标签:分布 传统 完成 on() sam param lam spatial iar
Google Inception Net首次出现在ILSVRC 2014比赛中,就以较大优势获得第一名。那届的Inception Net被称为Inception Net V1,它最大的特点就是控制了计算量和参数量的同时,获得了非常好的分类性能——top-5错误率6.67%,只有AlexNet的一半不到。Inception Net V1有22层深,比AlexNet的8层或者VGGNet的19层还要更深。但其计算量只有15亿次浮点运算,同时只有500万的参数量,仅为AlexNet参数量(6000万)的1/12。却可以达到远胜AlexNet的准确率。Inception V1降低参数的目的有两个:第一,参数越多模型越庞大,需要提供学习的数据量越大,而目前高质量的数据非常昂贵;第二,参数越多,耗费的计算资源也会更大。
Inception V1参数少效果好的原因除了模型层数更深、表达能力更强外,还有两点:一是去除了最后的全连接层,用全局平均池化层(即将图片尺寸变为1*1来取代它)。全连接层几乎占据了AlexNet和VGGNet中90%的参数量,而且会引起过拟合。用全局平均池化层取代全连接层的做法借鉴了Network In Network(简称NIN)论文。二是Inception V1中精心设计了Inception Module 提高了参数的利用率。这一部分也借鉴了NIN的思想,形象的解释是Inception Module 本身如同大网络中的小网络,其结构可以反复堆叠在一起形成大网络。不过Inception V1比NIN更进一步的是增加了分支网络,NIN则主要是级联的卷积层和MLPConv层。一般来说卷积层要提升表达能力,主要依靠增加输出通道数,但副作用是计算量增大和过拟合。每一个输出通道对应一个滤波器,同一个滤波器共享参数,只能提取一类特征,因此一个输出通道只能做一种特征处理。而NIN中的MLPConv则拥有更强大的能力,允许在输出通道之间组合信息,因此效果更明显。可以说,MLPConv基本等效于普通卷积层后再连接1*1的卷积和ReLU激活函数。
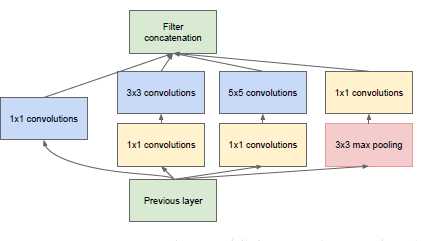
图1
上图是Inception Module 的基本结构,其中有4个分支:第一个分支对输入进行了1*1的卷积,这其实也是NIN总提出的一个重要结构。1*1卷积是一个非常优秀的结构,它可以跨通道组织信息,提高网络的表达能力,同时可以对输出通道升维和降维。可以看到Inception Module的4个分支都用了1*1卷积,来进行低成本(计算量比3*3小很多)的跨通道的特征变换。第二个分支先使用了1*1卷积,然后连接3*3卷积,相当于进行了两次特征变换。第三次分支类似,先是1*1的卷积,然后连接5*5的卷积。最后一个分支则是3*3最大池化后直接使用1*1卷积。可以发现,有的分支只使用1*1卷积,有的分支使用了其他尺寸的卷积后也会再使用1*1卷积,这是因为1*1卷积的性价比很高,用很小的计算量就能增加一层特征变换和非线性化。
Inception Module 的4个分支在最后通过一个聚合操作合并(在输出通道数这个维度聚合)。Inception Module中包含了3种不同尺寸的卷积和1个最大池化,增加了网络对不同尺度的适应性,这一部分和Multi-Scale的思想类似。早期计算机视觉的研究中,受灵长类神经视觉系统的启发,Serre使用不同尺寸的Gabor滤波器处理不同尺寸的图片,Inception V!借鉴了这种思想。Inception V1的论文中指出,Inception Module可以让网络的深度和宽度高效率地扩充,提升准确率且不至于过拟合。
