标签:a+b 报名 得奖 全局 二进制 tps 十六 部分 任务
前言
c++是一种比较早的语言,具体诞生在什么时候我就不记得了
然后进入正文 -- >
正文
C++程序构造比较简单实现
#include<bits/stdc++.h> // 头文件
using namespace std; //使用STL空间
... //一些其他的程序或者定义内容
int main() //主程序
{
return 0;
}#include<bits/stdc++.h>这玩意反正Noip在考场上是可以用的,它包含了许多头文件,所以又被称为万能头文件
Ps: 本人不推荐使用万能头文件 - 虽然现在没什么大事发生,但是指不定那天CCF傻逼突然给你禁止了那么你就GG了,最好记住每个操作所对应的头文件什么的
using namespace std; 这玩意在OJ上面比较多,一般最好每次编程的时候都要加上,而且加了似乎比不加的空间要小(待考证)
int main()
{
...
}这玩意是个主程序,一般情况下有人这么写,与上面的写法等价,推荐写上面的
int main(void)
{
...
return 0;
}括号里面还是可以有参数,
int main(int argc char *argv[])
{
...
return 0;
}这个不太常用,因为这个是一个传参的程序 - 基本只有对拍的时候能用到,现在先不讨论
您会发现第一个写法似乎不需要return 0;乍一看还真是,运行也是正确的,但是为了确保程序正常运行之后结束,我们不考虑不加return 0的做法,只是告诉你可以不写,但是为了保险还是写上
int main()
{
...
return 0;
}接下来 -> 主程序设计
我们现在将要讨论主程序设计的相关事宜
用几个问题来讲 :
Q: 如何去定义一个我想要的变量
这个有几个变量是您需要了解的
| 变量类型 | 变量上限 | 存储内容 |
|---|---|---|
| int | \(2^{31}-1\) | 整数 |
| short | \(2^{15}-1\) | 整数 |
| long | \(2^{31}-1\) | 整数 |
| long long | \(2^{63}-1\) | 整数 |
| unsigned + XX | 原来类型上限*2 | 整数 |
其中的XX指的是unsigned上面的变量
为什么要讲上限呢?因为如果一个数字存不下了,那么这个变量就会溢出,从最小值从头开始加,就会导致结果的错误
int a=2147483648;
printf("%d",a);//结果是负数| 变量类型 | 有效位数 | 存储内容 |
|---|---|---|
| float | 6-7 | 浮点数 |
| double | 15-16 | 浮点数 |
| long double | 18-19 | 浮点数 |
浮点数可以理解成小数
浮点数相关注意事项
不能直接比较
float a =1.0;
if(a==1) return 0;这样的写法是错误的
应该是这样的
float a = 1.0;
if(a - 1 < 0.0000001) return 0;还有有的时候浮点数精度问题会出错,如果和答案有些差距建议换成有效位数比较高的long double
| 变量类型 | 存储内容 |
|---|---|
| char | 单个字符 |
| bool | 0或者1 |
| string | 字符串 - 多个字符组合在一起 |
| void | 空指针 , 无类型 |
char 一般表示的是单个字符
char c=‘A‘;
char c=65;
char c;由于C++比较灵活,使得char类型和整形之间可以相互转换
比如
int b=65;
char a=b;ASCII表
| 字符内容 | 对应ASCII码的值 |
|---|---|
| 0 - 9 | 48-57 |
| A-Z | 65-90 |
| a-z | 97-122 |
| - (减号) | 45 |
上面的最好背下来
char c=48;
char c=‘0‘;上面两句是等价的,因为第二句传的是字符 0而不是0这个数字
考试的时候忘了 赋值输出就好
bool变量-非零即一,空间小,一般用来做标记
string 字符串 - 比较好用,但是个人认为不如字符数组好用,数组是后面的内容
void 一般用来声明函数,因为有一些函数可以不用返回值
这里仔细讲讲全局变量和局部变量
不在函数内定义的 -> 全局变量
所有的函数都可以使用这个变量
在函数内定义的 -> 局部变量
只有定义它的函数才能够使用
局部数组容量 < 全局数组容量
因此,我们一般使用全局数组,局部变量
这里还要介绍一个东西 : sizeof
sizeof(变量名)返回的是变量类型占用存储空间的大小
用处不大,最多参考着定数组大小
接下来 , --> 变量的读入
#include<cstdio>
using namespace std;
int main()
{
int a;
long long b;
short c;
char d;
bool e;
float f;
double g;
long double h;
scanf("%d",&a);
scanf("%lld",&b);
