标签:进一步 split 必须 iterator state 静态工厂方法 自动 sort normal
| 表格内容来自https://docs.oracle.com/javase/8/docs/api/ Package java.util.stream 一节部分原文内容的翻译 |
int sum = widgets.stream() .filter(b -> b.getColor() == RED) .mapToInt(b -> b.getWeight()) .sum();
流操作被划分为中间和终端操作,并组合成流管道。
一条Stream管道由一个源(如一个集合、一个数组、一个生成器函数或一个i/o通道)组成;
然后是零个或更多的中间操作,例如Stream.filter或者 Stream.map
还有一个终端操作,Stream.forEach or Stream.reduce
中间操作返回一条新流,他们总是惰性的;
执行诸如filter()之类的中间操作实际上并不会立即执行任何过滤操作,而是创建了一个新流,当遍历时,它包含与给定谓词相匹配的初始流的元素。直到管道的终端操作被执行,管道源的遍历才会开始
终端操作,例如Stream.forEach 和 IntStream.sum,可以遍历流以产生结果或副作用。
在执行终端操作之后,流管道被认为是被消耗掉的,并且不能再被使用;
如果您需要再次遍历相同的数据源,您必须返回到数据源以获得一条新的stream。
在几乎所有情况下,终端操作都很迫切,在返回之前完成了数据源的遍历和管道的处理。只有终端操作iterator() 和 spliterator() 不是;这些都是作为一个“逃生舱口”提供的,以便在现有操作不足以完成任务的情况下启用任意客户控制的管道遍历(个人理解就是如果流不足以提供处理可以让你自行遍历处理)
延迟处理流可以显著提高效率;
在像上面的filer-map-sum例子这样的管道中,过滤、映射和求和可以被融合到数据的单个传递中,并且具有最小的中间状态。
惰性还允许在没有必要的情况下避免检查所有数据;对于诸如“查找第一个超过1000个字符的字符串”这样的操作,只需要检查足够的字符串,就可以找到具有所需特征的字符串,而不需要检查源的所有字符串。(当输入流是无限的而不仅仅是大的时候,这种行为就变得更加重要了。)
中间操作被进一步划分为无状态和有状态操作。
无状态操作,如filter和map,在处理新元素时不保留以前处理的元素的状态——每个元素都可以独立于其他元素的操作处理。有状态的操作,例如distinct和sorted,可以在处理新元素时从先前看到处理的元素中合并状态。
有状态操作可能需要在产生结果之前处理整个输入。
例如,一个人不能从排序流中产生任何结果,直到一个人看到了流的所有元素。
因此,在并行计算下,一些包含有状态中间操作的管道可能需要对数据进行多次传递,或者可能需要缓冲重要数据。包含完全无状态的中间操作的管道可以在单次传递过程中进行处理,无论是顺序的还是并行的,只有最少的数据缓冲
此外,一些操作被认为是短路操作。一个中间操作,如果在提供无限流输入时,它可能会产生一个有限的流,那么他就是短路的。如果在无限流作为输入时,它可能在有限的时间内终止,这个终端操作是短路的。
在管道中进行短路操作是处理无限流在有限时间内正常终止的必要条件,但不是充分条件
|
| 这些流的方法是如何实现的? 类StreamSupport提供了许多用于创建流的低级方法,所有这些方法都使用某种形式的Spliterator. 一个Spliterator.是迭代器Iterator的并行版本 它描述了一个(可能是无限的)元素集合,支持顺序前进、批量遍历,并将一部分输入分割成另一个可并行处理的Spliterator 在最低层,所有的流都由一个spliterator 构造(所以说流就是迭代器的一种高级形式) 在实现Spliterator时,有许多实现选择,几乎所有的实现都是在简单的实现和使用Spliterator流的运行时性能之间进行权衡。创建Spliterator的最简单、但最不高性能的方法是,使用Spliterators.spliteratorUnknownSize(java.util.Iterator, int).虽然这样的Spliterator可以工作,但它很可能提供糟糕的并行性能,因为我们已经丢失了尺寸信息(底层数据集有多大),并且被限制为一个简单的分割算法。 一个高质量的Spliterator将提供平衡的和知道大小的分割,精确的尺寸信息,以及一些可用于实现优化执行的spliterator 或数据的 characteristics (见Spliterator int characteristics() ) 可变数据源的Spliterators有一个额外的挑战; 绑定到数据的时间,因为数据可能在创建spliterator的时间和执行流管道的时间之间发生变化。理想情况下,一个流的spliterator 应该报告一个characteristic of IMMUTABLE or CONCURRENT; 如果不是,应该是后期绑定。如果一个源不能直接提供一个推荐的spliterator,它可能会间接地通过Supplier提供一个spliterator,通过接收Supplier作为参数的stream方法构建一个流 public static <T> Stream<T> stream(Supplier<? extends Spliterator<T>> supplier, int characteristics, boolean parallel)
只有在流管道的终端操作开始后,才从supplier处获
|