稀疏结构是非常适合神经网络的结构,Inception Net的主要目标就是要找到最优的稀疏结构单元(即Inception Module)。一个“好”的稀疏结构,应该是符合Hebbian原理的,即把相关性高的一簇神经元节点连接在一起。在图片中,一个1*1的卷积就可以把这些相关性很高的、在同一个空间位置但是不同通道的特征连接在一起,这就是为什么1*1卷积这么频繁地被应用到Inception Net中的原因。而稍微大一点尺寸的卷积,比如3*3,5*5的卷积所连接的节点相关性也很高,因此也可以适当地使用一些大尺寸据卷积,增加多样性。最终,Inception Module 如上图设计,符合Hebbian原理,完成了设计初衷。
整个网络中,会有多个堆叠的Inception Module ,我们希望靠后的Inception Module 可以铺货更高阶的抽象特征,因此,靠后的Inception Module中,3*3,5*5这两个大面积的卷积核的占比(输出通道数)应该更多。
Inception Net有22层深,除了最后一层的输出,其中间节点的分类效果也很好。因此在Inception Net中,还使用了辅助分类节点(auxiliary classifiers),即将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终的分类结果中。这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个Inception Net的训练大有裨益。
Inception Net 家族:
1.2014年,Inception V1 ,top-5错误率6.67%。
2.2015年,Inception V2,top-5错误率4.8%。
3.2015年,Inception V3,top-5错误率3.5%。
4.2016年,Inception V4,top-5错误率3.08%。
Inception V2学习了VGGnet,用两个3*3的卷积代替5*5的大卷积(用于降低参数量并减轻过拟合),还提出了著名的Batch Normalization(BN)方法。BN是一种非常有效的正则化方法,可以让大型卷积网络的训练速度加快很多倍,同时收敛后的分类准确率也可以得到大幅提高。BN在用于神经网络某层时,会对每一个mini-batch数据的内部进行标准化处理,使得输出规范化到N(0,1)的正态分布,减少了内部神经元分布的改变。BN的论文中提出,传统的深度网络再训练时,每一层的输入的分布都在变化,导致训练变得困难,我们只能使用一个很小的学习速率解决这个问题。而对每一层使用BN之后,我们就可以有效的解决这个问题,学习速率可以增大很多倍,达到之前的准确率所需要的迭代次数只有1/4,训练时间大大缩短。而且还可以继续训练,最终超过Inception V1。
单纯使用BN还不够,还需要:1.增大学习速率并加快学习衰减速度以使用BN规范化后的数据;2.去除Dropout并减轻L2正则化,因为BN已经起到正则化的作用;3.去除LRN;4.更彻底地对数据进行shuffle;5.减少数据增强过程中对数据的光学畸形,因为BN训练更快,每个样本被训练的次数更少,因此更真实的样本对训练更有帮助。在使用这些措施之后,Inception V2再达到Inception V1的准确率时快了14倍,并且模型在收敛时准确率的上限更高。
