标签:好用 var fun 习惯 不用 insert 复制 查找 date()
常用的SQL 由浅入深
大致上回想一下自己常用的SQL,并做个记录,目标是实现可以通过在此页面查找到自己需要的SQL ,陆续补充 有不足之处,请提醒改正
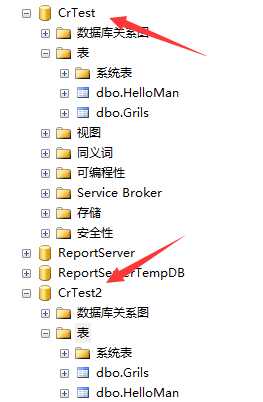
首先我创建了两个库,每个库两张表.(工作的时候,每个公司最好有自己的数据库模型,产品也可以看,模型工具一般用PD(power designer)什么的,用起来简单规范方便,建议萌新学习)
 ·
·
第二个库crtest2是复制第一个crtset的 复制表的方法为右键--》编写脚本--》打开库2的窗口复制(建议瞟一眼脚本,执行不成功的 脚本最上面数据库改成目标数据库)
1.增删改查
查:程序员最主要的技能 有很多方法 这里由浅入深讲一下
select 字段名 from 表名 (*代表查一个表的所有字段,其实不建议具体开发查全部,用哪个字段查哪个,*号的效率太慢,耗性能,优化的一部分)
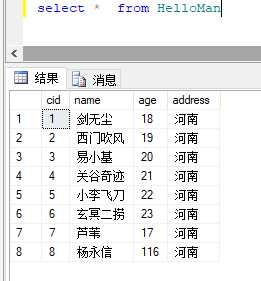
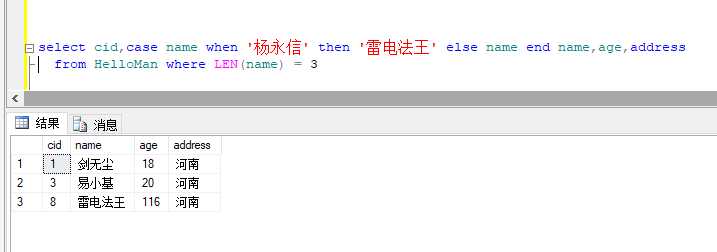
查三个字名字的人,并把name= 杨永信 的输出为 雷电法王,这一手是为了使用一下case when (碰到条件查询不要着急,一步步来,先确保数据逻辑的正确性,写好后,再去优化SQL)(美化SQL用Navicat Premium,SQL format,SQL Beautifier等等,这三个亲测好用)
case when .. then .. else ..end 就当做 if ...else....来用就行
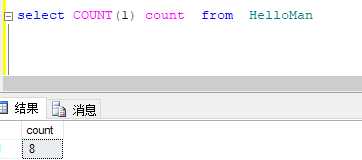
查数据量,不建议用 count(*),换成count(字段名),没有字段名的约束 用 count(1)来查,执行速度截然不同
连表查询,超过两个表以上的连表查询,一定要记得大表在前小表在后。实际情况里 inner join,left join使用的比较多,这里做一下区分,到底什么时候用inner,什么时候用left
网上也有很多,说的太官方,容易迷。这里我通俗的讲一讲
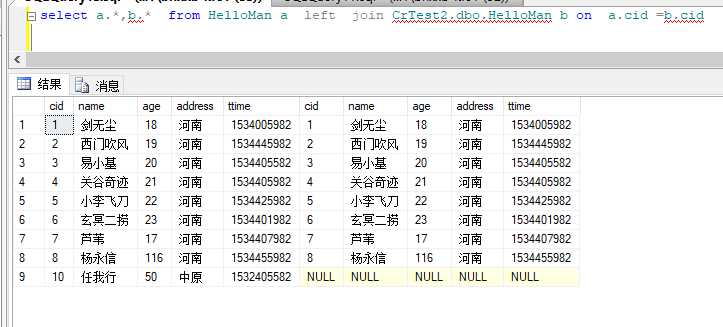
left join:左联合 就是说两个表关联 左边的是大哥,一切以大哥为准,大哥表的数据无条件全部返回,其他表跟大哥对应的数据,大哥也全都要 (所以一般来说,left比inner的数据量要多)
inner join:内联合 两个表是拜把子 互相谦让,你有我也有的数据才要,取共同点
