标签:控制 优化 first 需要 替代 规则 gif sql优化 last
1)说明:
1. exists对外表做循环,每次循环对内表查询;in将内表和外表做hash连接
2. 使用exists oracle会先检查主查询; 使用in,首先执行子查询,并将结果存储在临时表中
2)使用:
表class和student表
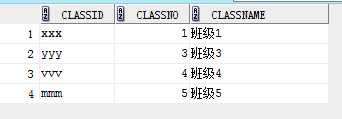
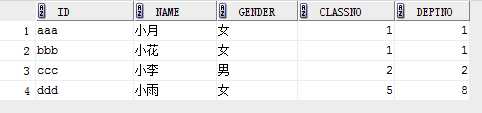
下面查询student中classno在class中的数据
1. 使用exists和not exists
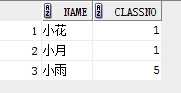
select name, classno from student where exists (select * from class where student.classno= class.classno);
结果:
select name, classno from student where not exists (select * from class where student.classno= class.classno);
结果:

select name, classno from student where classno in (select classno from class);
2. 使用in 和not in
select name, classno from student where classno not in (select classno from class);
结果:
3)比较
1. 如果两个表大小相当,in和exists差别不大
2. 如果两个表大小相差较大则子查询表大的用exists,子查询表小的用in
3.尽量不要使用not in
1)说明:
1. 使用场景:需要将两个select语句结果整体显示时,可以使用union和union all
2. union对两个结果集取并集不包含重复结果同时进行默认规则的排序;而union all对两个结果集去并集,包括重复行,不进行排序
3. union需要进行重复值扫描,效率低,如果没有要删除重复行,应该使用union all
4. insersect和minus分别交集和差集,都不包括重复行,并且进行默认规则的排序
2)使用注意事项
1.可以将多个结果集合并
2. 必须保证select集合的结果有相同个数的列,并且每个列的类型是一样的(列名不一定要相同,会默认将第一个结果的列名作为结果集的列名)
3)例子:
表student
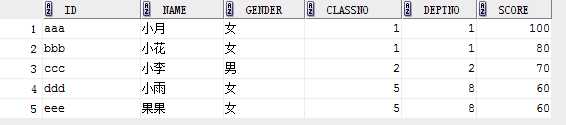
eg1:
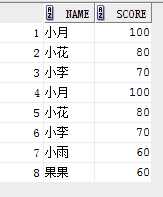
select name, score from student where score> 60
union all
select name, score from student where score <200;
结果:(有重复,没有排序)
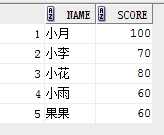
select name, score from student where score> 60
union
select name, score from student where score <200;
结果:(没有重复,并且排序了)
1)说明:
1. with table as 可以建立临时表,一次分析,多次使用
2. 对于复杂查询,使用with table as可以抽取公共查询部分,多次查询时可以提高效率
3. 增强了易读性
2)语法:
with tabName as (select ...)