scanf("%hd",&c);
scanf("%d",&c);// short的两种读入方式都可以
scanf("%c",&d);
scanf("%d",&e);//可以用整型方式输入输出没问题
scanf("%f",&f);
scanf("%lf,&g);
scanf("%llf",&h);
printf("%d %lld %hd\n",a,b,c);
printf("%d %lld %d",a,b,c);
return 0;
}这里的scanf和printf从属于
#include<cstdio>的,是一种C语言的输入输出方式,c++中也能够用,读入输出的速度很快,比较推荐
scanf("%lld",&b);这个里面的%lld表示的是格式,&是地址符,您只要知道要这么做就行,不这么做要么RE(Runtime Error : 运行时错误) ,要么CE(编译错误),要么WA(Wrong Answer,错误答案),有人不加地址符没事,但是这只是个例的语句,还是要加的
因为”“里面的是输入格式,%d是变量的输入格式,还可以有
scanf("%d %d",&n,&m);输入两个int变量n,m,中间用空格隔开,其实中间的格式操作符有很多,读者可以自己去查
printf("%d",b);格式操作符和scanf一样,输出的时候%d是变量格式控制符,可以在""内填其他的要输出的内容
printf("青山");只是后面变量名不需要加上地址符,后面还可以加上回车控制符\n,右对齐什么的,保证宽度至少为5位,就是%nd,然后%0nd用得比较多,表示输出的整型宽度至少为n位,不足n位用0填充,还有对于浮点数来说,可以%0.nf来保留n位输出
printf("%5d\n",b);
printf("%-5d\n",b);
long double b;
printf("%0.5llf\n",b);然后string类型的不能够使用scanf读入
#include<iostream>
using namespace std;
int main()
{
int a;
long long b;
short c;
...//其他的都一样
cin>>a>>b>>c;
cout<<a<<" "<<b<<" "<<c<<endl;
cout<<a<<" "<<b<<" "<<c;
return 0;
}一般cin和cout比较方便,没有格式什么的设定,但是它的速度十分的慢,所以一般情况下为了防止CCF老人机卡您的程序,我并不推荐您用cin和cout,虽然有取消同步从而加速的操作,但是如果恰巧您的printf和scanf之类的出现在程序中,那么迟早要出事
还有一个我推荐scanf和printf不推荐cin和cout的原因是cout保留n位输出和printf可能有不一样的地方,而造数据的一般用printf,所以最好不要用cin和cout
不过cin一个string类型的变量还是很不错的
下一章 -> 数组
现在我们已经学完了变量的定义方式那么:
Q: 现在要求输入N个数字,并原样输出
输入格式
两行,第一行,一个数字N
第二行,N个用空格隔开的数字
输出格式
一行,N个用空格隔开的数字
对于这道题目而言我们可以这么来理解 - 输出一个数组
其实还有一种在线做法,十分简单,但是因为没有讲循环,先当做数组的练习题
不管是什么类型我们都可以定义数组
定义方式
变量类型 + 数组名 + [ 数组大小 ] ;
举个例子
int ans[10086];int - 变量类型
ans - 数组名
[10086] 数组大小
数组的用法:
int a[3]={1,2,3}; //数组大小为3,初始值为a[0]=1,a[1]=2,a[2]=3;
int a[]={1,2,3};//和上面的语句等价,一定要赋初值,然后系统自动分配空间
int a[3]={};//数组初始化为零
int a[3]={0};//和上面的语句等价
int a[3]={1,2};//这也是可以的,只是没有赋值的为0,也就是a[0]=1,a[1]=2,a[2]=0;这里要注意的是:数组从零开始,也就是说,
int a[n];
printf("%d",a[n]);是错误的,它只到a[n-1];
还有一种初始值操作:
#include<cstring>
memset(a,0,sizeof(a));但是好像只能为0或者-1,还有16进制的相关问题(不知道进制的可以自己去学)
因为这个地方的参数,也就是memset里面的那个数字(在上面的例子中是0),然后我们可以发现的是,这个参数赋值是赋值到int变量的4个Byte中,也就是说,一个数字赋值为0 是这样的
0000 | 0000 | 0000 | 0000 = 0而 0x代表的就是16进制,所以0x3f3f3f3f代表的就是
因为\(3_{(10)}={11}_{(2)}\),而且\(f_{(16)}=15_{(10)}=1111_{(2)}\),十六进制位没有的数字用0补齐,十六进制在二进制中4位表示一个数字
\[{00111111001111110011111100111111}_{(2)} = {0x3f3f3f3f}_{(16)}\]
所以也就是memset(a,0x3f,sizeof(a));得到数字的来由.
