标签:信息 return 了解 分享 html 图片 turn color src
爬虫想必大家都很了解,通过脚本对目标文件进行抓取。
我想获取每天菜市场菜价。
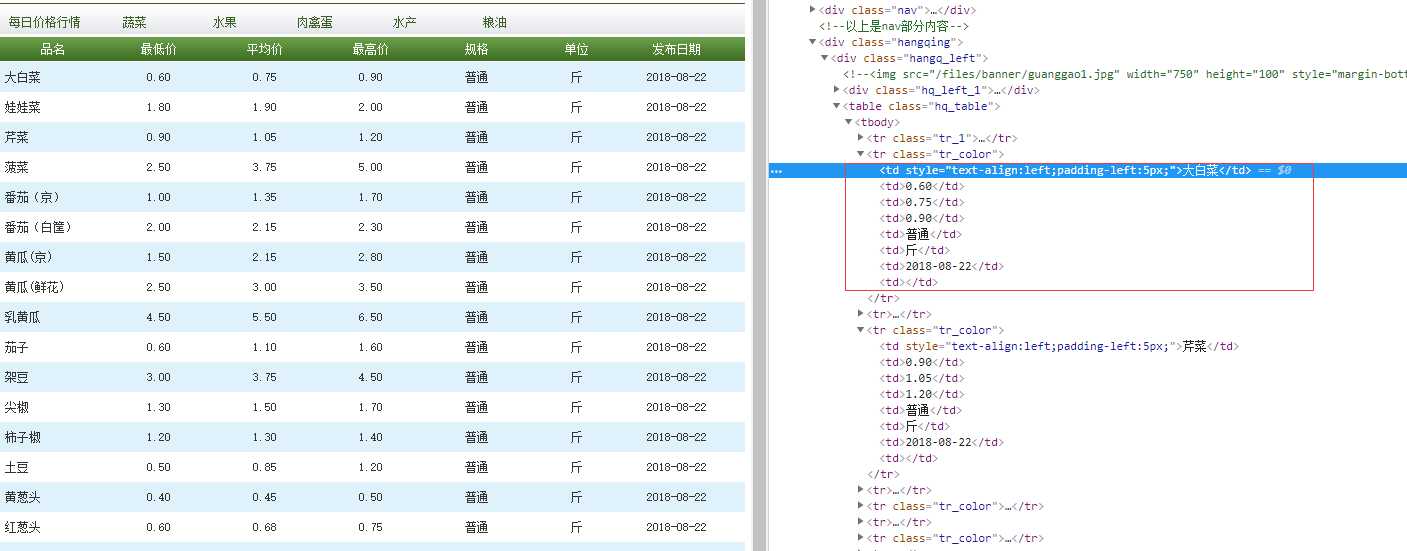
查看控制台,如果有相关信息得接口自然方便不过了,直接请求接口获取数据就可以了。
对于页面信息,需要过滤筛选。
图中信息很规律易于筛选。
首先获取整个页面,可以使用CURL方式请求页面地址,CURL方式也便于需要验证信息的页面传递参数。
过滤页面数据可以使用正则表达式匹配替换。
<?php header( "Content-type:text/html;Charset=utf-8" ); $ch = curl_init(); $url ="http://www.xinfadi.com.cn/marketanalysis/0/list/1.shtml"; curl_setopt ( $ch , CURLOPT_USERAGENT ,"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36" ); curl_setopt($ch,CURLOPT_URL,$url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $content=curl_exec($ch); preg_match_all("/<td style=\"text-align:left;padding-left:5px;\">(.*?)<\/td><td>(.*?)<\/td><td>(.*?)<\/td><td>(.*?)<\/td><td>(.*?)<\/td><td>(.*?)<\/td><td>(.*?)<\/td>/",$content,$matchs,PREG_SET_ORDER); print_r($matchs);
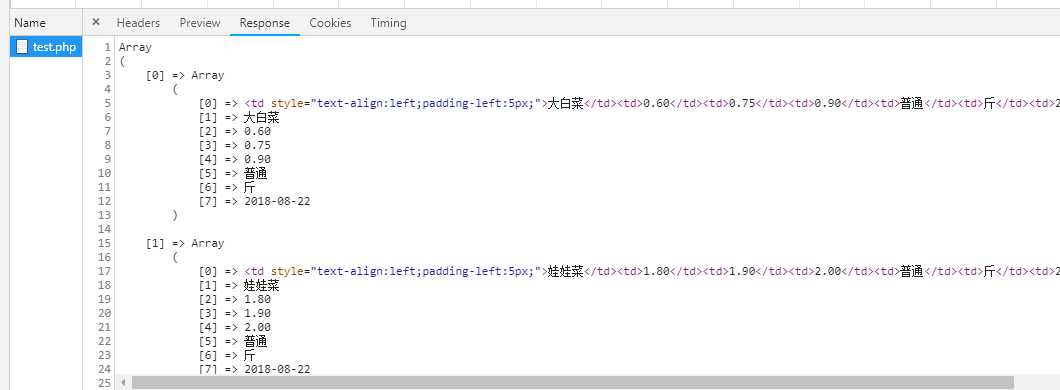
这样就完成了,主要就是使用正则表达式对页面进行过滤筛选,爬取图片也是一样。
标签:信息 return 了解 分享 html 图片 turn color src
原文地址:https://www.cnblogs.com/liuliwei/p/9519686.html