标签:查询 很多 log 关系 .com more get 范围 exactly
天天和数据库打交道,powderdesigner设计表,数据库简单操作——增删改,上面是操作数据库大头,项目也用到redis,读写分离的;数据慢慢变多,开始时候表没有建什么索引,后面会慢慢多起来。
索引:我理解这个和书的目录相同,通过特定方式快速查找要的内容,
原因:索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数
数据库的索引使用的技术有很多:mysql B+树,(R-Tree)索引,基于hash的索引,聚簇索引等
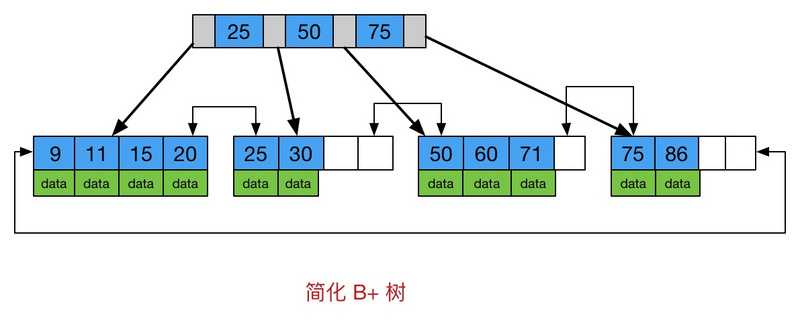
B+树:
-
B+树更适合外部存储,由于内节点无 data 域,一个结点可以存储更多的内结点,每个节点能索引的范围更大更精确,也意味着 B+树单次磁盘IO的信息量大于B-树,I/O效率更高。
-
Mysql是一种关系型数据库,区间访问是常见的一种情况,B+树叶节点增加的链指针,加强了区间访问性,可使用在范围区间查询等,而B-树每个节点 key 和 data 在一起,则无法区间查找
(1)匹配全值(Match the full value):对索引中的所有列都指定具体的值。例如,上图中索引可以帮助你查找出生于1960-01-01的Cuba Allen。
(2)匹配最左前缀(Match a leftmost prefix):你可以利用索引查找last name为Allen的人,仅仅使用索引中的第1列。
(3)匹配列前缀(Match a column prefix):例如,你可以利用索引查找last name以J开始的人,这仅仅使用索引中的第1列。
(4)匹配值的范围查询(Match a range of values):可以利用索引查找last name在Allen和Barrymore之间的人,仅仅使用索引中第1列。
(5)匹配部分精确而其它部分进行范围匹配(Match one part exactly and match a range on another part):可以利用索引查找last name为Allen,而first name以字母K开始的人。
(6)仅对索引进行查询(Index-only queries):如果查询的列都位于索引中,则不需要读取元组的值。
hash的索引
(1)不能使用hash索引排序。
(2)Hash索引不支持键的部分匹配,因为是通过整个索引值来计算hash值的。
(3)Hash索引只支持等值比较,例如使用=,IN( )和<=>。对于WHERE price>100并不能加速查询
空间(R-Tree)索引
MyISAM支持空间索引,主要用于地理空间数据类型,例如GEOMETRY。
聚簇索引(Clustered Indexes)
目前,只有solidDB和InnoDB支持。
InnoDB对主键建立聚簇索引。如果你不指定主键,InnoDB会用一个具有唯一且非空值的索引来代替。如果不存在这样的索引,InnoDB会定义一个隐藏的主键,然后对其建立聚簇索引。一般来说,DBMS都会以聚簇索引的形式来存储实际的数据,它是其它二级索引的基础
使用索引注意:
1、字段A,建立索引,可以模糊查询A%,使用到索引,一旦以%开头将不会走索引;
2、字段A字段B,多个字段组成的组合索引,查询第一个字段A时候,会走AB字段组合的索引,以B字段查询不会走AB字段的索引,模糊查询和单个索引类似;
3、字段A,字段B都有索引,当查询有 A or B时候走索引,or 前后有一个不是索引,将不会走索引,例如字段A有索引,字段B没有索引,不会走A的索引;
4、只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL;
5、索引列排序,mysql查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。
来个尾巴:
知识点很多,前一段时间有点像小猴子下山,对很多知识都感兴趣,接触还未深入了解,又被新的知识点吸引,杂而不精;
现在修改一个小周期,定下一个小主题,围绕小主题来;
心定下来咯,焦虑感降低,学习的乐趣也多起来!!!
以上参考了:
mysql索引
标签:查询 很多 log 关系 .com more get 范围 exactly
原文地址:https://www.cnblogs.com/xiebq/p/9508843.html