| 支持顺序和并行聚合操作的一组元素序列 除了Stream 还有专门为原始类型特殊化的IntStream、LongStream和double Stream 所有这些都被称为“流” 集合和流,虽然表面上有一些相似性,但有不同的设计目的
集合主要关注的是对其元素的有效管理和访问
相比之下,流并没有提供直接访问或操纵其元素的方法,而是关注于声明性地描述它们的源和计算操作,这些操作将在该源上进行聚合。
但是,如果所提供的流操作没有提供所需的功能,那么 BaseStream.iterator() 和 BaseStream.spliterator() 操作可以用来执行受控的遍历
示例:
widgets 是 Collection<Widget> int sum = widgets.stream() .filter(w -> w.getColor() == RED) .mapToInt(w -> w.getWeight()) .sum();
像上面的“widgets”示例一样,流管道可以看作是在流的数据源上进行的查询。
除非源代码是为并发修改而显式设计的(例如ConcurrentHashMap),否则在查询时 修改流的源 可能导致不可预测或错误的行为。
大多数流操作都接受描述用户指定行为的参数,比如在上面的例子中传递给mapToInt的lambda表达式w-w.getweight()。
为了保持正确的行为,这些行为参数:
必须是非干扰(也就是它们不修改流源);
在大多数情况下,必须是无状态的(它们的结果不应该依赖于任何在流水线执行过程中可能发生变化的状态)
这些参数通常是函数接口的实例,例如Function,一般是lambda表达式或方法引用。除非另有说明,这些参数必须是非空的。
一个流应该只运行一次(调用中间操作或结束操作)。这就排除了比如“forked”流,在这些流中,相同的源提供两个或更多的管道,或者同一流的多个遍历。
一个流实现可能会抛出IllegalStateException 异常,如果它检测到流正在被重用。
然而,由于某些流操作可能返回它们的接收者而不是一个新的stream对象,所以并不能在所有情况下都检测到重用。
Streams有一个BaseStream.close()方法并实现AutoCloseable,但是几乎所有的stream实例在使用后实际上并不需要关闭。
通常,只有源是IO通道的流(比Files.lines(Path,Charset))将需要关闭。
大多数流都是由集合、数组或生成函数支持的,这些功能不需要特殊的资源管理。(如果流确实需要关闭,它可以在try-with-resources语句中声明为资源。)
流管道可以按顺序或并行执行 ,这种执行模式是流的属性。
流的类型是创建初始时选择通过顺序或并行操作执行来决定的。(例如,Collections.stream()创建了一个顺序流,而Collection.parallelStream()创建了一个并行的流。)
这种执行模式的选择可以由BaseStream.sequential() 或BaseStream.parallel()方法修改,并且可以使用BaseStream.isParallel() 方法查询。
|
|
集合是对一组特定类型的元素值序列提供的接口 是数据结构,提供了元素的存取
流也是对一组特定类型元素值序列提供的接口,在于计算,提供了对元素序列的操作计算方式 比如 filter map等
|
| 流只能运行一次 |
| 流由源 0个或者多个中间操作以及结束操作组成 |
| 流操作的方法基本上是函数式接口的实例 |
| 流的中间操作是惰性的并不会立即执行 这更有利于内部迭代的优化 |
| 流借助于它内部迭代特性提供了声明式的编程方式 更急简洁 |
| 中间操作本身会返回一个流,可以将多个操作复合叠加,形成一个更大的流水线 |
| 流分为顺序和并行两种方式 |
|
可以把流当做一个高级的迭代器Iterator ,内部有它自身运行逻辑的迭代器
你只需要告诉他你想要做什么,他自己就会自动的去迭代筛选组织你想要的数据
|
| Stream.of( ) Stream类静态方法 转换XXX为Stream |