而之所以赋值为1不行的原因是
\[0001 | 0001 | 0001 | 0001 = 1000100010001_{2} = 16843009\]
所以与我们预想的不一样
所以记住,memset只能够赋值0,-1,0x3f(得到结果为0x3f3f3f3f)
其中的0x3f3f3f3f是一个\(10^9\)数量级的数字,但是
2*0x3f3f3f3f < 0x7fffffff (2147483647也就是\(2^{31}-1\))
\[0x7fffffff = 0111 | 1111 | 1111 | 1111 | 1111 | 1111 | 1111 | 1111_{(2)} = 1111111111111111111111111111111_{(2)}=2^{31}-1\]
我们一般把INF(无穷大)定为0x3f3f3f3f的原因是在将来的最短路学习中,如果我们选择了Max_int,那么就算是再加上1也会溢出,而这里的无穷大即使加上无穷大也是比Max_int要小的,所以为了保险期间一般选择0x3f3f3f3f作为无穷大的值
学好Latex(上面数学公式排版的格式规范)还是很重要的
| 序号 | 操作方式 | 意义 |
|---|---|---|
| 1 | strcpy(s1,s2) | 复制字符串 s2 到字符串 s1 |
| 2 | strcat(s1,s2) | 连接字符串 s2 到字符串 s1 的末尾 |
| 3 | strlen(s1) | 返回字符串 s1 的长度 |
| 4 | strcmp(s1,s2) | 返回s1与s2的比较结果 |
| 5 | strchr(s1,ch) | 返回一个指针,指向字符串s1中字符ch的第一次出现的位置 |
| 6 | strstr(s1,s2) | 返回一个指针,指向字符串s1中s2的第一次出现的位置 |
初始化字符数组 :
C 风格的字符串起源于 C 语言,并在 C++ 中继续得到支持。字符串实际上是使用 null 字符 ‘\0’ 终止的一维字符数组。因此,一个以 null 结尾的字符串,包含了组成字符串的字符。
下面的声明和初始化创建了一个 “Hello” 字符串。由于在数组的末尾存储了空字符,所以字符数组的大小比单词 “Hello” 的字符数多一个。
char greeting[6] = {‘H‘, ‘e‘, ‘l‘, ‘l‘, ‘o‘, ‘\0‘};其实,您不需要把 null 字符放在字符串常量的末尾。C++ 编译器会在初始化数组时,自动把 ‘\0’ 放在字符串的末尾。所以也可以利用下面的形式进行初始化
char greeting[] = "Hello";以下是 C/C++ 中定义的字符串的内存表示:
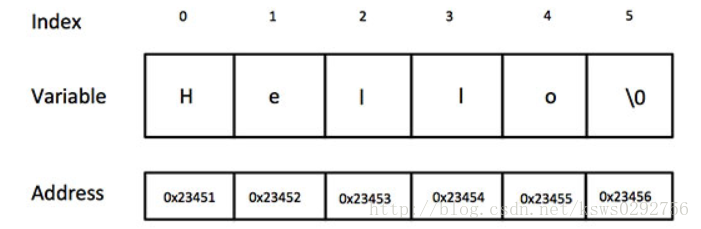
初始化字符串:
string str; //生成一个空字符串
string str ("ABC") //等价于 str="ABC"<br>
string str ("ABC", strlen) // 将"ABC"存到str里,最多存储前strlen个字节
string s("ABC",stridx,strlen) //将"ABC"的stridx位置,做为字符串开头,存到str里.且最多存储strlen个字节.
string s(strlen, ‘A‘) //存储strlen个‘A‘到str里所有字符串的操作:
str1.assign("ABC"); //清空string串,然后设置string串为"ABC"
str1.length(); //获取字符串长度
str1.size(); //获取字符串数量,等价于length()
str1.capacity(); //获取容量,容量包含了当前string里不必增加内存就能使用的字符数
str1.resize(10); //表示设置当前string里的串大小,若设置大小大于当前串长度,则用字符\0来填充多余的.
str1.resize(10,char c); //设置串大小,若设置大小大于当前串长度,则用字符c来填充多余的
str1.reserve(10); //设置string里的串容量,不会填充数据.
