Elastic 数据管理的顶层单位,它是单个数据库的同义词。
ES会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。
PS:每个 Index (即数据库)的名字必须是小写。
可以用如下命令,查看当前节点索引:
curl -X GET ‘http://localhost:9200/_cat/indices?v‘
Index里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。
Document 使用 JSON 格式表示,如下:
{
“name”:”张三”,
“age”:18,
“sex”:”male”
}
PS:对于json的编写与格式是否正确,可以借助在线json工具:http://www.bejson.com/
Type可以用来分类document,比如,china/Beijing/id-i ->doc-n
china/shanghai/id-j ->doc-m
同一个Index下不同的 Type 应该有相似的结构。
但是,Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会彻底移除 Type。
我们部署的是当前最新6.3.2版本
当一个索引下的数据太多,超过单一节点所能提供的磁盘空间,ES提供分片功能,可以将海量数据分片存储到集群中不同的节点中。当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。
为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
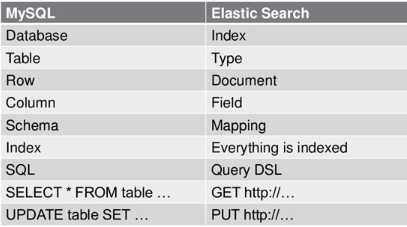
但是目前type即将作废。
curl -XPUT "http://10.3.246.224:9200/tests/"
返回数据
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "testes"
}
curl -XPUT "http://10.3.246.224:9200/tests/songs/1" -d ‘{"name":"deck the halls","year":"2018","month":"8"}‘ 会报错,如下指定header就可以了
curl -H "Content-Type: application/json" -XPUT "http://10.3.246.224:9200/tests/songs/1" -d ‘{"name":"deck the halls","year":"2018","month":"8"}‘
返回结果:
{
"_index": "testes",
"_type": "songs",
"_id": "1", //id 也可以不知道,由系统自主生成
"_version": 1,
"result": "created",//代表添加成功
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
curl -XGET http://localhost:9200/music/songs/1?pretty
返回数据:
{
"_index" : "testes",
"_type" : "songs",
"_id" : "1",
"_version" : 1,
"found" : true, //查找成功
"_source" : { //目的数据
"name" : "deck the halls",
"year" : "2018",
"month" : "8"
}
}
a) 查找更新某个key:
curl -H "Content-Type: application/json" -XPOST "http://10.3.246.224:9200/testes/songs/1/_update?pretty" -d ‘{"doc":{"query":{"match":{"name":"qqqddd"}}}}‘
返回数据:
{
"_index" : "testes",
"_type" : "songs",
"_id" : "1",
"_version" : 2,
"result" : "updated",//更新成功
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
b) 更新整条数据:
curl -H "Content-Type: application/json" -XPOST "http://10.3.246.224:9200/testes/songs/1/_update?pretty" -d ‘{"doc":{"name":"qddd","year":"2018","month":"8"}}‘
返回数据同上
c) 还有就是用添加数据的命令:只是将数据改了
curl -H "Content-Type: application/json" -XPUT "http://10.3.246.224:9200/tests/songs/1" -d ‘{"name":"deck the halls","year":"2020","month":"8"}‘
curl -XDELETE "http://localhost:9200/music/songs/1"
返回数据:
{
"_index": "tests",
"_type": "songs",
"_id": "1",
"_version": 2,
"result": "deleted",//删除成功
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
注意:删除一个文档不会立即生效,它只是被标记成已删除。es将会在你之后添加更多索引的时候才会在后台进行删除内容的清理
有两个办法:
一是嵌入其他语言的开发,利用ES已提供的接口,比如,在C++中嵌入python API,这在编译上可能引入新的问题
二是需要自己构造如第四部分的http请求来获得数据,可以基于libcurl库,也可以基于系统中已有的httpproxy
为了不破坏已有系统的一致性,基于httpproxy,来构造http请求,对外封装提供C++接口
/*es是面向文档,基于索引的弹性搜索引擎,故而
*es中的数据结构:index/type/id ->对应一条数据,所以
*es中帖子的数据结构设计:
uid/tiezi/tid -> json{uid,tid,content,timestamp}
*虽然存在uid和tid的冗余,但是这样设计的好处是:可以很方便处理某个人某条数据,因为uid就是索引,这样还利用了,索引的高处理性能
