标签:tin one oid 机制 dict 电脑 交换 sync 消费者

神马是消息队列,看看某度的原话“在项目中,将一些无需即时返回且耗时的操作提取出来,进行了异步处理,而这种异步处理的方式大大的节省了服务器的请求响应时间,从而提高了系统的吞吐量”。
其实消息队列还可以用于解耦,在多层项目模型或中型项目以上,都会用到消息队列,减少层与层之间的耦合;还可以做跨进程间的通讯(传输率显然比不上RPC)。
上一节说道最终需要采用消息队列来进行分离前级和后级,并且采用异步方式,用于提高业务服务器的吞吐率,不过,虽然分离了,如果后级服务器的处理能力达不到请求数或接近平衡,那么分离也是无用的,甚至会影响整个系统的执行效率。比如这样
1台业务逻辑服务器 => 生产消息 => 消息服务器 => 消费者(处理)
其实就等同于:
1台业务逻辑服务器 => 消费者(处理)
或者换一种场景:
一个银行有多个窗口,但目前只打开了一个窗口进行服务,我们假设这个窗口的服务人员是每半小时完成一个用户,如果有10个用户,那么就是10*30=300分钟,最后一个用户需要排队对待270分钟后才轮到他到窗口,这是多么荒唐的事情(很多服务行业的通病),用户肯定会非常的不耐烦。如果我们再增开3个闲置的窗口,并且配上相应的服务人员,一次接待4位客人,那么这个时间将会缩短3倍,变成只需要90分钟即可轮到他。
在这个场景中,增设窗口就属于水平扩展,而不是督促服务人员提高工作效率、这种垂直扩展来提高整体效率(毕竟不管是机器还是人,都有极限)。服务器消息队列中的消费者也是如此,并且相同类型(或处理逻辑相同)的扩展完全属于傻瓜化的,可比增设窗口简单多了。
在来看一下上一节中的最后一张图片:
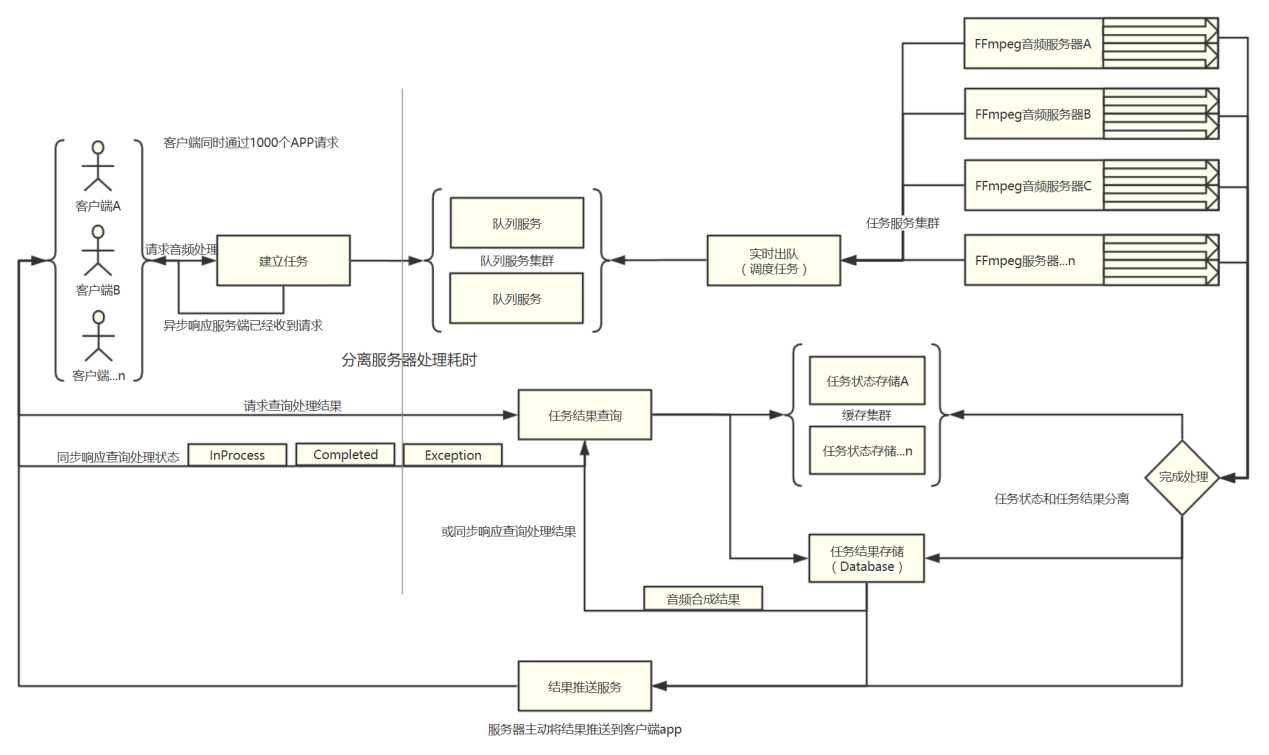
“FFmpeg服务器...n”就属于傻瓜式的水平扩展,想想一下:同一份代码,部署到不同的服务器上面,是不是特别的轻松。
rabbitmq的安装这里就不介绍了,先搞清楚他是一个AMQP标准即可,由于我们这个项目只涉及到一个处理逻辑——音频处理,而不讨论与其他项目相关,所以我们将交换机Exchange,队列Queue,路由关键字Routing Key均设为直连一根线通到底,无需中间做任何交换,当然也不需要交换机进行广播fanout,完全的direct即可。
去重(重复消费)的问题:
ribbitmq利用ack机制来确定消息的可靠性,但是需要消费端完全完成这条消息后才会做出应答,这样便会造成消费不等,即一个还在处理消费,而另一也紧跟着处理这个消费。一般出在任务超时,或者没有及时返回状态,引起任务重新入队列,重新消费,在rabbtimq里连接的断开也会触发消息重新入队列,解决方案有很多,也可以参考幂等性方法。
将一条消息做一个唯一的标签,例如GUID,每次在处理前先判断这个标签的状态是否被处理,如果已被处理,该消费端就放弃这条消息。
废话不多,开始:
首先我们需要创建一个任务,这个任务可以是个标识,也可以是一个存储,但任务名称必须是唯一(ID)的,用随机字符串生成一组唯一ID,笔者提供一个方法,供大家参考:

