标签:输出 softmax 输入 tail 分享图片 bsp center 特征提取 还需
全连接神经网络(Fully connected neural network)处理图像最大的问题在于全连接层的参数太多。参数增多除了导致计算速度减慢,还很容易导致过拟合问题。所以需要一个更合理的神经网络结构来有效地减少神经网络中参数的数目。而卷积神经网络(Convolutional Neural Network,CNN)可以做到。
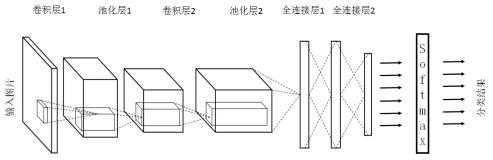
图 1:卷积神经网络
整个网络的输入,一般代表了一张图片的像素矩阵。图 1中最左侧三维矩阵代表一张输入的图片,三维矩阵的长、宽代表了图像的大小,而三维矩阵的深度代表了图像的色彩通道(channel)。黑白图片的深度为 1,RGB 色彩模式下,图片的深度为 3。
CNN 中最为重要的部分。与全连接层不同,卷积层中每一个节点的输入只是上一层神经网络中的一小块,这个小块常用的大小有 3×3 或者 5×5。一般来说,通过卷积层处理过的节点矩阵会变的更深。
池化层不改变三维矩阵的深度,但是可以缩小矩阵的大小。池化操作可以认为是将一张分辨率高的图片转化为分辨率较低的图片。通过池化层,可以进一步缩小最后全连接层中节点的个数,从而到达减少整个神经网络参数的目的。池化层本身没有可以训练的参数。
经过多轮卷积层和池化层的处理后,在CNN的最后一般由1到2个全连接层来给出最后的分类结果。经过几轮卷积和池化操作,可以认为图像中的信息已经被抽象成了信息含量更高的特征。我们可以将卷积和池化看成自动图像提取的过程,在特征提取完成后,仍然需要使用全连接层来完成分类任务。
对于多分类问题,最后一层激活函数可以选择 softmax,这样我们可以得到样本属于各个类别的概率分布情况。
卷积神经网络结构中最重要的部分,过滤器(filter),如图 2中黄色和橙色的 3×3×3 矩阵所示。具体卷积操作如何进行,可以参考 Convolutional Neural Networks (CNNs / ConvNets) 中的 Convolution Demo 或者参考图 3。
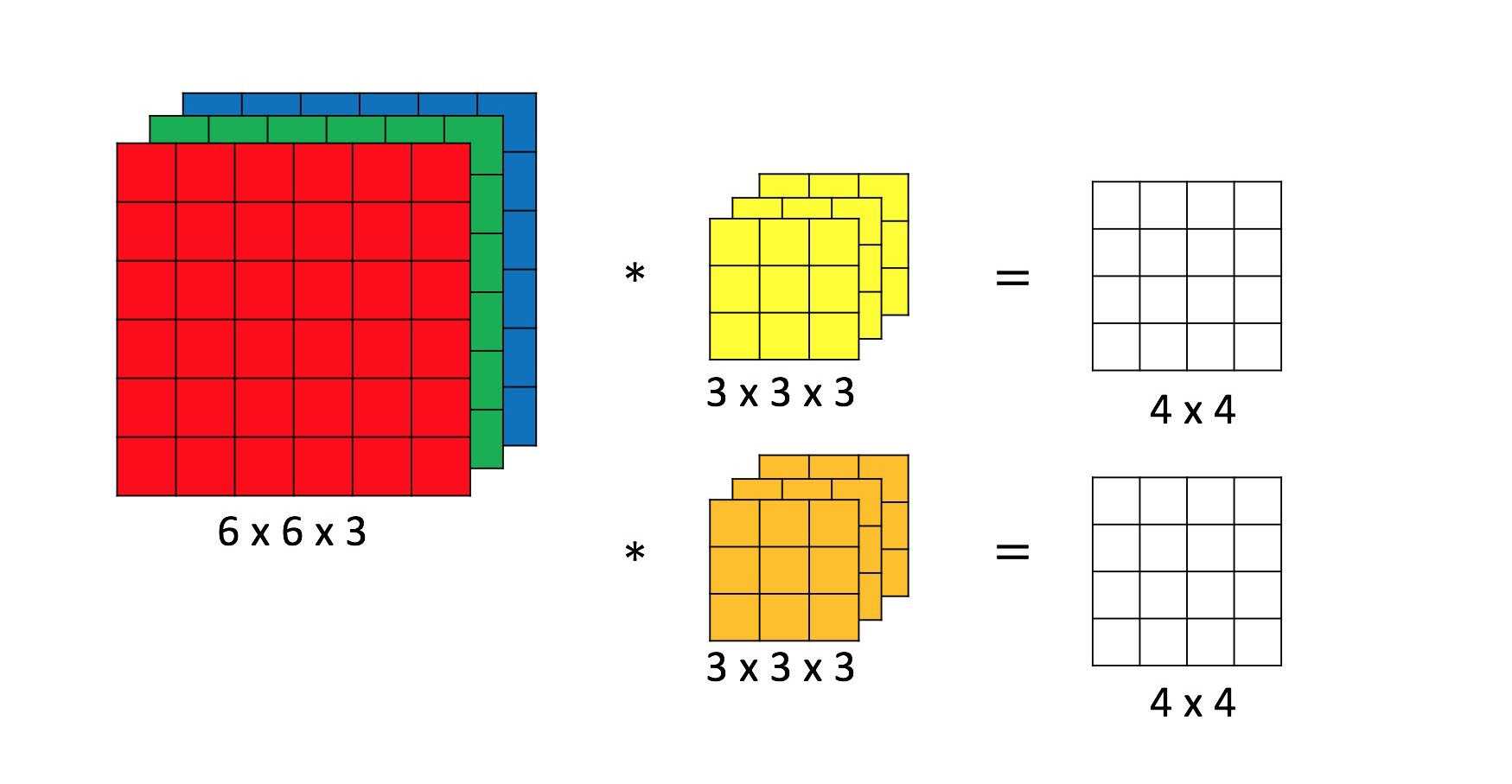
图 2:卷积操作
filter 可以将当前层神经网络上的一个子节点矩阵转化为下一层神经网络上的一个单位节点矩阵。单位节点矩阵制的是长和宽都是 1,但深度不限的节点矩阵。
进行卷积操作,需要注意 filter 的个数 $K$、filter 的尺寸 $F$、卷积步长 stride 的大小 $S$ 以及 padding 的大小 $P$。图 2 中 $K = 2$,$F = 3$,$S = 1$,$P = 0$。