Inception V3主要有两方面的改造:一是引入了Factorization into small convolution的思想,将一个较大的二维卷积拆成两个较小的一维卷积,比如7*7卷积拆成1*7卷积和7*1卷积。如下图2所示。这样节约了大量参数,加速运算并减轻了过拟合,同时增加一层非线性扩展模型表达能力。论文中指出,这种非对称的卷积结构拆分,其结果比对此地拆成几个相同的小卷积效果更明显,可以处理更多、更丰富的空间特征,增加特征多样性。
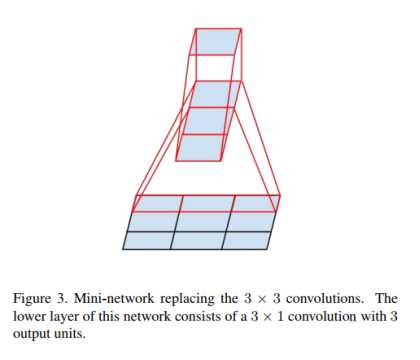
图2
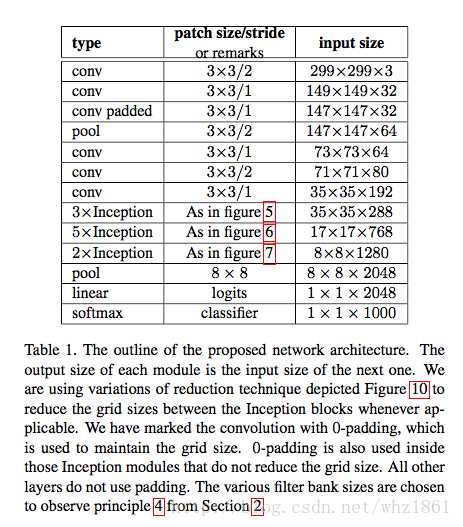
二是Inception V3优化了Inception Module的结构,现在Inception Module有35*35、17*17、8*8三种结构,如下图3,4,5所示。这些Inception Module 只在网络的后部出现,前部还是普通的卷积层。并且Inception V3除了在Inception Module中使用了分支,还在分支中使用了分支(8*8的结构中),可以说是Network in Network in Network。
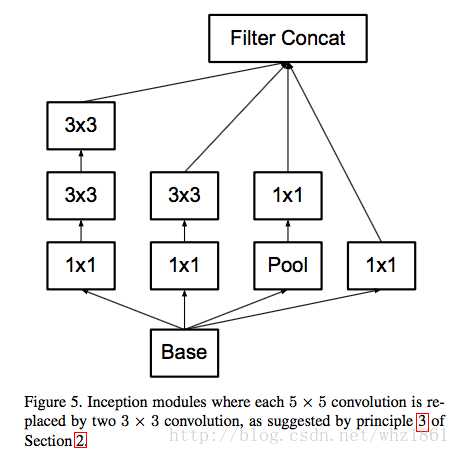
图3
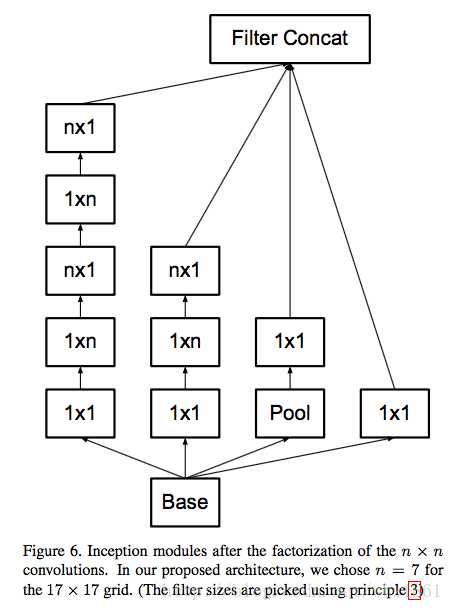
图4
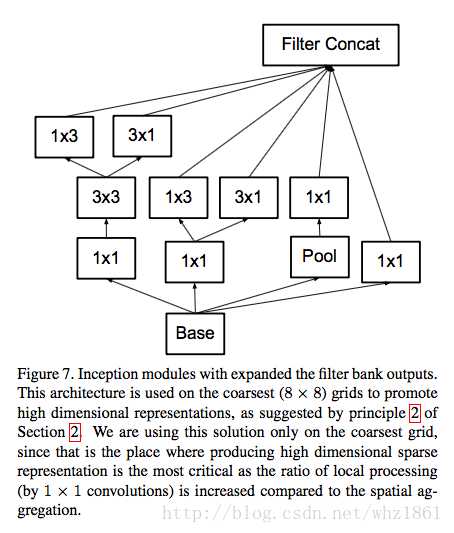
图5
Inception V4相比V3主要结合了微软的ResNet。
import tensorflow as tf
slim = tf.contrib.slim
trunc_normal = lambda stddev: tf.truncated_normal_initializer(0.0, stddev)
# 生成Inception V3的卷积部分
def inception_v3_base(inputs, scope=None):
# inputs 是输入图片的tensor
# scope 包含函数默认参数的环境
end_points = {} # 用来保存关键节点供之后使用
with tf.variable_scope(scope, ‘InceptionV3‘, [inputs]):
with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
stride=1, padding=‘VALID‘):
# 非Inception Module模块
# 299 x 299 x 3
net = slim.conv2d(inputs, 32, [3, 3], stride=2, scope=‘Conv2d_1a_3x3‘)
# 149 x 149 x 32
net = slim.conv2d(net, 32, [3, 3], scope=‘Conv2d_2a_3x3‘)
# 147 x 147 x 32
net = slim.conv2d(net, 64, [3, 3], padding=‘SAME‘, scope=‘Conv2d_2b_3x3‘)
# 147 x 147 x 64
net = slim.max_pool2d(net, [3, 3], stride=2, scope=‘MaxPool_3a_3x3‘)
# 73 x 73 x 64
net = slim.conv2d(net, 80, [1, 1], scope=‘Conv2d_3b_1x1‘)
