标签:类别 ima got turn frame tst 过程 values http
位置参数的传递
前面我们已经分析了无参函数的调用过程,我们来看看Python是如何来实现带参函数的调用的。其实,基本的调用流程与无参函数一样,而不同的是,在调用带参函数时,Python虚拟机必须传递参数。我们先来看一段代码:
# cat demo2.py
def f(name, age):
age += 5
print("[", name, age, "]")
age = 5
f("Robert", age)
我们用dis模块来编译一下对应的字节码:
# python2.5
……
>>> source = open("demo2.py").read()
>>> co = compile(source, "demo2.py", "exec")
>>> import dis
>>> dis.dis(co)
1 0 LOAD_CONST 0 (<code object f at 0x7ff044b1c648, file "demo2.py", line 1>)
3 MAKE_FUNCTION 0
6 STORE_NAME 0 (f)
6 9 LOAD_CONST 1 (5)
12 STORE_NAME 1 (age)
7 15 LOAD_NAME 0 (f)
18 LOAD_CONST 2 (‘Robert‘)
21 LOAD_NAME 1 (age)
24 CALL_FUNCTION 2
27 POP_TOP
28 LOAD_CONST 3 (None)
31 RETURN_VALUE
再用dis模块编译下函数f对应的字节码:
>>> from demo2 import f
>>> dis.dis(f)
2 0 LOAD_FAST 1 (age)
3 LOAD_CONST 1 (5)
6 INPLACE_ADD
7 STORE_FAST 1 (age)
3 10 LOAD_CONST 2 (‘[‘)
13 LOAD_FAST 0 (name)
16 LOAD_FAST 1 (age)
19 LOAD_CONST 3 (‘]‘)
22 BUILD_TUPLE 4
25 PRINT_ITEM
26 PRINT_NEWLINE
27 LOAD_CONST 0 (None)
30 RETURN_VALUE
在编译后的demo2.py中,CALL_FUNCTION指令之前,有三条LOAD指令,这三条LOAD指令执行完成后的运行时栈如图1-1所示:
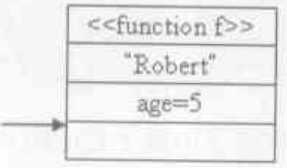
图1-1 CALL_FUNCTION指令执行前的运行时栈
可以看到,函数需要的参数已经被压到运行时栈中了。接下来执行CALL_FUNCTION指令,其指令参数为2
ceval.c
static PyObject * call_function(PyObject ***pp_stack, int oparg)
{
int na = oparg & 0xff;
int nk = (oparg >> 8) & 0xff;
int n = na + 2 * nk;
PyObject **pfunc = (*pp_stack) - n - 1;
PyObject *func = *pfunc;
……
}
前面我们提到,CALL_FUNCTION的指令参数oparg中,低字节包含了位置参数的个数,所谓位置参数,就是如f中所见的一般函数。而oparg中高字节包含另一种参数的个数。因此na=2,nk=2,所以n=2。从栈顶指针pp_stack开始,回退2后,PyObject *func正确地指向了运行时栈中存储的那个代表着f的PyFunctionObject对象。然后,程序进入fast_function
ceval.c
static PyObject *
fast_function(PyObject *func, PyObject ***pp_stack, int n, int na, int nk)
{
PyCodeObject *co = (PyCodeObject *)PyFunction_GET_CODE(func);
PyObject *globals = PyFunction_GET_GLOBALS(func);
PyObject *argdefs = PyFunction_GET_DEFAULTS(func);
PyObject **d = NULL;
int nd = 0;
……
if (argdefs == NULL && co->co_argcount == n && nk == 0 &&
co->co_flags == (CO_OPTIMIZED | CO_NEWLOCALS | CO_NOFREE))
{
PyFrameObject *f;
PyObject *retval = NULL;
PyThreadState *tstate = PyThreadState_GET();
PyObject **fastlocals, **stack;
int i;
PCALL(PCALL_FASTER_FUNCTION);
assert(globals != NULL);
//[1]:创建与函数对应的PyFrameObject对象
f = PyFrame_New(tstate, co, globals, NULL);
//[2]:拷贝函数参数:从运行时栈到PyFrameObject.f_localsplus
fastlocals = f->f_localsplus;
stack = (*pp_stack) - n;
for (i = 0; i < n; i++)
{
Py_INCREF(*stack);
fastlocals[i] = *stack++;
}
……
}
if (argdefs != NULL)
{
d = &PyTuple_GET_ITEM(argdefs, 0);
nd = ((PyTupleObject *)argdefs)->ob_size;
}
return PyEval_EvalCodeEx(co, globals,
(PyObject *)NULL, (*pp_stack) - n, na,
(*pp_stack) - 2 * nk, nk, d, nd,
PyFunction_GET_CLOSURE(func));
}
在上述代码的[1]处创建了函数f对应的PyFrameObject对象,在这个过程中,函数f对应的PyFunctionObject对象中保存的PyCodeObject对象被传递给新创建的PyFrameObject对象。随后,在代码[2]处,Python虚拟机将参数逐个拷贝到新创建的PyFrameObject对象的f_localsplus中。f_localsplus所指向的内存块包含着Python虚拟机所使用的那个运行时栈,那么参数所占用的内存空间额运行时栈所占用的内存空间关系又是怎样的呢?答案就在PyFrame_New中