1 ///<summary> 2 ///生成随机字符串 3 ///</summary> 4 ///<param name="length">目标字符串的长度</param> 5 ///<param name="useNum">是否包含数字,1=包含,默认为包含</param> 6 ///<param name="useLow">是否包含小写字母,1=包含,默认为包含</param> 7 ///<param name="useUpp">是否包含大写字母,1=包含,默认为包含</param> 8 ///<param name="useSpe">是否包含特殊字符,1=包含,默认为不包含</param> 9 ///<param name="custom">要包含的自定义字符,直接输入要包含的字符列表</param> 10 ///<returns>指定长度的随机字符串</returns> 11 public static string GetRandomString(int length, bool useNum, bool useLow, bool useUpp, bool useSpe, 12 string custom) 13 { 14 byte[] b = new byte[4]; 15 new System.Security.Cryptography.RNGCryptoServiceProvider().GetBytes(b); 16 Random r = new Random(BitConverter.ToInt32(b, 0)); 17 string s = null, str = custom; 18 if (useNum == true) 19 { 20 str += "0123456789"; 21 } 22 23 if (useLow == true) 24 { 25 str += "abcdefghijklmnopqrstuvwxyz"; 26 } 27 28 if (useUpp == true) 29 { 30 str += "ABCDEFGHIJKLMNOPQRSTUVWXYZ"; 31 } 32 33 if (useSpe == true) 34 { 35 str += "!\"#$%&‘()*+,-./:;<=>?@[\\]^_`{|}~"; 36 } 37 38 for (int i = 0; i < length; i++) 39 { 40 s += str.Substring(r.Next(0, str.Length - 1), 1); 41 } 42 43 return s; 44 }
再建立一个接口,用于接受来自客户端的请求,根据请求异步创建一个任务,并将任务名称返回到请求客户端。
1 var taskName = AudioParamFactory.GetRandomString(8, true, true, true, false, null); 2 3 _iMsgBusService.Pubilsh(JsonConvert.SerializeObject(new 4 { 5 frontFileUrl, 6 backgounedAudioIndex, 7 taskName 8 }), DispatchEndpoint.Media);
上述代码中直接就两句话,一:建立一个任务名称;二:将消息发送到名为“media”的队列中。
