标签:lis ref put fun 黄色 列队 概率 实测 else
这两天翻了一下机器学习实战这本书,算法是不错,只是代码不够友好,作者是个搞算法的,这点从代码上就能看出来。可是有些地方使用numpy搞数组,搞矩阵,总是感觉怪怪的,一个是需要使用三方包numpy,虽然这个包基本可以说必备了,可是对于一些新手,连pip都用不好,装的numpy也是各种问题,所以说能不用还是尽量不用,第二个就是毕竟是数据,代码样例里面写的只有几个case,可是实际应用起来,一定是要上数据库的,如果是array是不适合从数据库中读写数据的。因此综合以上两点,我就把这段代码改成list形式了,当然,也可能有人会说我对numpy很熟悉啊,而且作为专业的数学包,矩阵的运算方面也很方便,我不否定,那我这段代码恐怕对你不适合,你可以参考书上的代码,直接照打并理解就好了。
knn,不多说了,网上书上讲这个的一大堆,简单说就是利用新样本new_case的各维度的数值与已有old_case各维度数值的欧式距离计算
欧式距离这里也不说了,有兴趣可以去翻我那篇python_距离测量,里面写的很详细,并用符号展示说明,你也可以改成棋盘距离或街区距离试试,速度可能会比欧式距离快,但还是安利欧式距离。
有一点没搞明白的就是,对坐标进行精度化计算这块,实测后确定使用直接计算无论是错误率还是精度,处理前都要比处理后更准确,可能原代码使用小数点的概率更高些吧,也许这个计算对于小数计算精度更有帮助
闲话一些,不多也不少,下面上代码,代码中配有伪代码,方便阅读,如果还看不太明白可以留言,我把详细注释加上
以下是代码中使用颜色,选用html的16进制RGB颜色,在应用时将其转换为10进制数字计算,old_case选取红色圈,new_case选取橙色圈
紫色(茄子颜色)

绿色(黄瓜颜色)

黄色(香蕉颜色)

淡绿(西葫芦颜色)

代码见下
#!/usr/bin//python # coding: utf-8 ‘‘‘ 1、获取key和coord_values,样例使用的是list,但是如果真正用在训练上的话list就不适合了,建议改为使用数据库进行读取 2、对坐标进行精度化计算,这个其实我没理解是为什么,可能为了防止错误匹配吧,书上是这样写的 3、指定两个参数,参数一是新加入case的坐标,参数二是需要匹配距离最近的周边点的个数n,这里赢指定单数 4、距离计算,使用欧式距离 新加入case的坐标与每一个已有坐标计算,这里还有优化空间,以后更新 计算好的距离与key做成新的key-value 依据距离排序 取前n个case 5、取得key 对前n个case的key进行统计 取统计量结果最多的key即是新加入case所对应的分组 6、将新加入的values与分组写成key-value加入已有的key-value列队 输入新的case坐标,返回第一步......递归 ‘‘‘ import operator def create_case_list(): # 1代表黄瓜,2代表香蕉,3代表茄子,4代表西葫芦 case_list = [[25,3,73732],[27.5,8,127492],[13,6,127492],[16,13,50331049],[17,4,18874516],[22,8,13762774],[14,1,30473482],[18,3,38338108]] case_type = [1,1,2,2,3,3,4,4] return case_list,case_type def knn_fun(user_coord,case_coord_list,case_type,take_num): case_len = len(case_coord_list) coord_len = len(user_coord) eu_distance = [] for coord in case_coord_list: coord_range = [(user_coord[i] - coord[i]) ** 2 for i in range(coord_len)] coord_range = sum(coord_range) ** 0.5 eu_distance.append(coord_range) merage_distance_and_type = zip(eu_distance,case_type) merage_distance_and_type.sort() type_list = [merage_distance_and_type[i][1] for i in range(take_num)] class_count = {} for type_case in type_list: type_temp = {type_case:1} if class_count.get(type_case) == None: class_count.update(type_temp) else: class_count[type_case] += 1 sorted_class_count = sorted(class_count.iteritems(), key = operator.itemgetter(1), reverse = True) return sorted_class_count[0][0] def auto_norm(case_list): case_len = len(case_list[0]) min_vals = [0] * case_len max_vals = [0] * case_len ranges = [0] * case_len for i in range(case_len): min_list = [case[i] for case in case_list] min_vals[i] = min(min_list) max_vals[i] = max([case[i] for case in case_list]) ranges[i] = max_vals[i] - min_vals[i] norm_data_list = [] for case in case_list: norm_data_list.append([(case[i] - min_vals[i])/ranges[i] for i in range(case_len)]) return norm_data_list,ranges,min_vals def main(): result_list = [‘黄瓜‘,‘香蕉‘,‘茄子‘,‘西葫芦‘] dimension1 = float(input(‘长度是: ‘)) dimension2 = float(input(‘弯曲度是: ‘)) dimension3 = float(input(‘颜色是: ‘)) case_list,type_list = create_case_list() #norm_data_list,ranges,min_vals = auto_norm(case_list) in_coord = [dimension1,dimension2,dimension3] #in_coord_len = len(in_coord) #in_coord = [in_coord[i]/ranges[i] for i in range(in_coord_len)] #class_sel_result = knn_fun(in_coord,norm_data_list,type_list,3) class_sel_result = knn_fun(in_coord,case_list,type_list,3) class_sel_result = class_sel_result - 1 return result_list[class_sel_result] if __name__ == ‘__main__‘: a = main() print ‘这货是: %s‘ %a
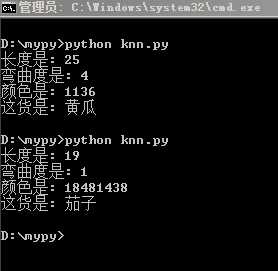
测试结果,效果还不赖
标签:lis ref put fun 黄色 列队 概率 实测 else
原文地址:https://www.cnblogs.com/xiu123/p/9503298.html