| Collection stream 集合转换为Stream 特 别 注 意:这是一个default方法,也就意味着如果没有特别处理,所有Collection子类都具有 |

| Arrays.stream(); 数组转换为Stream |

| Stream.iterate Stream类静态方法 迭代器的形式,创建一个数据流 |


| Stream.generate |



|
BaseStream规定了流的基本接口
Stream中定义了map、filter、flatmap等用户关注的常用操作;
Int~ Long~ Double~是针对于基本类型的特化 方法与Stream中大致对应,当然也有一些差别
BaseStream Stream IntStream LongStream DoubleStream 组建了Java的流体系根基
他们都只是接口
|

| PipelineHelper主要用于Stream执行过程中相关结构的构建 ReferencePipeline 和 AbstractPipeline 完成了Stream的主要实现 AbstractPipeline类实现了所有的 Stream的中间操作和最终操作 [Int | Long | Double] pipeline 同理类似ReferencePipeline只不过是针对基本类型  |

| Head、StatelessOp、StatefulOp为ReferencePipeline中的内部类 [Int | Long | Double]Pipeline 内部也都是定义了这三个内部类 |
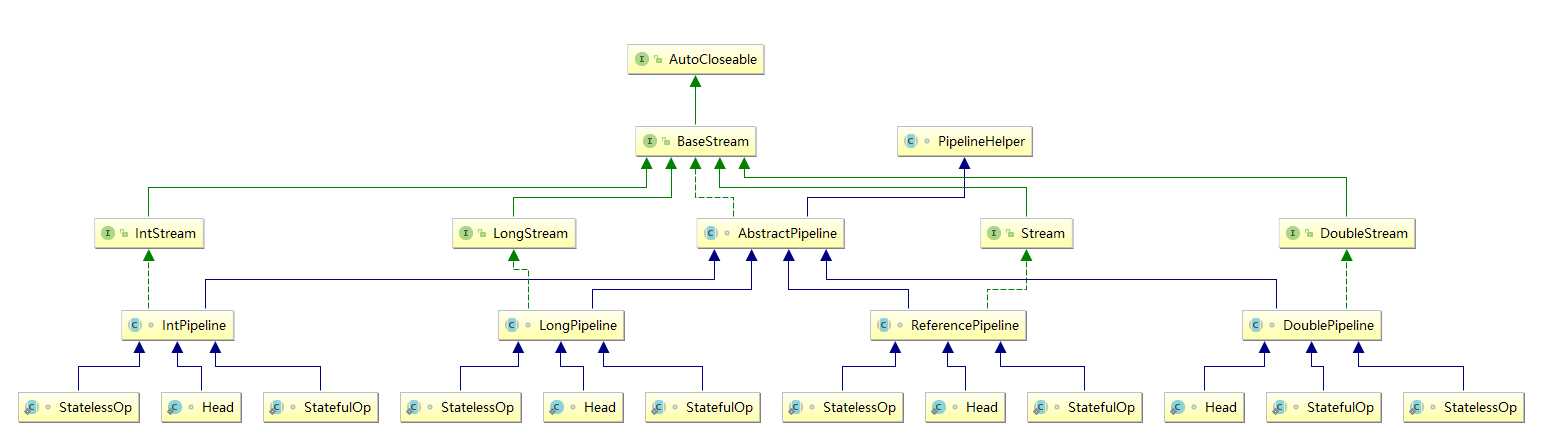