str1.swap(str2); //替换str1 和 str2 的字符串
str1.puch_back (‘A‘); //在str1末尾添加一个‘A‘字符,参数必须是字符形式
str1.append ("ABC"); //在str1末尾添加一个"ABC"字符串,参数必须是字符串形式
str1.insert ("ABC",2); //在str1的下标为2的位置,插入"ABC"
str1.erase(2); //删除下标为2的位置,比如: "ABCD" --> "AB"
str1.erase(2,1); //从下标为2的位置删除1个,比如: "ABCD" --> "ABD"
str1.clear(); //删除所有
str1.replace(2,4, "ABCD"); //从下标为2的位置,替换4个字节,为"ABCD"
str1.empty(); //判断为空, 为空返回true鸣谢: ZeroZone零域大佬和LifeYx大佬在网上发布的博客,收益匪浅
***
char类型
char c;
scanf("%c",&c);
cin>>c;
c=getchar();上面三种语句都行,但是一般scanf容易出错,cin又太慢,所以我是比较推荐getchar(),它的作用是读入单个字符
char[]类型
char c[10];
scanf("%s",c);
gets(c);//不能使用其中的gets是在#include<cstring>的里面,但是在比赛的时候用的是linux的系统,使用gets会报错,所以不能使用,所以只能用scanf,读入快,结束标志是空格或者换行 ,千万注意scanf读入字符数组的时候没有地址符
string类型
string a;
cin>>a;这个是我推荐的string读入的写法,但是我不推荐用string类型,最好使用字符数组
输出的话
char类型
char c;
putchar(c);//最快最方便的char[]类型
char c[10];
printf("%s",c);//也是可以用的中最快最方便的string类型
string s;
cout<<s;我还是只是推荐写法,不推荐用string写程序
除了char和string,都是推荐用printf和scanf输入的
具体要求和单个变量时一致,加上[当前序号]即可
举例来讲
for(int i=0;i<n;i++) scanf("%d",&a[i]);你阅读之后可以发现这个for是从哪里蹦出来的,之前没有学啊?
没学没关系,我现在教你,这货叫做循环,一般还有while,do while一共三种循环语句
for(表达式1;表达式2;表达式3)
{
语句1;
语句2;
语句3;
}
//或者
for(表达式1;表达式2;表达式3) 一个语句;一般是这样的格式,其中的表达式1一般是定义变量,变量赋初值,表达式2一般是约束条件,只有满足约束条件的时候才能够继续循环,不满足的时候就退出循环,表达式3是改变循环条件变量的值,使它在运行若干时长后停止循环
举个例子
for(int i=0 (循环变量,定义整型变量i 初始值为0);i<n (整型变量i必须小于n));i++(循环变量自增))) scanf("%d",&a[i]);认真的读者可以发现
i++ 是什么? 其实i++ 就是 i=i+1;把i本身的值+1,但是理论速度更快,更方便,如果看到了a[i++]的,那么说明它是在执行完了这个语句之后再把i自增,如果是a[++i] ,那么就是先把i自增,再执行这个语句,i--和--i都是这样。
所以我们的程序将会遍历(以n=3为例)
a[0],a[1],a[2];到了i=3的时候我们发现i=n了,那么我们跳出循环来
这个时候我们讲讲判断符
| 判断符 | 用处 |
|---|---|
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
| == | 等于 |
| && | 且 |
||(无法原样保留) |
或 |
| != | 不等于 |
就是这些
前面的一些判断符我不多说,后面的可能读者会有点疑惑
&&表示的是 而且
for(int i=0;i<j&&i>0;i++)其中的&&表示的就是i
||表示的是 或
for(int i=0;i<j||i>0;i++)其中的||表示的就是i
!= 表示的是 不等于
也就是\(\ne\),这个应该都学过
将来我们还要学到位运算
保留精力,以后再讲
下一章 -> while , do while
课后作业
没错,以后每次都有课后作业了
可以考虑截屏,也可以发文本,要求必须是可执行程序
给定一个长度为N的数列,第一行先输入N,第二行,输入N个用空格隔开的数字,原样输出N个数字,用空格隔开,要求必须使用数组
给定一个长度为N的数列,第一行先输入N,第二行,输入N个用空格隔开的数字,原样输出N个数字,用空格隔开,要求不能使用数组
给定一个数字N,要求你输出一行数字,分别为N,N-1,N-2,N-3,...,1(倒序输出))中间用空格隔开
给定一个数字N,要求你输出一行数字,分别为1,2,3,4,...,N-1,N(正序输出))中间用空格隔开
给定一个字符串,以换行为结尾,要求你原样输出而且不使用字符数组或者字符串
格式
while(判断条件)
{
语句1;
语句2;
}while(判断条件) 语句1;就是上面两种
还有
while(T--) 上面的写法比较常见,因为首先是判断T的值,再去减,和下面的语句等价
while(T) T--;T本身是一个数字,而这个数字也可以用来表示判断的条件,当这个数字是0的时候T不是真,否则T$\geqslant$1的时候T这个数字作为判断条件为真,也就是
| 数的值 | 判断的结果 |
|---|---|
| = 0 | 假 |
| $\geqslant$1 | 真 |
所以这个时候,只有T一直减直到为0的时候停止循环
为了简便我们一般采用两种语句的前者
举个例子
int i=10;
while(i--)
{
printf("%d ",i);
}得到的结果请自己思考
这个语句与While语句不同的原因是:
先执行do里面的语句再去判断while里面的判断条件是否成立,而while和for都是先看的条件是否成立
do
{
...