3)例子:
表student
eg1:
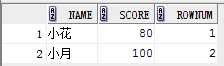
select rownum, name, score from (select rownum, name,score from student where score >70 order by score);
可以更换成:
with table_s as (select rownum, name,score from student where score >70 order by score)
select name, score from table_s;
结果:
4)多个with table as 一起使用时用逗号隔开,并且只能使用一个with如下例子
eg1:
with vt1 as (select * from student where score >=60),
vt2 as (select * from class),
vt3 as (select * from teacher)
select vt1.name, vt1.score, vt2.classname, vt3.teachername from vt1,vt2,vt3 where vt1.classno= vt2.classno and vt1.teacherid=vt3.teacherid;
eg2:

with vt as (select t.*
from travelrecord t where t.starttime>=to_date(‘2014-02-01‘,‘yyyy-mm-dd‘) and t.endtime<=to_date(‘2014-04-30‘,‘yyyy-mm-dd‘)+1 and to_char(starttime,‘hh24‘)>=‘08‘ and to_char(endtime,‘hh24‘)<=‘11‘ and t.vehiclenum=‘100088110000‘),
vt1 as (select sum(vt4.traveltime) as stoptime from ((select * from vt where vt.state=‘0‘)vt4)),
vt2 as (select sum(vt.traveltime)as "ONLINETIME1",sum(vt.distance)as "DISTANCE1"from vt)
select vt1.stoptime,vt2.distance1, vt2.onlinetime1 from vt2, vt1;
1)说明:
1. order by 决定oracle如何将查询结果排序
2. 不指定asc或者desc时默认asc
2)使用:
1. 单列升序(可以去掉asc)
select * from student order by score asc;
2. 多列升序
select * from student order by score, deptno;
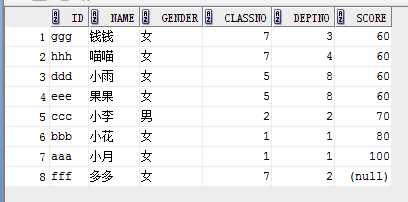
3. 多列降序
select * from student order by score desc, deptno desc;
4. 混合
select * from student order by score asc, deptno desc;
3)对NULL的处理
1. oracle在order by 时认为null是最大值,asc时排在最后,desc时排在最前
eg:
select * from student order by score asc;
结果: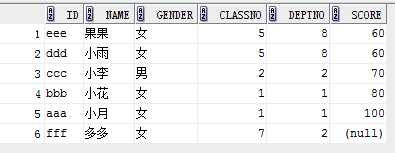
2. 使用nulls first (不管asc或者desc,null记录排在最前)或者nulls last 可以控制null的位置,eg:
select * from student order by score asc nulls first;
结果如下:
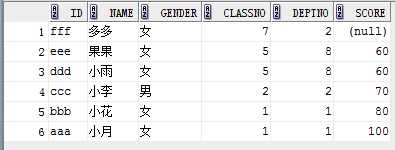
4)将某行数据置顶(decode)
eg1:
select * from student order by decode(score,100,1,2);
结果:
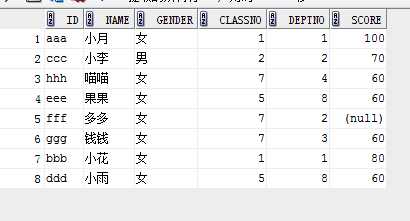
eg2: (某一行置顶,其他的升序)
select * from student order by decode(score,100,1,2), score;
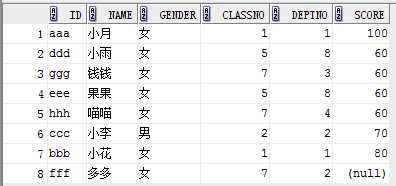
5)注意事项
1. 任何在order by 语句的非索引项都将降低查询速度
2. 避免在order by 子句中使用表达式
1)说明:
1.用于对where执行结果进行分组
2)简单例子:
eg1:
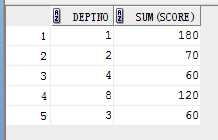
select sum(score), deptno from student group by deptno;
结果:
eg2:
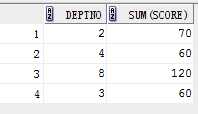
select deptno,sum(score) from student where deptno>1 group by deptno;
结果:
1)说明:
1. where和having都是用来筛选数据,但是执行的顺序不同 where --group by--having(即分组计算前计算where语句,分组计算后计算having‘语句),详情查看章节一sql执行顺序
2. having一般用来对分组后的数据进行筛选
3. where中不能使用聚组函数如sum,count,max等
2)例子:
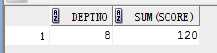
eg1: 对 5 中group by 的数据筛选
select deptno,sum(score) from student where deptno>1 group by deptno having sum(score)>100;
结果:
1)说明:
1. decode更简洁
2. decode只能做等值的条件区分,case when可以使用区间的做判断
2)语法:
decode(条件,值1,返回值1,值2,返回值2,...值n,返回值n,缺省值)
--等价于:
IF 条件=值1 THEN
RETURN(翻译值1)
ELSIF 条件=值2 THEN
RETURN(翻译值2)
......