|
你会发现流的生成转换创建都是使用StreamSupport
StreamSupport 是用于创建和操纵Stream的低级工具方法
除了构造方法,每个方法都是返回他们对应的Head
ReferencePipeline.Head / DoublePipeline.Head / IntPipeline.Head / LongPipeline.Head
|

| 数据源 |
| 操作( filter map.....) |
| 回调方法(Lambda匿名函数 方法引用) |
Source stage of a ReferencePipeline.Base class for a stateful intermediate stage of a Stream.Base class for a stateless intermediate stage of a Stream.
| 说白了也就是上面说到过的Head StatefulOp StatelessOp 他们本身也是AbstractPipeline类型的 |

|
private final AbstractPipeline sourceStage; //反向链接管道链的head,也就是说每个管道节点都有一个头
private final AbstractPipeline previousStage;//指向上一个
private AbstractPipeline nextStage;//指向下一个
赤裸裸的双向链表
|



|
Stream中将操作抽象化为stage 每个stage 也就是一个AbstractPipeline
每个stage 相当于一个双向链表的节点 ,每个节点都保存Head然后保存着上一个和下一个
这个双向链表就构成了整个流水线
(上面的图看起来next一直是null 是在每个处理后的this里面的previousStage里面 上一个的next是当前)
|




|
Stream体系是一组接口家族,AbstractPipeline 是接口的实现,PipelineHelper 是管道的辅助类,StreamSupport是流的低级工具类
使用stage来抽象流水线上的每个操作
其实每个stage就是一个stream 也就是AbstractPipeline几个子类的 内部子类 Head StatelessOp statefulOp
StreamSupport用于创建生成Stream 对应的是Head类
其他的中间操作分为有状态和无状态的,中间操作通过方法比如 filter map 等返回的是StatelessOp 或者 statefulOp
多个stage组合称为双向链表的形式 从而成了整个流水线
有了流水线,相邻两个操作阶段之间如何协调运算?
于是又有了sink的概念,又来协调相邻的stage之间计算运行
他的模式是begin accept end 还有短路标记
他的accept就是封装了回调方法
所以说每个操作stage, StatelessOp 或者 statefulOp中又封装了Sink
通过AbstractPipeline提供的opWrapSink方法可以获取这个sink
调用这个sink的accept方法就可以调用当前操作的方法
那么如何串联起来呢?关键点在于opWrapSink方法 ,他接收一个Sink作为参数
在调用accept方法中 可以调用这个入参sink的accept方法
这样子从当前就能调用下一个,也就是说有了推动的动作
那么只需要找到开始,每个处理了之后都推动下一个,就顺序完成了所欲的操作了
注意上面说的操作都是中间操作,中间操作才会产生操作阶段 终端操作不会增加stage的个数了
|
| 中间操作 | filter() flatMap() limit() map() concat() distinct() peek() skip() sorted() parallel() sequential() unordered() flatMapTo[Double | Int | Long] mapTo[ Double | Int | Long ] |
| 结束操作 | allMatch() anyMatch() collect() count() findAny() findFirst() forEach() forEachOrdered() max() min() noneMatch() reduce() toArray() |

| 流到流之间的转换 filter(过滤), map(映射转换), mapTo[Int|Long|Double] (到基本类型流的转换), flatMap(流展开合并),flatMapTo[Int|Long|Double], sorted(排序),distinct(不重复值),peek(执行某种操作,流不变,可用于调试), limit(限制到指定元素数量), skip(跳过若干元素) |
| 流到终值的转换 toArray(转为数组),reduce(推导结果),collect(聚合结果), min(最小值), max(最大值), count (元素个数), anyMatch (任一匹配), allMatch(所有都匹配), noneMatch(一个都不匹配) findFirst(选择首元素),findAny(任选一元素) |
| 直接遍历 forEach (不保证顺序遍历,比如并行流), forEachOrdered(顺序遍历) |
| 构造流 empty (构造空流),of (单个元素的流及多元素顺序流) iterate (无限长度的有序顺序流),generate (将数据提供器转换成无限非有序的顺序流), concat (流的连接), Builder (用于构造流的Builder对象) |
| filter 条件筛选 boolean test(T t); |