# 73 x 73 x 80.
net = slim.conv2d(net, 192, [3, 3], scope=‘Conv2d_4a_3x3‘)
# 71 x 71 x 192.
net = slim.max_pool2d(net, [3, 3], stride=2, scope=‘MaxPool_5a_3x3‘)
# 35 x 35 x 192.
# Inception V3的精华所在
# Inception blocks
with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
stride=1, padding=‘SAME‘):
# mixed: 35 x 35 x 256.
with tf.variable_scope(‘Mixed_5b‘):
with tf.variable_scope(‘Branch_0‘):
branch_0 = slim.conv2d(net, 64, [1, 1], scope=‘Conv2d_0a_1x1‘)
with tf.variable_scope(‘Branch_1‘):
branch_1 = slim.conv2d(net, 48, [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope=‘Conv2d_0b_5x5‘)
with tf.variable_scope(‘Branch_2‘):
branch_2 = slim.conv2d(net, 64, [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope=‘Conv2d_0b_3x3‘)
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope=‘Conv2d_0c_3x3‘)
with tf.variable_scope(‘Branch_3‘):
branch_3 = slim.avg_pool2d(net, [3, 3], scope=‘AvgPool_0a_3x3‘)
branch_3 = slim.conv2d(branch_3, 32, [1, 1], scope=‘Conv2d_0b_1x1‘)
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
#35 x 35 x 256
# mixed_1: 35 x 35 x 288.通道增加了32
with tf.variable_scope(‘Mixed_5c‘):
with tf.variable_scope(‘Branch_0‘):
branch_0 = slim.conv2d(net, 64, [1, 1], scope=‘Conv2d_0a_1x1‘)
with tf.variable_scope(‘Branch_1‘):
branch_1 = slim.conv2d(net, 48, [1, 1], scope=‘Conv2d_0b_1x1‘)
branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope=‘Conv_1_0c_5x5‘)
with tf.variable_scope(‘Branch_2‘):
branch_2 = slim.conv2d(net, 64, [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope=‘Conv2d_0b_3x3‘)
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope=‘Conv2d_0c_3x3‘)
with tf.variable_scope(‘Branch_3‘):
branch_3 = slim.avg_pool2d(net, [3, 3], scope=‘AvgPool_0a_3x3‘)
branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope=‘Conv2d_0b_1x1‘)
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
# mixed_2: 35 x 35 x 288.
with tf.variable_scope(‘Mixed_5d‘):
with tf.variable_scope(‘Branch_0‘):
branch_0 = slim.conv2d(net, 64, [1, 1], scope=‘Conv2d_0a_1x1‘)
with tf.variable_scope(‘Branch_1‘):
branch_1 = slim.conv2d(net, 48, [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope=‘Conv2d_0b_5x5‘)
with tf.variable_scope(‘Branch_2‘):
branch_2 = slim.conv2d(net, 64, [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope=‘Conv2d_0b_3x3‘)
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope=‘Conv2d_0c_3x3‘)
with tf.variable_scope(‘Branch_3‘):
branch_3 = slim.avg_pool2d(net, [3, 3], scope=‘AvgPool_0a_3x3‘)
branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope=‘Conv2d_0b_1x1‘)