*/
/*功能:向es中添加protobuf数据,但是在es中是以json样式存在
*uid:用户id
*tid:帖子id
*msg:帖子结构,即(uid,tid,content,timestamp)
*/
bool addDocument(const std::string &uid, const std::string &tid,const google::protobuf::Message *msg);
封装后形成的http请求:
curl -H "Content-Type: application/json" -XPUT "http://10.3.246.224:9200/ uid /tiezi/tid " -d ‘ msg .json_str()‘
/*功能:向es中删除某个人uid的所有数据
*uid:用户id
*/
bool deleteAllByUid(const std::string &uid);
封装后形成的http请求:
curl -XDELETE http://localhost:9200/uid -d ‘{“query”:{“match_all”:{}}}’
/*功能:向es中删除某个人具体的某个数据
*uid:用户id
*tid:帖子id
*/
bool deleteDocumentByUidTid(const std::string &uid, const std::string &tid);
封装后形成的http请求:
curl -XDELETE "http://localhost:9200/ uid / tiezi / tid "
/*功能:向es中删除某个用户某个时间点以前的所有帖子,也就是 小于 某个时间的所有帖子
*uid:用户id
*beforeTimes:时刻以前的数据将全部会删除
*/
bool deleteDocumentByUidBeforeTimes(const std::string &uid, const std::string &beforeTimes);
封装后形成的http请求:
curl -XPOST "http://localhost:9200/ uid /tiezi/_delete_by_query
-d‘{"query":{"range":{"timestamp.keyword":{"gte":"2016-07-09 11:18:21","lte":"2018-08-17 11:18:21","format":"yyyy-MM-dd HH:mm:ss"}}}}’
PS: timestamp是数据中一个字段,在时间段匹配中,要注意空格
/*功能:以或的逻辑关系操作查询帖子中是否存在包含词,并过滤返回结果,只返回并得到UID,tid
*注:比如查询词是词组:"running swimming",查询之后的结果是,只要帖子content中至少包含一个词汇就可以,即帖子content中包含"running","swimming","running ... swimming ..."都返回
*containsWords:查询词 或词组 ,比如 "sport","running swimming"
*uid_tid:查询成功返回的N条uid和tid数据
*/
int searchAllByContainWords_OR(const std::string &containsWords,vector<struct Uid_Tid> &uid_tid);
封装后形成的http请求:
curl -H "Content-Type: application/json" -XPOST "http://localhost:9200/_search
-d ‘{"query":{"match": {"content":{"query":"swimming running"","operator":"or"}}},"_source":["uid","tid"]}’
PS: operator 是or,表示是或逻辑操作,query中填写多个字段,匹配数据字段content中存在swimming或running,_source 中有数据字段uid和tid,用来控制返回结果的,当数据量很大的时候对结果裁剪,减少无用的数据传输
/*功能:以与的逻辑关系操作查询帖子中是否存在包含词,并过滤返回结果,只返回并得到UID,tid
*注:比如查询词是词组:"running swimming",查询之后的结果是,帖子content中包含每个词汇,即帖子content中包含running和 swimming才返回
*containsWords:查询词 或词组 ,比如 "sport","running swimming"
*uid_tid:查询成功返回的N条uid和tid数据
*/
Int searchAllByContainWords_AND(const std::string &containsWords,vector<struct Uid_Tid> &uid_tid);
封装后形成的http请求:
curl -H "Content-Type: application/json" -XPOST "http://localhost:9200/_search
-d ‘{"query":{"match": {"content":{"query":"swimming running"","operator":"and"}}},"_source":["uid","tid"]}’
PS:同上,区别是operator是and,表示是与逻辑操作
类似c++ API接口参考:https://github.com/QHedgeTech/cpp-elasticsearch
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
https://www.elastic.co/guide/cn/elasticsearch/guide/current/intro.html
https://discuss.elastic.co/c/elasticsearch/
在chrome中直接安装的插件,要比在linux下命令安装简单
ES也提供对数据的分析,功能非常强大,还有很多像ik这样分词插件,我们在浏览器中访问es服务,在web界面中也可以很方便的操作数据。了解的非常浅显,暂记于此,以待有机会深入了解。对于json格式以及json中数据空格也需要非常注意。
标签:.com 过滤 概念 test use bin 第四部分 const 写入
原文地址:https://www.cnblogs.com/woshare/p/9475379.html