ELSIF 条件=值n THEN
RETURN(翻译值n)
ELSE
RETURN(缺省值)
END IF
CASE expr WHEN comparison_expr1 THEN return_expr1
[WHEN comparison_expr2 THEN return_expr2
WHEN comparison_exprn THEN return_exprn
ELSE else_expr]
END
CASE
WHEN comparison_expr1 THEN return_expr1
[WHEN comparison_expr2 THEN return_expr2
WHEN comparison_exprn THEN return_exprn
ELSE else_expr]
END
3)例子:
eg1:
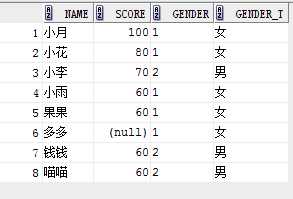
方式一:
select name, score,gender,
case gender when ‘1‘ then ‘女‘
when ‘2‘ then ‘男‘
else ‘未说明‘
end gender_t
from student;
方式二:
select name, score,gender,
case when gender=‘1‘ then ‘女‘
when gender=‘2‘ then ‘男‘
else ‘未说明‘
end gender_t
from student;
方式三:
select name,gender,decode(gender,‘1‘,‘女‘,‘2‘,‘男‘,‘未说明‘)gender_t from student;
结果:
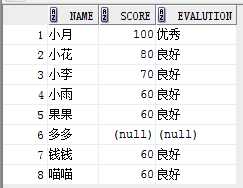
eg2:
select name,score,
case when score >80 then‘优秀‘
when score>=60 and score <=80 then ‘良好‘
when score<60 then ‘不及格‘
end evalution
from student;
结果:
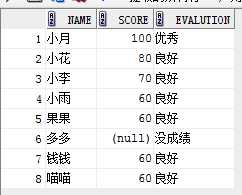
设置默认值,将null置为没成绩:
select name,score,
case when score >80 then‘优秀‘
when score>=60 and score <=80 then ‘良好‘
when score<60 then ‘不及格‘
else ‘没成绩‘
end evalution
from student;
结果:
4)注意:
1.case有两种形式,其中case 表达式 when then方式效率高于case when 表达式效率
2.使用decode函数可以避免重复扫描相同记录或者重复连接相同的表,因而某些情况可以减少处理时间
1)目标:减少服务器资源消耗(主要是磁盘IO)
2)设计:
1. 尽量依赖oracle优化器
2. 合适的索引(数据重复量大的列不要简历二叉树索引,可以使用位图索引; 对应数据操作频繁的表,索引需要定期重建,减少失效的索引和碎片)
3)编码:
1.利用索引
2. 合理利用临时表
3. 避免写过于复杂的sql;
4. 尽量减小事务的粒度
1)查询时尽量使用确定的列名
2)尽量少使用嵌套的子查询,这种查询很消耗cpu资源
3)多表查询的时候,选择最有效率的表名顺序
oracle解析器对表的处理顺序从右到左,所以记录少的表放在右边(最右边的表为基础表,drivering table最先被处理), 如果3个以上的表连接查询,则要选择交叉表作为基础表
4)or比较多时分为多个查询,使用union all(尽量用union all代替union)联结(适应于索引列)
详细见上一章节union和union all
5) 尽量多用commit提交事务,可以及时释放资源、解锁、释放日志
6)访问频繁的表可以放置在内存中
7)避免复杂的多表关联
8)避免distinct,union(并集),minus(差集),intersect(交集),order by等耗费资源的操作,因为会执行耗费资源的排序功能
9)使用exists替代distinct
标签:控制 优化 first 需要 替代 规则 gif sql优化 last
原文地址:https://www.cnblogs.com/ylpython/p/9537325.html