}
while(判断条件);或者
do 一个语句
while(判断条件);就是看着不舒服
记得一定要在while后面加分号
一个活生生的例子
int i=10;
do i--,printf("%d ",i);
while(i>1);结果还是读者自己思考
下面讲 -> 判断语句和运算符优先级
判断语句也不多,就两种
if(判断条件) 一个语句;if(判断条件)
{
语句1;
语句2;
语句3;
...
}else语句一般是指,在不满足与它匹配的if中判断条件的前提下执行else内的语句
if(a==1) printf("1");
else printf("0");
if(a==1) printf("1");
if(a!=1) printf("1");上面两句话等价
注意,else必须与if对应,每个else都必须有一个if对应,不然就不对,因为这样就没有反面的判断条件了
if()
{
if()
{
if()
{
...
}
else
{
}
}
else
{
}
}
else
{
}if和else可以相互嵌套,但是不能只有else没有if
判断条件前面讲过了,不懂得私信我
一个活脱脱的例子
#include<cstdio>
using namespace std;
int main ()
{
char grade=getchar();
switch(grade)
{
case ‘A‘ :puts("真棒!");break;
case ‘B‘ :puts("好样的!");break;
case ‘C‘ :puts("再试一下?");break;
case ‘D‘ :puts("过关!");break;
case ‘E‘ :puts("不过关!");break;
default :puts("成绩无效!");
}
printf("您的成绩是:%c\n",grade);
return 0;
}switch(变量)
{
case 1 :
case 2 :
case 3 :
...
default :
}其中的case多少可变,而且这个case后面跟的参数是当变量为此参数时执行这个命令,也就相当于
if(变量 == case参数) 执行语句;case后面的语句可以是多个的
变量可以不是int类型的,case参数以变量为准,比如下面的也是可以的
switch(grade)
{
case ‘A‘ :puts("真棒!");break;
case ‘B‘ :puts("好样的!");break;
case ‘C‘ :puts("再试一下?");break;
case ‘D‘ :puts("过关!");break;
case ‘E‘ :puts("不过关!");break;
default :puts("成绩无效!");
}这个地方枚举的是等级的字符
default就是当上面的所有case条件全部不满足,那么就执行当前语句
比如上面那个程序我们如果输入的是F,那么得到的就是成绩无效
需要记住的是 - 字符类型的是‘字符‘,而字符串是"字符串",一个是单引号,一个是双引号
也就是说:
char c;
if(c==‘A‘) return 0;//正确
if(c=="A") return 0;//错误
putchar(‘A‘);//正确
putchar("A");//错误在判断语句中间,字符串不能够直接比较,有一个函数但是不推荐
一般这个双引号是这样的
printf("字符串");
puts("字符串");一般可以认为puts输出完字符串之后会自动换行,但是printf不会。
puts比printf块
关于break和continue的事情
表示退出当前循环/判断,必须单独成为一个语句
表示跳过当前循环/判断,继续下个循环内容,必须单独成为一个语句
很早以前的书中还有goto这种操作,但是太随意了,被人们扔了,所以不能使用,现在没有什么书上有,也没人用
switch(grade)
{
case ‘A‘ :puts("真棒!");break;
case ‘B‘ :puts("好样的!");break;
case ‘C‘ :puts("再试一下?");break;
case ‘D‘ :puts("过关!");break;
case ‘E‘ :puts("不过关!");break;
default :puts("成绩无效!");
}所以这段话中的case后面的break就是跳出当前判断,如果不加上的话,程序将继续查看后面的case值,直到遇见下一个break或者最后的default才会跳出
所以default的break语句不是必须的
优先级比较好理解,就是*/号比+-的优先级高,在没有括号的前提下,先执行运算级高的部分 感谢小学数学老师
所以,在C++中的运算符操作一样是有优先级的
具体内容参照C++运算符优先级
C++中的数学运算
| 原来数学中代表的内容 | 在C++里面 |
|---|---|
| × | * |
| ÷ | / |
| + | + |
| - | - |
| ^ | pow(a,b)也就是(\(a^b\)) |
| mod(取余) | % |
需要注意的是,当整数/另一个整数 , 得到的结果将会取整,也就是说