语法: select * from A表 left join B表 on a.id = b.id 很简单
跨库查询也是一样,这里我查crtest 和crtest2 两个库的HelloMan表的联合查询,很简单,看一下
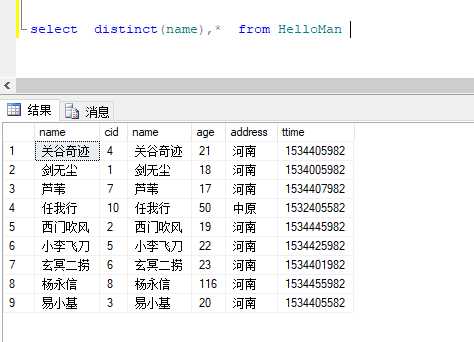
去重
SQL去重一般用distinct,group by这两种方法,介绍一下
distinct: select distinct(字段名) from 表名 where 条件
group by:select 字段 from 表名 group by 字段 having 条件
使用 group by的时候 用having语法 而不是where (本人倾向于group by,因为它不仅仅是去重查找,删重,条件嵌套可以一起写,功能多一些吧。 )
ROW_NUMBER()函数
这个ROW_NUMBER(),在数据库执行的时候有点耗性能,但它的任务多数情况下是用来提升性能的。奇怪吧,往下看看
你可以帮他当做成分组函数或是分析函数
刚接触.NET的时候。大家对GridView,Repeater这些控件很熟悉吧。数据量多的时候我们使用了分页,但是一般的是直接绑定数据源的分页,又称为假分页,还是一次性从数据库里select这些数据。但是用ROW_NUMBER() 就可以做成真分页,每次都只差Pagesize条数据。提升了性能速度吧。
语法:ROW_NUMBER() over(order by 字段名 desc)
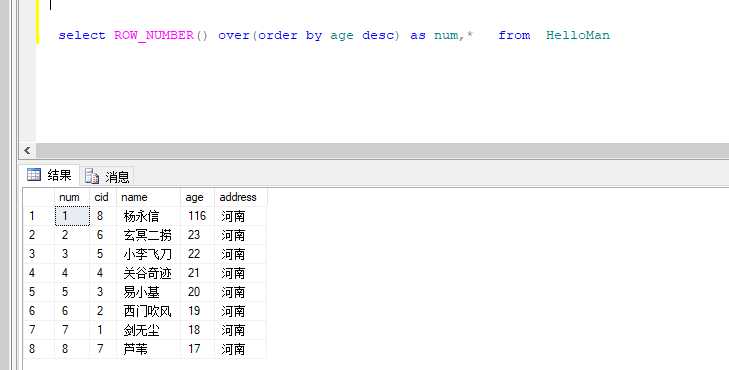
看到了吧,多了个排序字段 在where一下 真分页就OK了嘛
假设我们想查一个商场一个时间段内,第88位消费的顾客的信息。嘿嘿,一步到位的话也可以写,不用ROW_NUMBER()的函数还真的不好写。用ROW_NUMBER()就好多了
回到我们的测试表 对着上面 我们查一下年龄段在15-25,四个字名字,排名第二高的武林高手(武林排名按照各自的cid来算,剑无尘第一,因为数据少我们能从上面提前看出答案,是关谷),SQL如下:
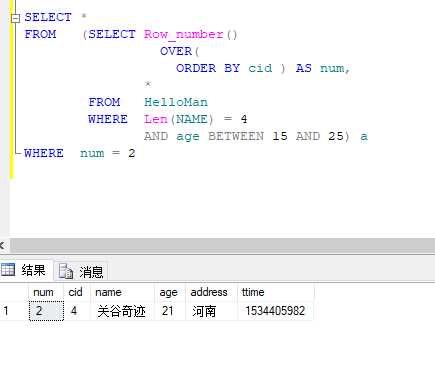
先分组,再寻找 简单的很
模糊查询
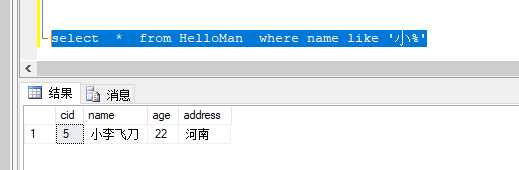
很简单,一看便知 这里说一下我们经常用的通配符为 %% ,但是还有一些 像 like ‘_ a_‘ ,like ‘[a]b‘ 这种的 也是通配符,LZ觉得看关键字Like就完事儿了。知道就行了不常用
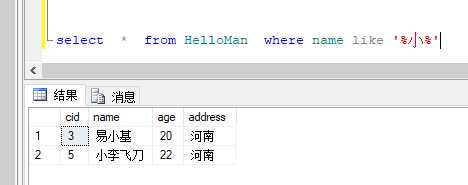