常用的 filter 尺寸有 3×3 或 5×5,即图 2 黄色和橙色矩阵中的前两维,这个是人为设定的;filter 的节点矩阵深度,即图 2 黄色和橙色矩阵中的最后一维(filter 尺寸的最后一维),是由当前层神经网络节点矩阵的深度(RGB 图像节点矩阵深度为 3)决定的;卷积层输出矩阵的深度(也称为 filter 的深度)是由该卷积层中 filter 的个数决定,该参数也是人为设定的,一般随着卷积操作的进行越来越大。
图 2中 filter 的尺寸为 3×3×3,filter 的深度为 2。
卷积操作中,一个 3×3×3 的子节点矩阵和一个 3×3×3 的 filter 对应元素相乘,得到的是一个 3×3×3 的矩阵,此时将该矩阵所有元素求和,得到一个 1×1×1 的矩阵,将其再加上 filter 的 bias,经过激活函数得到最后的结果,将最后的结果填入到对应的输出矩阵中。输出矩阵中第一个元素 $g(0, 0, 0)$ 的计算如下所示:
\begin{equation} g(0, 0, 0) = f( \sum_{x}^3\sum_{y}^3\sum_{z}^3a_{x,y,z} × w_{x,y,z}^{(0)} + b^{(0)} ) \end{equation}
公式(1)中,$a_{x,y,z}$ 表示当前层的一个子节点矩阵,即 6×6×3 矩阵中左上角 3×3×3 部分; $w_{x,y,z}^{(0)}$ 表示第一个 filter 的权重,即第一个 filter 每个位置的值;$b^{(0)}$ 表示第一个 filter 的偏置 bias,是一个实数;$f$ 表示激活函数,如 ReLU 激活函数。
“卷积层结构的前向传播过程就是通过将一个 filter 从神经网络当前层的左上角移动到右下角,并且在移动中计算每一个对应的单位矩阵得到的。”
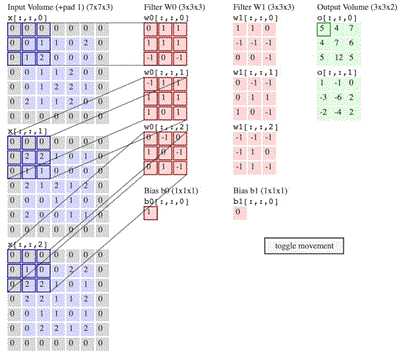
图 3:卷积操作流程
(注意:图 2 和 图 3 神经网络当前层输入不一样,图 2 是 6×6×3,而图 3 是5×5×3 再加上 $P = 1$ 的 padding。)
图 3 中,卷积步长 $S = 2$,padding的大小 $P = 1$。
padding,顾名思义,就是在图像周围进行填充,一般常用 zero padding,即用 0 来填充。当 $P = 1$ 时,在图像周围填充一圈;当 $P = 2$ 时,填充两圈。
Q: Why padding?