frameobject.c
PyFrameObject *
PyFrame_New(PyThreadState *tstate, PyCodeObject *code, PyObject *globals,
PyObject *locals)
{
PyFrameObject *back = tstate->frame;
PyFrameObject *f;
Py_ssize_t i;
……
if (code->co_zombieframe != NULL) {
……
}
else {
Py_ssize_t extras, ncells, nfrees;
ncells = PyTuple_GET_SIZE(code->co_cellvars);
nfrees = PyTuple_GET_SIZE(code->co_freevars);
extras = code->co_stacksize + code->co_nlocals + ncells +
nfrees;
if (free_list == NULL) {
//[1]:为f_localsplus申请extras的内存空间
f = PyObject_GC_NewVar(PyFrameObject, &PyFrame_Type,
extras);
if (f == NULL) {
Py_DECREF(builtins);
return NULL;
}
}
……
f->f_code = code;
//[2]:获得f_localsplus中除去运行时栈外,剩余的内存数
extras = code->co_nlocals + ncells + nfrees;
f->f_valuestack = f->f_localsplus + extras;
for (i=0; i<extras; i++)
f->f_localsplus[i] = NULL;
……
}
f->f_stacktop = f->f_valuestack;
……
return f;
}
在函数对应的PyCodeObject对象的co_nlocals域中,包含着函数的参数的个数,因为函数参数也是局部符号的一种。在上述代码[2]处,从f_localsplus开始,计算出的extras的那段内存中,一定有供函数参数使用的内存。换一种说法,函数参数存放在运行时栈之前的那片内存中
从PyFrame_New创建PyFrameObject对象的过程中可以看到,在f_localsplus中,用于存储函数参数的空间和运行时栈的空间逻辑上时分离的,并不是共享同一片内存,尽管这两块连续内存所指向的对象相同,但它们界限分明,井水不犯河水
处理完参数后,还没有进入PyEval_EvalFrameEx,所以这时运行时栈还是空的。但是,函数已就位于f_localsplus中。这时,新建的PyFrameObject对象的f_localsplus域如图1-1所示:
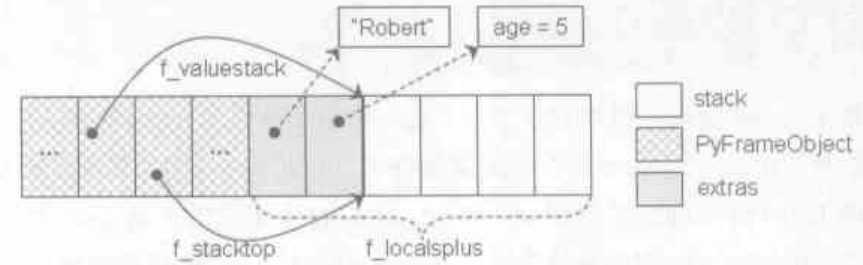
图1-1 进入PyEval_EvalFrameEx之前新建PyFrameObject对象的内存布局
位置参数的访问
当参数拷贝的动作完成后,就会进入新的PyEval_EvalFrameEx,开始真正的函数f的调用工作
def f(name, age):
age += 5
//字节码指令
0 LOAD_FAST 1 (age)
3 LOAD_CONST 1 (5)
6 INPLACE_ADD
7 STORE_FAST 1 (age)
print("[", name, age, "]")
……
age += 5所编译后的指令序列中,有两条是我们从来没有剖析过的,一条是LOAD_FAST,另一条是STORE_FAST,而正是这两条指令,完成函数参数的读写
ceval.c
PyObject * PyEval_EvalFrameEx(PyFrameObject *f, int throwflag)
{
register PyObject **fastlocals;
#define GETLOCAL(i) (fastlocals[i])
fastlocals = f->f_localsplus;
……
}
#define GETLOCAL(i) (fastlocals[i])
case LOAD_FAST:
x = GETLOCAL(oparg);
if (x != NULL)
{
Py_INCREF(x);
PUSH(x);
goto fast_next_opcode;
}
format_exc_check_arg(PyExc_UnboundLocalError,
UNBOUNDLOCAL_ERROR_MSG,
PyTuple_GetItem(co->co_varnames, oparg));
break;
#define SETLOCAL(i, value) do { PyObject *tmp = GETLOCAL(i); GETLOCAL(i) = value; Py_XDECREF(tmp); } while (0)
case STORE_FAST:
v = POP();
SETLOCAL(oparg, v);
goto fast_next_opcode;
PREDICTED(POP_TOP);
原来,LOAD_FAST和STORE_FAST这一对指令是以f_localsplus这片内存为操作目标的。指令"0 LOAD_FAST 1"的结果是将f_localsplus[1]中的对象压入到运行时栈中,而从图1-1中我们可以看到f_localsplus[1]存放的正是age。在完成加法操作后,又通过STORE_FAST将结果放入到f_localsplus[1]中,这样就实现了对变量age的更新,以后再print访问age参数时,得到的结果就是10了
关于Python中的函数的位置参数,我们对它在函数调用过程中是如何传递,在函数执行过程又是如何被访问和修改已经明白。在调用函数时,Python将函数参数从左至右压入到运行时栈中,在fast_function中,又将这些参数拷贝到新建的与函数对应的PyFrameObject对象的f_localsplus中。最终的效果是,Python虚拟机将函数调用时传入的参数,从左至右存放在新建的PyFrameObject对象的f_localsplus中
在访问函数参数时,Python虚拟机没有按照通常访问符号的做法,去访问名字空间,而是通过一个索引(偏移位置)来访问f_localsplus中存储的符号对应的对象。这种通过索引(偏移位置)进行访问的方法也正是“位置参数”名称的由来
标签:类别 ima got turn frame tst 过程 values http
原文地址:https://www.cnblogs.com/beiluowuzheng/p/9532797.html