提一下,左右两边带 %,是两边都进行模糊匹,只放在左边是左边匹配,右边同理,一看便知
时间日期函数
convert() date() 大家可以去这来看看学习 http://www.w3school.com.cn/sql/func_convert.asp
写的全面,很好,这里我就不写了
数据格式转换,时间戳
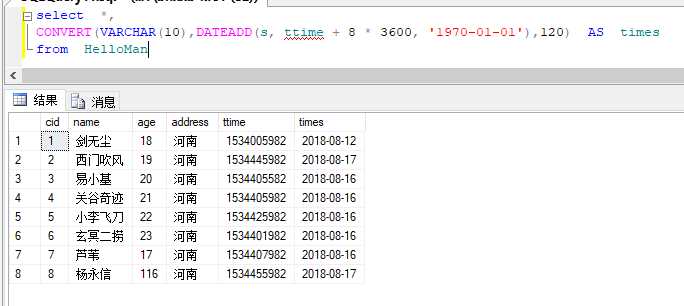
时间戳:就是linux的时间 好一点的数据库储存时间的字段都是用时间戳存的,int类型,安全,占用空间小, 简单查看时间戳 https://tool.lu/timestamp/
方法: CONVERT(VARCHAR(10),DATEADD(s, ttime + 8 * 3600, ‘1970-01-01‘),120) AS times (这里我又在测试表里又加了个ttime字段,用来存时间戳,取出来的时候用这个函数转换成时间,精确度自己设置)
convert() 在SQL中convert()函数除了转时间还可以进行其他格式的转换,最常用的就是钱,money,decimal类型,还有如果数据库是varchar类型之类的,然后你扔进来的是int,dateteime之类的就需要convert()转换一下,很简单
格式: convert(要转的类型,要转的数据) 例如: CONVERT(VARCHAR(50),tid) tid是int型转成varchar,很简单
说到这里要熟练使用 IsNULL()函数,加减乘除都要外面包一层IsNull()函数
格式:IsNull(数据,默认值) 例如 ISNULL(sum,0) as sum
先写到这里,差不多够用,有时间的话lz会补充的,总结写复杂的SQL不一定需要会那些新颖或者太复杂的函数,按照逻辑一点点的来,分步查,慢慢提高自己SQL。
2.删除,更新
写删除更新语句一定要写where,养成好习惯
update 表名 set 字段名=‘...’ where (1=1)
delete from 表名 where (1=1)
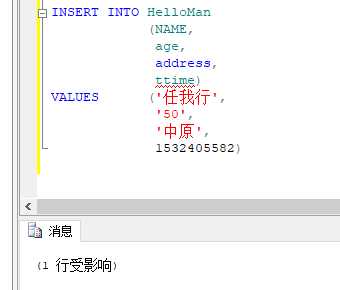
3.增加
insert into 表名(字段名) values (增加数据)
接下来,会写一篇,thousand级别的数据库的批量插入,本人自己理解的萌新入门的存储过程,触发器,SQL的事物以及有关表数据量太大的优化解决方案,很简单,大佬请无视。
通过简单的两句代码,慢慢发现编程的乐趣
标签:好用 var fun 习惯 不用 insert 复制 查找 date()
原文地址:https://www.cnblogs.com/cr-cool/p/9488581.html