为何创建连接,创建通道,配置等等都没有呢,这是因为在easyHub的框架中已经做好了,偷会懒吧o(∩_∩)o 。
通过请求8次,那么Media队列中将存在8条消息,如图所示:
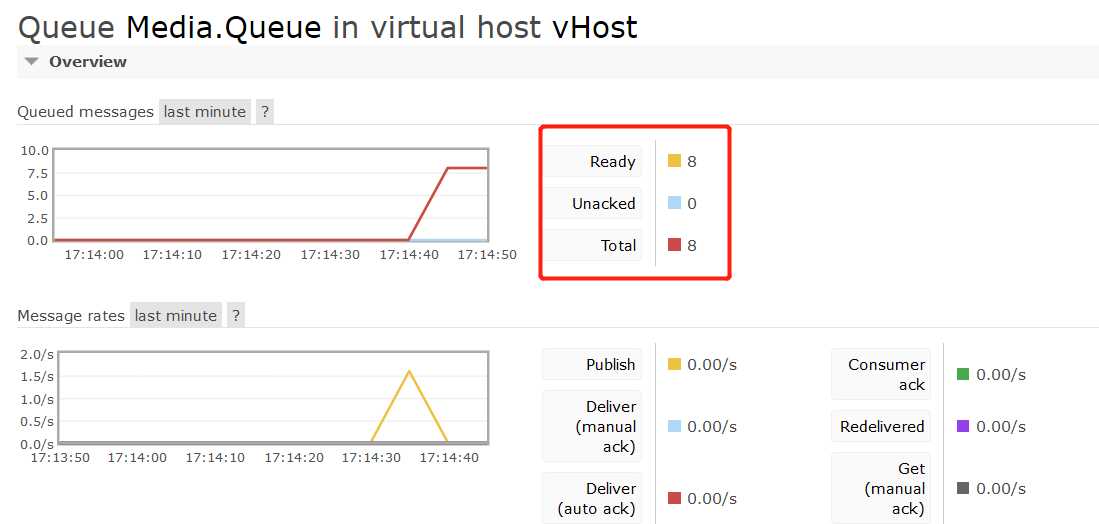
当消费完成,处理应答是必须的,否则这条消息会永远的存在消息服务器中。
1 public void DoStart() 2 { 3 // 1:从消息队列中取得需要处理的音频消息 4 Consumer consumer = new Consumer(MqConfig.MeidaQueueName); 5 var channel = consumer.Channel; 6 consumer.ReceivedEvent += (sender, args) => 7 { 8 var msg = Encoding.UTF8.GetString(args.Body); 9 Console.WriteLine(args.RoutingKey + "\r\n" + msg); 10 Console.WriteLine(); 11 12 // 2:执行同步处理(一次只调用一个同步处理单元) 13 var nonObj = JsonConvert.DeserializeObject<Dictionary<string, object>>(msg); 14 var nonBoy = JsonConvert.DeserializeObject<dynamic>(nonObj["Body"].ToString()); 15 string forntFileUrl = nonBoy.frontFileUrl; 16 int backgounedAudioIndex = nonBoy.backgounedAudioIndex; 17 string taskName = nonBoy.taskName; 18 // 调用同步方法 19 var r = SynthesisAudio(forntFileUrl, backgounedAudioIndex, taskName); 20 Console.WriteLine(r.GetType()); 21 Console.WriteLine(typeof(AudioSynthesisSyncResult)); 22 if (r.GetType() == typeof(AudioSynthesisSyncResult)) 23 { 24 // 3:处理完成,应答队列服务器 25 channel.BasicAck(args.DeliveryTag, false); 26 Console.WriteLine(taskName); 27 Console.WriteLine("handler done, wait for the next message..."); 28 } 29 else 30 { 31 // 出现处理错误,则该条消息不做应答,并发送错误 32 var error = ((JsonResult) r); 33 Console.WriteLine(error.StatusCode); 34 Console.WriteLine(error.Value); 35 } 36 }; 37 }