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
# mixed_3: 17 x 17 x 768.
with tf.variable_scope(‘Mixed_6a‘):
with tf.variable_scope(‘Branch_0‘):
branch_0 = slim.conv2d(net, 384, [3, 3], stride=2,
padding=‘VALID‘, scope=‘Conv2d_1a_1x1‘)
with tf.variable_scope(‘Branch_1‘):
branch_1 = slim.conv2d(net, 64, [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_1 = slim.conv2d(branch_1, 96, [3, 3], scope=‘Conv2d_0b_3x3‘)
branch_1 = slim.conv2d(branch_1, 96, [3, 3], stride=2,
padding=‘VALID‘, scope=‘Conv2d_1a_1x1‘)
with tf.variable_scope(‘Branch_2‘):
branch_2 = slim.max_pool2d(net, [3, 3], stride=2, padding=‘VALID‘,
scope=‘MaxPool_1a_3x3‘)
net = tf.concat([branch_0, branch_1, branch_2], 3)
# 17 x 17 x 768
# mixed4: 17 x 17 x 768.
with tf.variable_scope(‘Mixed_6b‘):
with tf.variable_scope(‘Branch_0‘):
branch_0 = slim.conv2d(net, 192, [1, 1], scope=‘Conv2d_0a_1x1‘)
with tf.variable_scope(‘Branch_1‘):
branch_1 = slim.conv2d(net, 128, [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_1 = slim.conv2d(branch_1, 128, [1, 7], scope=‘Conv2d_0b_1x7‘)
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope=‘Conv2d_0c_7x1‘)
with tf.variable_scope(‘Branch_2‘):
branch_2 = slim.conv2d(net, 128, [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_2 = slim.conv2d(branch_2, 128, [7, 1], scope=‘Conv2d_0b_7x1‘)
branch_2 = slim.conv2d(branch_2, 128, [1, 7], scope=‘Conv2d_0c_1x7‘)
branch_2 = slim.conv2d(branch_2, 128, [7, 1], scope=‘Conv2d_0d_7x1‘)
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope=‘Conv2d_0e_1x7‘)
with tf.variable_scope(‘Branch_3‘):
branch_3 = slim.avg_pool2d(net, [3, 3], scope=‘AvgPool_0a_3x3‘)
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope=‘Conv2d_0b_1x1‘)
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
# 17 x 17 x 768
# mixed_5: 17 x 17 x 768.
with tf.variable_scope(‘Mixed_6c‘):
with tf.variable_scope(‘Branch_0‘):
branch_0 = slim.conv2d(net, 192, [1, 1], scope=‘Conv2d_0a_1x1‘)
with tf.variable_scope(‘Branch_1‘):
branch_1 = slim.conv2d(net, 160, [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_1 = slim.conv2d(branch_1, 160, [1, 7], scope=‘Conv2d_0b_1x7‘)
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope=‘Conv2d_0c_7x1‘)
with tf.variable_scope(‘Branch_2‘):
branch_2 = slim.conv2d(net, 160, [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope=‘Conv2d_0b_7x1‘)
branch_2 = slim.conv2d(branch_2, 160, [1, 7], scope=‘Conv2d_0c_1x7‘)
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope=‘Conv2d_0d_7x1‘)
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope=‘Conv2d_0e_1x7‘)
with tf.variable_scope(‘Branch_3‘):
branch_3 = slim.avg_pool2d(net, [3, 3], scope=‘AvgPool_0a_3x3‘)
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope=‘Conv2d_0b_1x1‘)