A: Two reasons: 1) shrinking output: 随着卷积操作的进行,图像会越来越小; 2) throwing away information from the edges of the images: filter 对图片边缘信息和内部信息的重视程度不一样,边缘信息 filter 只经过一次,而内部信息会被经过多次。
Q: Valid and Same convolutions?
A: "valid": no padding;
"Same": Pad so that output size is the same as the input size.
卷积步长 stride 就是像在图 3 中 filter 一次移动的步子,图 3 中 stride 的大小 $S = 2$。
卷积层输出矩阵的大小 $\mbox{size}_{output}$ 与输入图片大小 $N$、 filter 的尺寸 $F$、padding 的大小 $P$、卷积步长 $S$ 都有关。(假设输入的图片是方形的)
\begin{equation} \mbox{size}_{output}= \lfloor \frac{N + 2P - F}{S} \rfloor + 1\end{equation}
当 $ S \neq 1$ 时,可能存在 $\frac{N + 2P - F}{S}$ 不是整数的情况,这个时候对 $\frac{N + 2P - F}{S}$ 取下整或者使用整除。
依据《TensorFlow实战Google深度学习框架》,$\mbox{size}_{output}$ 也可以写成如下形势:
\begin{equation} \mbox{size}_{output}= \lceil \frac{N + 2P - F + 1 }{S} \rceil \end{equation}
公式(2)和(3)最后的结果会是一样。
池化层可以非常有效地缩小矩阵的尺寸(主要减少矩阵的长和宽,一般不会去减少矩阵深度),从而减少最后全连接层中的参数。“使用池化层既可以加快计算速度也有防止过拟合问题的作用。”
与卷积层类似,池化层的前向传播过程也是通过一个类似 filter 的结构完成的。不过池化层 filter 中的计算不是节点的加权和,而是采用更加简单的最大值或者平均值运算。使用最大值操作的池化层被称为最大池化层(max pooling),这是使用最多的池化层结构。使用平均值操作的池化层被称为平均池化层(average pooling)。
与卷积层的 filter 类似,池化层的 filter 也需要人工设定 filter 的尺寸、是否使用全 0 填充 以及 filter 移动的步长等设置,而且这些设置的意义也是一样的。
卷积层和池化层中 filter 的移动方式是相似的,唯一的区别在于卷积层使用的 filter 是横跨整个深度的,而池化层使用的 filter 只影响一个深度上的节点。所以池化层的过滤器除了在长和宽两个维度移动之外,它还需要在深度这个维度移动。也就是说,在进行 max 或者 average 操作时,只会在同一个矩阵深度上进行,而不会跨矩阵深度进行。
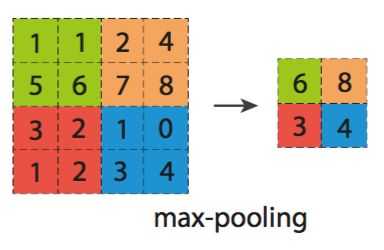
图 4:max pooling
图 4 中,池化层 filter 的尺寸为 2×2,即 $F = 2$,padding 大小 $P = 0$,filter 移动的步长 $S = 2$。
池化层一般不改变矩阵的深度,只改变矩阵的长和宽。
池化层没有 trainable 参数,只有一些需要人工设定的超参数。
图 2 中池化层拥有的 trainable 参数数目为 3×3×3×2+2,其中 “3×3×3” 表示 filter 的尺寸, “×2” 表示 filter 的深度/个数,“+2” 表示 2 个 filter 的 bias。卷积层的参数要远远小于同等情况下的全连接层。而且卷积层参数的个数和输入图片的大小无关,这使得卷积神经网络可以很好地扩展到更大的图像数据上。
Convolutional Neural Networks (CNNs / ConvNets)
Course 4 Convolutional Neural Networks by Andrew Ng
《TensorFlow实战Google深度学习框架》
卷积神经网络(Convolutional Neural Network,CNN)
标签:输出 softmax 输入 tail 分享图片 bsp center 特征提取 还需
原文地址:https://www.cnblogs.com/wuliytTaotao/p/9488045.html