标签:多用户 表达 要求 评分 情况下 也会 example 表达式 贝叶斯
目前主流的推荐算法主要包含内容关联算法, 协同过滤算法。
CB算法的原理是将一个item的基本属性, 内容等信息提取出来, 抽成一个taglist, 为每个tag赋一个权重。
剩下的事情就跟一个搜索引擎非常类似了, 将所有item对应的taglist做一下倒排转换, 放到倒排索引服务器中存储起来。
当要对某一个item做相关推荐的时候, 将这个item对应的taglist拿出来拼成一个类似搜索系统中的query表达式, 再将召回的结果做一下排序作为推荐结果输出。
当要对某个用户做个性化推荐的时候, 将这个用户最近喜欢/操作过的item列表拿出来, 将这些item的taglist拿出来并merge一下作为用户模型, 并将这个模型的taglist请求倒排索引服务, 将召回的结果作为候选推荐给该用户。
该算法的好处是:
该算法的坏处是:
CF算法的原理是汇总所有<user,item>的行为对, 利用集体智慧做推荐。其原理很像朋友推荐, 比如通过对用户喜欢的item进行分析, 发现用户A和用户B很像(他们都喜欢差不多的东西), 用户B喜欢了某个item, 而用户A没有喜欢, 那么就把这个item推荐给用户A。(User-Based CF)
当然, 还有另外一个维度的协同推荐。即对比所有数据, 发现itemA和itemB很像(他们被差不多的人喜欢), 那么就把用户A喜欢的所有item, 将这些item类似的item列表拉出来, 作为被推荐候选推荐给用户A。(Item-Based CF)
如上说的都是个性化推荐, 如果是相关推荐, 就直接拿Item-Based CF的中间结果就好啦。
该算法的好处是:
该算法的坏处是:
<user,item>行为数据, 即需要大量冷启动数据协同过滤算法具体实现的时候, 又分为典型的两类:
基于领域的协同过滤算法
这类算法的主要思想是利用<user,item>的打分矩阵, 利用统计信息计算用户和用户, item和item之间的相似度。然后再利用相似度排序, 最终得出推荐结果。
常见的算法原理如下:
User-Based CF
先看公式:
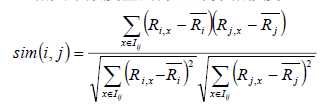
该公式要计算用户i和用户j之间的相似度, I(ij)是代表用户i和用户j共同评价过的物品, R(i,x)代表用户i对物品x的评分, R(i)头上有一杠的代表用户i所有评分的平均分, 之所以要减去平均分是因为有的用户打分严有的松, 归一化用户打分避免相互影响。
该公式没有考虑到热门商品可能会被很多用户所喜欢, 所以还可以优化加一下权重, 这儿就不演示公式了。
在实际生产环境中, 经常用到另外一个类似的算法Slope One, 该公式是计算评分偏差, 即将共同评价过的物品, 将各自的打分相减再求平均。
Item-Based CF
先看公式:
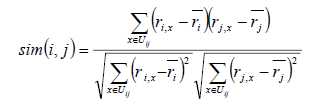
该公式跟User-Based CF是类似的, 就不再重复解释了。
这类算法会面临两个典型的问题:
基于此, 专家学者们又提出了系列基于模型的协同过滤算法。
基于模型的协同过滤算法
基于模型的研究就多了, 常见的有:
这儿只简单介绍一下基于矩阵分解的潜在语义模型的推荐算法。该算法首先将稀疏矩阵用均值填满, 然后利用矩阵分解将其分解为两个矩阵相乘, 如下图:
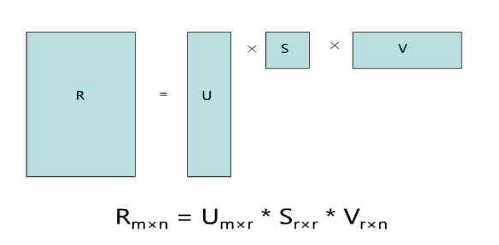
看一个实际的例子:
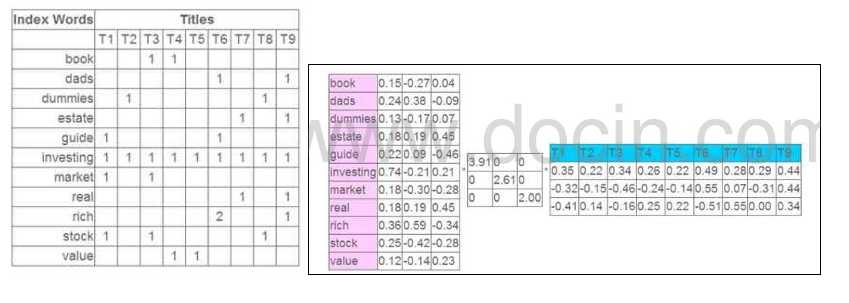
这个例子中, 原始矩阵中包含了网页的Title和切词后的term之间关系, 可以类比为推荐系统中的评分。然后用SVD做矩阵分解之后, 针对每个term会对应一个3维向量, 针对每个Title也会对应一个3维向量。
那么接下来可以做的事情就很多了, 如果要计算term和title的相似度, 只需要将这两个3为向量做内积得到的分值即可;
还可以将term和title都投影到这3维空间中, 然后利用各种聚类算法, 将用户和item, item和item, 用户和用户的分类都给求出来。
该算法的核心是在于做矩阵分解, 在矩阵大了的情况下计算量是非常夸张的, 在实际生产环境中会常用梯度递归下降方法来求得一个近似解。
组合推荐技术
其实从实践中来看, 没有哪种推荐技术敢说自己没有弊端, 往往一个好的推荐系统也不是只用一种推荐技术就解决问题, 往往都是相互结合来弥补彼此的不足, 常见的组合方式如下:
标签:多用户 表达 要求 评分 情况下 也会 example 表达式 贝叶斯
原文地址:https://www.cnblogs.com/williamjie/p/9497067.html