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
# mixed_6: 17 x 17 x 768.
with tf.variable_scope(‘Mixed_6d‘):
with tf.variable_scope(‘Branch_0‘):
branch_0 = slim.conv2d(net, 192, [1, 1], scope=‘Conv2d_0a_1x1‘)
with tf.variable_scope(‘Branch_1‘):
branch_1 = slim.conv2d(net, 160, [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_1 = slim.conv2d(branch_1, 160, [1, 7], scope=‘Conv2d_0b_1x7‘)
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope=‘Conv2d_0c_7x1‘)
with tf.variable_scope(‘Branch_2‘):
branch_2 = slim.conv2d(net, 160, [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope=‘Conv2d_0b_7x1‘)
branch_2 = slim.conv2d(branch_2, 160, [1, 7], scope=‘Conv2d_0c_1x7‘)
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope=‘Conv2d_0d_7x1‘)
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope=‘Conv2d_0e_1x7‘)
with tf.variable_scope(‘Branch_3‘):
branch_3 = slim.avg_pool2d(net, [3, 3], scope=‘AvgPool_0a_3x3‘)
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope=‘Conv2d_0b_1x1‘)
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
# mixed_7: 17 x 17 x 768.
with tf.variable_scope(‘Mixed_6e‘):
with tf.variable_scope(‘Branch_0‘):
branch_0 = slim.conv2d(net, 192, [1, 1], scope=‘Conv2d_0a_1x1‘)
with tf.variable_scope(‘Branch_1‘):
branch_1 = slim.conv2d(net, 192, [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_1 = slim.conv2d(branch_1, 192, [1, 7], scope=‘Conv2d_0b_1x7‘)
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope=‘Conv2d_0c_7x1‘)
with tf.variable_scope(‘Branch_2‘):
branch_2 = slim.conv2d(net, 192, [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_2 = slim.conv2d(branch_2, 192, [7, 1], scope=‘Conv2d_0b_7x1‘)
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope=‘Conv2d_0c_1x7‘)
branch_2 = slim.conv2d(branch_2, 192, [7, 1], scope=‘Conv2d_0d_7x1‘)
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope=‘Conv2d_0e_1x7‘)
with tf.variable_scope(‘Branch_3‘):
branch_3 = slim.avg_pool2d(net, [3, 3], scope=‘AvgPool_0a_3x3‘)
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope=‘Conv2d_0b_1x1‘)
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
end_points[‘Mixed_6e‘] = net # 做为Auxiliary Classifier辅助模型的分类
# mixed_8: 8 x 8 x 1280.
with tf.variable_scope(‘Mixed_7a‘):
with tf.variable_scope(‘Branch_0‘):
branch_0 = slim.conv2d(net, 192, [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_0 = slim.conv2d(branch_0, 320, [3, 3], stride=2,
padding=‘VALID‘, scope=‘Conv2d_1a_3x3‘)
with tf.variable_scope(‘Branch_1‘):
branch_1 = slim.conv2d(net, 192, [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_1 = slim.conv2d(branch_1, 192, [1, 7], scope=‘Conv2d_0b_1x7‘)
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope=‘Conv2d_0c_7x1‘)
branch_1 = slim.conv2d(branch_1, 192, [3, 3], stride=2,
padding=‘VALID‘, scope=‘Conv2d_1a_3x3‘)
with tf.variable_scope(‘Branch_2‘):
branch_2 = slim.max_pool2d(net, [3, 3], stride=2, padding=‘VALID‘,
scope=‘MaxPool_1a_3x3‘)
net = tf.concat([branch_0, branch_1, branch_2], 3)