当任务进入到消息队列,其实就和当时的请求是没有任何联系的了,这样来理解异步也不错,所以我们需要将任务的状态进行分类存储,以告诉客户端在查询的时候,当前的任务进行到哪一步了,我们可以用枚举的方式来罗列:
1 public enum AudioProcessingState 2 { 3 EmptyHandler = 0, 4 StartHandler = 1, 5 DownloadAudio = 2, 6 SynthesisAudio = 3, 7 UploadAudio = 4, 8 UpdateDatabase = 5, 9 HandlerException = 6, 10 InCompleted = 7 11 }
笔者提供的任务状态有8种,具体时候请根据自己的业务逻辑进行区分,很简单,就是前面画的那张垂直流程图,不解释。
当然,如果你把所有任务状态都存到数据库,那么将会有个问题,这数据库面对轮询的压力有点吃力,所以最好还是放到缓存中,至于喜欢放什么缓存,这个根据业务场景和现有的而定,千万别放本地缓存就行。
对了,状态放缓存,而结果需要放数据库,这是原则问题。
接下来我们在创建一个提供查询的接口,这里实际就是查询缓存而已,如果状态是InCompleted,就直接从数据库取结果,因为非常的简单,笔者就不放代码上来了。
不过有朋友喜欢将结果进行推送到客户端,这也是非常好的,而且相比轮询,推送更能减少服务器压力。
为了验证结果,笔者前前后后进行了多次的测试,在I7-2700K的WIN10上面模拟了多台服务器,看看这截图:

能分离的全都分离,包括请求和查询也单列一台服务器。
经过测试,笔者通过模拟请求8个任务,采用逐级增加服务的方式,得到了如下的结果:
| 单机 | 最快(最早入队)/ms |
最慢(最晚入队)/ms |
| 第一次 | 3241 | 19430 |
| 第二次 | 3271 | 19592 |
| 第三次 | 4564 | 19227 |
| 两台 | ||
| 第一次 | 4058 | 9819 |
| 第二次 | 3146 | 9014 |
| 第三次 | 4033 | 8798 |
| 三台 | ||
| 第一次 | 3880 | 9830 |
| 第二次 | 3477 | 7700 |
| 第三次 | 3182 | 6993 |
| 六台 | ||
| 第一次 | 3709 | 4800 |
| 第二次 | 3313 | 4773 |
| 第三次 | 3182 | 4793 |
最早入队的任务时间基本锁定在3-4s,为何会有这么大的波动,毕竟笔者的电脑不是真正的服务器电脑。而反观最晚入队的任务,在单机模式上,达到了19s,随着逐级的增加服务(笔者电脑开6个已经吃不消了),达到了不到5s,整体时间缩短了近4倍,结果非常令人满意。
下一节将介绍在NETCORE中如何使用中间件自动启动任务调度,而不是采用quartz中间件。
感谢阅读
使用.NET Core搭建分布式音频效果处理服务(五)利用消息队列提升水平扩展灵活性
标签:tin one oid 机制 dict 电脑 交换 sync 消费者
原文地址:https://www.cnblogs.com/SteveLee/p/9490914.html