4/3 == 1%号代表的是一个数除另外一个数的余数,我们知道,一个数除另一个数有两个结果 - 商 和 余数
这个商就是/,余数就是%
规定/,%后面不能为0,不然报错误 - 浮点数例外(Linux特产)
还有一个特别屌丝的东西 :
位运算是什么?首先我们需要了解二进制是什么
二进制也就是我们所说的非零即一,所有的数字都可以表示成0和1组合的数字。
因为某些匹克操作,二进制十分的强大,所以被用来搞事情
先来了解一下进制转换
这个看着比较骚,实际上还好
也就是每个位上的数字去乘进制数的当前所在位-1次方,举个例子
\[1 + 1 = 10_{(2)}\]
为什么呢?因为
\[10_{(2)} = 0*2^0+1*2^1\]
好了讲了半天(才五行)那么我们继续讲怎么实现
int r,len = n,sum=0;//r进制,len为数字长度(数字有多少位),sum为总和,也就是在10禁止下的数字
for(int i=1;i<=n;i++) sum = sum + a[i] * pow(r,i-1);
printf("%d",sum);至于pow是什么看下面:
C++有一个库,包含各种骚操作
#include<cmath>
double acos(double x)
返回x的反余弦弧度。
double asin(double x)
返回x的正弦弧线弧度。
double atan(double x)
返回x的反正切值,以弧度为单位。
double atan2(doubly y, double x)
返回y / x的以弧度为单位的反正切值,根据这两个值,以确定正确的象限上的标志。
double cos(double x)
返回的弧度角x的余弦值。
double cosh(double x)
返回x的双曲余弦。
double sin(double x)
返回一个弧度角x的正弦。
double sinh(double x)
返回x的双曲正弦。
double tanh(double x)
返回x的双曲正切。
double exp(double x)
返回e值的第x次幂。
double frexp(double x, int *exponent)
返回的值是尾数,而指数的整数yiibaied是指数。 结果值是x =尾数* 2 ^指数。 (translate by google )
double ldexp(double x, int exponent)
返回x乘以2,增加到指数幂。(translate by google )
double log(double x)
返回自然对数的x(基准-E对数)。
double log10(double x)
返回x的常用对数(以10为底)。
double modf(double x, double *integer)
返回的值是小数成分(小数点后的部分),并设置整数的整数部分。
double pow(double x, double y)
返回x的y次方。
double sqrt(double x)
返回x的平方根。
double ceil(double x)
返回大于或等于x的最小整数值。
double fabs(double x)
返回x的绝对值
double floor(double x)
返回的最大整数值小于或等于x。
double fmod(double x, double y)
返回的x除以y的余数。要用的时候加个头文件,按照规范使用就行,只要背一些常用的就行。
需要注意的是 : C++中间在运算的时候不像现代数学有大括号中括号花括号,不管是什么都是小括号
printf("%d",((a+b)*c+d)/e)对,中间用的就是小括号,不管怎样都是小括号
我相信这个都不会
会的略过
简单来讲,就是10 -> N进制的方式
其实就是原数不断除进制数,记录余数,然后反着组成
举个例子 :
\[10_{(10)} = 1010_(2)\]
10 % 2 = 0,10 / 2 = 5;
5 % 2 = 1,5 / 2 = 2;
2 % 2 = 0,2 / 2 = 1;
1 % 2 = 1,1 / 2 = 0;
算法结束倒序输出,也就是1010,答案是对的没错
用程序表达也就是
int sum=n,r,len=0,ans[105];//sum表示十进制数,r表示要转换的进制数,len表示r进制数的长度,ans存答案
while(sum)
{
ans[++len]=sum % r;
sum = sum / r;
}
for(int i=len;i>=1;i--) printf("%d",ans[i]);这种骚事C++也能干出来
操作也不多,就那几个,但是理解需要时间
&
^
|
<<
>>就这五个,嗯
我一个一个讲吧
按位与,至于按位怎么来的我想应该是因为它一位一位看吧哈哈哈
举个例子
1010101
&101010
也就是
在一个位上,如果都是1,那么就是1,否则为0,如果有一个位另外一个数字没有,那么那个数字的哪一位是0,自动补零,一般写出来省略0
所以答案就是
0000000
也就是0
舒不舒服哈哈哈
按位异或
可以理解成两个数字某一位上的数字相同的时候是0,不同的时候是1,那么为什么不反过来呢?数字前面的前置零怎么办!