| map 数据转换 R apply(T t); 新的值替换Stream中的值 mapTo[Int | Long | Double] 类似 |


| flatMap R apply(T t); 同map但是是多个流转换为一个流 返回值限定为Stream 其他flatMapTo[Int | Long | Double] 类似 |


| 生成流 iterate() public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f)
|

Stream.iterate(0, i -> i + 2)
| 生成流 generate() public static<T> Stream<T> generate(Supplier<T> s) |

|
一个归约操作(也称为折叠)接受一系列的输入元素,并通过重复应用组合操作将它们组合成一个简单的结果
例如查找一组数字的总和或最大值,或者将元素累积到一个列表中。
流的类中有多种形式的通用归约操作,称为reduce()和collect(),以及多个专门化的简化形式,如sum()、max()或count()。
当然,这样的操作可以很容易地实现为简单的顺序循环,如下所示:
int sum = 0; for (int x : numbers) { sum += x; }
然而,我们有充分的理由倾向于减少操作,而不是像上面这样的累加运算。
它不仅是一个“更抽象的”——它在流上作为一个整体而不是单独的元素来运行——而且一个适当构造的reduce操作本质上是可并行的,只要用于处理元素的函数(s)是结合的和无状态的。举个例子,给定一个数字流,我们想要找到和,我们可以写:
int sum = numbers.stream().reduce(0, (x,y) -> x+y);
或者
int sum = numbers.stream().reduce(0, Integer::sum);
这些归约操作几乎不需要修改就可以并行运行
int sum = numbers.parallelStream().reduce(0, Integer::sum);
如果一个操作符或函数 op 满足 (a op b) op c == a op (b op c) ,那么他是结合的
结合性对于并行结算非常重要
比如
a op b op c op d == (a op b) op (c op d) 就可以并行计算 (a op b) (c op d) 然后再处理他们
|

|
Optional<T> reduce(BinaryOperator<T> accumulator)
参数accumulator: 累计计算器——结合两个值的结合性、非干扰、无状态函数
因为没有初始值 所以返回值为 Optional<T>
计算1+2+3+4+5
 相当于
boolean foundAny = false; T result = null; for (T element : this stream) { if (!foundAny) { foundAny = true; result = element; } else result = accumulator.apply(result, element); } return foundAny ? Optional.of(result) : Optional.empty();
如果不进入循环,那么foundAny就是false 直接返回
否则第一次循环给result赋值,此后foundAny 为true
result作为一个操作数调用accumulator.apply()
BinaryOperator 意味着两个操作数一个结果数 类型一样 这可不仅仅用于累加
  还可以用来合并字符串 多种形式
|
T reduce(T identity, BinaryOperator<T> accumulator); identity 可以理解为初始值, accumulator 同上  你会发现对于上面的例子,可以使用Integer::sum 替代其中的lambda 相当于 T result = identity; for (T element : this stream) result = accumulator.apply(result, element) return result;
|
<U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner);
相当于:
U result = identity; for (T element : this stream) result = accumulator.apply(result, element) return result;
看得出来和T reduce(T identity, BinaryOperator<T> accumulator); 几乎是一样的
只不过Stream是T 返回是U 可能一样,可能不一样了
如果类型相同的话就是完全一样的了
第三个参数用于在并行计算下 合并各个线程的计算结果
所以要求
combiner.apply(u, accumulator.apply(identity, t)) == accumulator.apply(u, t)
  结果不同 是因为 ((((5+1)+2)+3)+4)+5 和 (5+1)+ (5+2)+ (5+3)+ (5+4)+ (5+5) 运算结果不相同
 此处 挨个比较找到最大,和 使用8和每个数字比较然后在统一比较 的结果是相同的
|
[三]java8 函数式编程Stream 概念深入理解 Stream 运行原理 Stream设计思路
标签:进一步 split 必须 iterator state 静态工厂方法 自动 sort normal
原文地址:https://www.cnblogs.com/noteless/p/9505098.html