标签:pymysql pre col 包含 链接 错误 iter type ams
首先确定要爬取的笑话网站,我是直接百度笑话搜到的第一个网站,网址是http://www.jokeji.cn/,点进去发现网页构建在我看来还是比较复杂的,由于还是初学者,首先得先找到网页资源集中所在,找出其中的规律,然后才好有针对性的爬取资源。对于这个网址,我发现在左边侧栏有一个笑话大全的分类框。这个看起来基本上包括了全站的文字笑话了。在这个分类框下有许多小的分类,点进小的分类后是此分类下的所有笑话网页列表,每个网页里面包含一些笑话,我们最终是要把这一个一个网页里的笑话爬取存储起来。
爬取思路:爬取http://www.jokeji.cn/,得到一个html页面,分析此html页面,获得分类框里的所有分类的url地址,遍历每一个分类的url,爬取分类url的html网页,分析分类url网页,得到全部笑话网页列表,遍历笑话网页列表url,得到最终的包含一个一个笑话的html页面,获取笑话,存储到mysql数据库。
爬取我用的是Google浏览器,在这个网站下按F12就可以看到网页源代码了,此时要分析这个笑话大全的分类框的结构,以便使用python正则表达式获取到我们想要的信息。
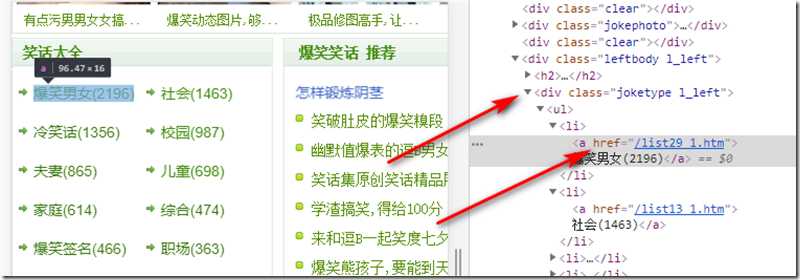
一般筛选内容都会选择目标内容组件的上层容易唯一标识的组件,在这里我选择了<div class=”joketype l_left”></div>这个html,这个div可以包含所有分类的内容,然后再进行一次筛选就可以把所有url筛选出来了。到了分类子页面我看了一下url的规律,这个分类的url都是/listXX_1.htm开始,发现分类页面里面有个尾页的按钮的url刚好是结束,并且url的.htm前面的那个数字递增,所以就很好爬取所有笑话页面了,至于提取笑话就不再多说了,直接上所有代码。
mysql数据库存储模块代码,文件名为mysql.py。
import pymysql def insert(joke): #获取链接 conn=pymysql.connect(host=‘127.0.0.1‘,user=‘root‘,passwd=‘123456‘,db=‘python‘) cur=conn.cursor() #sql语句,%s是占位符(%s是唯一的,不论什么数据类型都使用%s)防止sql注入 sql=‘insert into joke(joke) VALUES(%s)‘ #params=(‘eric‘,‘wuhan‘) #参数 插入单条 #li=[(‘a1‘,‘b1‘),(‘a2‘,‘b2‘)] #批量插入参数 #reCount=cur.execute(sql,params) reCount=cur.executemany(sql,joke) #批量插入 conn.commit() #提交,执行多条命令只需要commit一次就可以 cur.close() conn.close() def get_one(): #获取链接 conn=pymysql.connect(host=‘127.0.0.1‘,user=‘root‘,passwd=‘123456‘,db=‘python‘) cur=conn.cursor() sql1=‘select number from number‘ reCount=cur.execute(sql1) number=cur.fetchone()[0]+1 sql2=‘select joke from joke where id=%s‘ reCount=cur.execute(sql2,number) joke=cur.fetchone()[0] sql3=‘update number set number=%s where number=%s‘ params=(number,number-1) reCount=cur.execute(sql3,params) conn.commit() cur.close() conn.close()
注意:pymysql模块是需要安装的,一般现在python都默认有pip包管理,没有这个模块直接在命令行执行:pip pymysql即可。需事先在mysql数据库里创建python数据库,表joke,表有两列,一列是id,我设置其为int类型的自增的主键属性,一列joke,设置为text类型,存放笑话。insert函数是传入一个joke的tuple类型参数,这个tuple里面存放是一条一条字符串,每条字符串表示一个笑话,insert函数的功能是将这个tuple元组的笑话插入到数据库。get_one函数是得到一条笑话,在这里我添加一个表专门来保存笑话取到哪了,以免读取重复笑话,这个表名字是number,里面有一个字段,number,我实现插入了一条记录,值为0。
爬虫代码,文件名为spider.py。
import urllib from urllib import request import re import chardet import mysql import time ‘‘‘ 找到http://www.jokeji.cn/list29_1.htm笑话列表 获取第一个笑话网页http://www.jokeji.cn/jokehtml/bxnn/2018080417455037.htm 遍历完所有笑话网页 获取下一个笑话列表,重复遍历,直至此分类笑话遍历完 遍历下一个分类 ‘‘‘ class Spider(): url=‘http://www.jokeji.cn/jokehtml/bxnn/2018073023294432.htm‘ header = { ‘User-Agent‘:‘Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Mobile Safari/537.36‘, ‘Accept-Encoding‘: ‘‘, ‘Referer‘:‘http://www.jokeji.cn/list29_1.htm‘ } classifys=[] #list集合,存储笑话分类url #获取html文本 