举例更好理解
1010101
^101010
1111111
矮油我去,怎么又全是1了?
明明就是这样balabala
按位或
可以理解为两个数字某一位上的数字中至少1个是1的时候答案是1,否则就是0
也就是说
1010101
|101010
1111111
矮油怎么还是1111111?受不了换样例!
屁事多!
11111111
|1111111
11111111
凑合着看吧
左移,可以理解成*2,因为它就是把一个数字在最后加上一个0
右移,可以理解成/2,因为它就是把一个数字的最后一位去掉
这就是位运算
***
在C的语言中,有这样的操作,支持快速的赋值
a += b;
a -= b;
a *= b;
a /= b;
a %= b;
a &= b;
a ^= b;
a |= b;
a <<= b;
a >>= b;这个操作是从右向左的,也就是说,下面这个式子等价于:
a += a *= a /= a-6;
//等价于
a /= a-6;
a *= a;
a += a; 那么这些操作符是什么呢?这些操作符表达的意义也就是
a += b;
a = a + b;
a -= b;
a = a - b;
a *= b;
a = a * b;
a /= b;
a = a / b;
a %= b;
a = a % b;
a &= b;
a = a & b;
a ^= b;
a = a ^ b;
a |= b;
a = a | b;
a <<= b;
a = a << b;
a >>= b;
a = a >> b;也就是一个一直保持不变的量,这个时候有两种定义方式
define
#define可以理解成文本替换,用法简单
#define 替换文本 目标文本注意,最后没有分号,所以我们不能在define后面写注释,因为这样很有可能一起替换了
举个例子
#define LL long long
#define maxn 10005
#define max(a,b) ((a>b) ? a : b)然后这个时候就可以
#include<cstdio>
using namespace std;
#define LL long long
#define maxn 10005
#define max(a,b) ((a>b) ? a : b)
int main()
{
LL a=1,b=2,c=maxn;
printf("%lld %lld",max(a,b),c);
return 0;
}运行结果是
2 10005其中的
(a>b) ? a : b是一个三目运算符,它可以简单理解为
(判断条件) ? 语句1 (成立才执行) : 语句2 (否则,不成立才执行)等价于
if(判断条件) 语句1;
else 语句2;然后#define就这样用,一般还有
#define int long long也是可以的,但是主函数怎么办?没关系,
signed = signed int = int所以我们可以考虑这样写
signed main()其实#define主要是替换内容,但是const是真正的赋初值
const
#include<cstdio>
using namespace std;
#define LL long long
const int maxn = 10005;
#define max(a,b) ((a>b) ? a : b)
int main()
{
LL a=1,b=2,c=maxn;
printf("%lld %lld",max(a,b),c);
return 0;
}答案和用#define的一样,格式是
const 变量类型 变量名 = 初始值 ;注意,const后面有分号
在编译的时候,如果用#define而define的变量出错,它会提示你你替换的那个目标文本有问题,而不是你原来的文本有问题,但是const就会明确告诉你变量名,是哪个变量出错一清二楚
还有,#define后面不能接0x3f3f3f3f和0x7fffffff,但是const可以
基础内容讲解完毕! 有什么不懂的可以私信我,大胆地提问没关系
课后作业
写出一个判断闰年的程序,要求输入一个数字代表年份,一行输出,如果是闰年则输出Yes,如果不是那么输出No,判断规则是:能被4整除的 大多 是闰年,能被100整除而不能被400整除的年份不是闰年,能被400整除的是闰年,能被3200整除的也不是闰年
陶陶家的院子里有一棵苹果树,每到秋天树上就会结出 10 个苹果。苹果成熟的时候,陶陶就会跑去摘苹果。陶陶有个 30 厘米高的板凳,当她不能直接用手摘到苹果的时候,就会踩到板凳上再试试。
现在已知 10 个苹果到地面的高度,以及陶陶把手伸直的时候能够达到的最大高度,请帮陶陶算一下她能够摘到的苹果的数目。假设她碰到苹果,苹果就会掉下来。
输入包括两行数据。第一行包含 10 个 100 到 200 之间(包括 100 和 200 )的整数(以厘米为单位)分别表示 10 个苹果到地面的高度,两个相邻的整数之间用一个空格隔开。第二行只包括一个 100 到 120 之间(包含 100 和 120 )的整数(以厘米为单位),表示陶陶把手伸直的时候能够达到的最大高度。
输出一行,这一行只包含一个整数,表示陶陶能够摘到的苹果的数目。
[Noip普及组2005年]
某校大门外长度为L的马路上有一排树,每两棵相邻的树之间的间隔都是 1 米。我们可以把马路看成一个数轴,马路的一端在数轴 0 的位置,另一端在 L 的位置;数轴上的每个整数点,即 0,1,2,…,L,都种有一棵树。
由于马路上有一些区域要用来建地铁。这些区域用它们在数轴上的起始点和终止点表示。已知任一区域的起始点和终止点的坐标都是整数,区域之间可能有重合的部分。现在要把这些区域中的树(包括区域端点处的两棵树)移走。你的任务是计算将这些树都移走后,马路上还有多少棵树。
输入输出格式
输入格式:
第一行有 2个整数 L(1\(\le\)L$\le$10000)和 M(1 \(\le\)M$\le$100), L 代表马路的长度, M 代表区域的数目, L 和 M 之间用一个空格隔开。
接下来的 M 行每行包含 2 个不同的整数,用一个空格隔开,表示一个区域的起始点和终止点的坐标。
输出格式:
1 个整数,表示马路上剩余的树的数目。
[Noip普及组2005年]
津津上初中了。妈妈认为津津应该更加用功学习,所以津津除了上学之外,还要参加妈妈为她报名的各科复习班。另外每周妈妈还会送她去学习朗诵、舞蹈和钢琴。但是津津如果一天上课超过八个小时就会不高兴,而且上得越久就会越不高兴。假设津津不会因为其它事不高兴,并且她的不高兴不会持续到第二天。请你帮忙检查一下津津下周的日程安排,看看下周她会不会不高兴;如果会的话,哪天最不高兴。
输入输出格式
输入格式:
输入包括 7 行数据,分别表示周一到周日的日程安排。每行包括两个小于 10 的非负整数,用空格隔开,分别表示津津在学校上课的时间和妈妈安排她上课的时间。
输出格式:
一个数字。如果不会不高兴则输出 0,如果会则输出最不高兴的是周几(用 1, 2, 3, 4, 5, 6, 7分别表示周一,周二,周三,周四,周五,周六,周日)。如果有两天或两天以上不高兴的程度相当,则输出时间最靠前的一天。
[Noip普及组2004年]
某校的惯例是在每学期的期末考试之后发放奖学金。发放的奖学金共有五种,获取的条件各自不同:
院士奖学金,每人8000元,期末平均成绩高于80分(>80),并且在本学期内发表11篇或11篇以上论文的学生均可获得;
五四奖学金,每人4000元,期末平均成绩高于85分(>85),并且班级评议成绩高于80分(>80)的学生均可获得;
成绩优秀奖,每人2000元,期末平均成绩高于90分(>90)的学生均可获得;
西部奖学金,每人1000元,期末平均成绩高于85分(>85)的西部省份学生均可获得;
班级贡献奖,每人 850 元,班级评议成绩高于80分(>80)的学生干部均可获得;
只要符合条件就可以得奖,每项奖学金的获奖人数没有限制,每名学生也可以同时获得多项奖学金。例如姚林的期末平均成绩是87分,班级评议成绩82分,同时他还是一位学生干部,那么他可以同时获得五四奖学金和班级贡献奖,奖金总数是4850元。
现在给出若干学生的相关数据,请计算哪些同学获得的奖金总数最高(假设总有同学能满足获得奖学金的条件)。
输入输出格式
输入格式:
第一行是 1 个整数 N(1\(\le\)N$\le$100),表示学生的总数。
接下来的 N 行每行是一位学生的数据,从左向右依次是姓名,期末平均成绩,班级评议成绩,是否是学生干部,是否是西部省份学生,以及发表的论文数。姓名是由大小写英文字母组成的长度不超过 20的字符串(不含空格);期末平均成绩和班级评议成绩都是0到100之间的整数(包括 0 和 100 );是否是学生干部和是否是西部省份学生分别用1个字符表示,Y表示是,N表示不是;发表的论文数是0到10的整数(包括 0 和 10 )。每两个相邻数据项之间用一个空格分隔。
输出格式:
包括 3 行。
第 1 行是获得最多奖金的学生的姓名。
第 2 行是这名学生获得的奖金总数。如果有两位或两位以上的学生获得的奖金最多,输出他们之中在输入文件中出现最早的学生的姓名。
第 3 行是这 N 个学生获得的奖学金的总数。
提示: 名字用字符数组,scanf %s输入,printf %s输出
[Noip提高组2005年]
标签:a+b 报名 得奖 全局 二进制 tps 十六 部分 任务
原文地址:https://www.cnblogs.com/eqvpkbz/p/9484244.html