def __fetch_content(self): cookie_html = request.Request(Spider.url,headers=Spider.header) cookie_html = request.urlopen(cookie_html) htmls=cookie_html.read() #使用chardet获取到htmls的编码格式 encoding=chardet.detect(htmls) encoding=encoding[‘encoding‘] #不加ignore的时候总是出现字符转换错误,说明有非法字符,必须加上ignore忽略非法字符 htmls=htmls.decode(encoding,‘ignore‘) time.sleep(0.1) return htmls #获取笑话分类url def __analysis_classify(self): Spider.url=‘http://www.jokeji.cn/‘ Spider.header[‘Referer‘]=‘http://www.jokeji.cn/‘ htmls=self.__fetch_content() root_pattern=‘<div class="joketype l_left">([\s\S]*?)</div>‘ classify_pattern=‘<a href="([\s\S]*?)">‘ root_html=re.findall(root_pattern,htmls) Spider.classifys=re.findall(classify_pattern,str(root_html)) #获取当前页面里的所有笑话,返回一个tuple def __analysis(self,htmls): anchors=[] root_pattern=‘<span id="text110">([\s\S]*?)</span>‘ juck_pattern=‘<P>\d、([\s\S]*?)</P>‘ root_html=re.findall(root_pattern,htmls) for html in root_html: jucks=re.findall(juck_pattern,html) #替换换行符 c=re.compile(‘<[b|B][r|R]\s*/*>‘) for i in jucks: i=c.sub(‘\n‘,i) anchors.append(i) #i=i.replace(‘<BR>‘,‘\n‘) return anchors return anchors #爬取原创笑话 def __analysis_yuanchuangxiaohua(self,url): url=‘http://www.jokeji.cn‘+url pass #爬取分类下的笑话 def __analysis_joke(self): Spider.header[‘Referer‘]=‘http://www.jokeji.cn/‘ root_pattern=‘<div class="list_title">([\s\S]*?)</div>‘ page_pattern=‘<a href="([\s\S]*?)"\s*target="_blank"\s*>‘ for classify in Spider.classifys: try: if ‘/yuanchuangxiaohua‘ in classify: self.__analysis_yuanchuangxiaohua(classify) classify=‘http://www.jokeji.cn‘+classify Spider.url=classify htmls=self.__fetch_content() #记录分类里面最大页面数 max_number=int(re.findall(‘[\s\S]*?(\d*?)\.htm">尾页</a>‘,htmls)[0]) #开始遍历每一大页,一大页包含很多小页面,小页面里面才是笑话 except BaseException: continue for bigpage_number in range(1,max_number+1): try: bigpage_url=classify temp=re.compile(‘(\d*).htm‘) #更改url,因为分类下每一大页都是有规律的,都是.htm前面的数字从1加到最大页面数 bigpage_url=temp.sub(str(bigpage_number)+‘.htm‘,bigpage_url) #替换url Spider.url=bigpage_url htmls=self.__fetch_content() root_html=re.findall(root_pattern,htmls) #获取一大页里面的小页面的url地址 pages=re.findall(page_pattern,root_html[0]) #遍历所有小页面url,获取其中的笑话 except BaseException: continue for page in pages: try: Spider.url=‘http://www.jokeji.cn‘+page htmls=self.__fetch_content() tuples=self.__analysis(htmls) #插入到数据库 mysql.insert(tuples) except BaseException: continue def go(self): self.__analysis_classify() self.__analysis_joke() spider=Spider() spider.go()
由于笑话分类里的原创笑话的页面格式不同,所以就差这个还没实现。初学,第一次写博客记录,下载了编写博客的openLiveWriter发现很难用,还是用网页写好一点。
标签:pymysql pre col 包含 链接 错误 iter type ams
原文地址:https://www.cnblogs.com/tanjianyong/p/9495591.html