# 8 x 8 x 1280 ,图片的尺寸缩小了,同时通道数也增加了
# mixed_9: 8 x 8 x 2048.
with tf.variable_scope(‘Mixed_7b‘):
with tf.variable_scope(‘Branch_0‘):
branch_0 = slim.conv2d(net, 320, [1, 1], scope=‘Conv2d_0a_1x1‘)
with tf.variable_scope(‘Branch_1‘):
branch_1 = slim.conv2d(net, 384, [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_1 = tf.concat([
slim.conv2d(branch_1, 384, [1, 3], scope=‘Conv2d_0b_1x3‘),
slim.conv2d(branch_1, 384, [3, 1], scope=‘Conv2d_0b_3x1‘)], 3)
with tf.variable_scope(‘Branch_2‘):
branch_2 = slim.conv2d(net, 448, [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_2 = slim.conv2d(
branch_2, 384, [3, 3], scope=‘Conv2d_0b_3x3‘)
branch_2 = tf.concat([
slim.conv2d(branch_2, 384, [1, 3], scope=‘Conv2d_0c_1x3‘),
slim.conv2d(branch_2, 384, [3, 1], scope=‘Conv2d_0d_3x1‘)], 3)
with tf.variable_scope(‘Branch_3‘):
branch_3 = slim.avg_pool2d(net, [3, 3], scope=‘AvgPool_0a_3x3‘)
branch_3 = slim.conv2d(
branch_3, 192, [1, 1], scope=‘Conv2d_0b_1x1‘)
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
# mixed_10: 8 x 8 x 2048.
with tf.variable_scope(‘Mixed_7c‘):
with tf.variable_scope(‘Branch_0‘):
branch_0 = slim.conv2d(net, 320, [1, 1], scope=‘Conv2d_0a_1x1‘)
with tf.variable_scope(‘Branch_1‘):
branch_1 = slim.conv2d(net, 384, [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_1 = tf.concat([
slim.conv2d(branch_1, 384, [1, 3], scope=‘Conv2d_0b_1x3‘),
slim.conv2d(branch_1, 384, [3, 1], scope=‘Conv2d_0c_3x1‘)], 3)
with tf.variable_scope(‘Branch_2‘):
branch_2 = slim.conv2d(net, 448, [1, 1], scope=‘Conv2d_0a_1x1‘)
branch_2 = slim.conv2d(
branch_2, 384, [3, 3], scope=‘Conv2d_0b_3x3‘)
branch_2 = tf.concat([
slim.conv2d(branch_2, 384, [1, 3], scope=‘Conv2d_0c_1x3‘),
slim.conv2d(branch_2, 384, [3, 1], scope=‘Conv2d_0d_3x1‘)], 3)
with tf.variable_scope(‘Branch_3‘):
branch_3 = slim.avg_pool2d(net, [3, 3], scope=‘AvgPool_0a_3x3‘)
branch_3 = slim.conv2d(
branch_3, 192, [1, 1], scope=‘Conv2d_0b_1x1‘)
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
return net, end_points
# 首先是5个卷积层和2个池化层交替的普通结构,然后是3个Inception模块组,每个模块组包含多个结构类似的Inception module。
# Inception V3最后一部分,全局平均池化,Softmax和Auxiliary Logits
def inception_v3(inputs,
num_classes=1000, # 最后需要分类的数量
is_training=True, # 是否是训练过程,对BN和Dropout有影响
dropout_keep_prob=0.8, # Dropout保留节点的比例
prediction_fn=slim.softmax, # 用来分类函数
spatial_squeeze=True, # 是否对输出进行squeeze操作,如5*5*1转为5*5(去维数为1的维度)
reuse=None, # 是否会对网络和Variable进行重复使用
scope=‘InceptionV3‘): # 包含了函数默认参数的环境
with tf.variable_scope(scope, ‘InceptionV3‘, [inputs, num_classes],
reuse=reuse) as scope:
with slim.arg_scope([slim.batch_norm, slim.dropout],
is_training=is_training):
net, end_points = inception_v3_base(inputs, scope=scope)
# Auxiliary Head logits
with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
stride=1, padding=‘SAME‘):
aux_logits = end_points[‘Mixed_6e‘]
with tf.variable_scope(‘AuxLogits‘):
aux_logits = slim.avg_pool2d(
aux_logits, [5, 5], stride=3, padding=‘VALID‘,
scope=‘AvgPool_1a_5x5‘)
aux_logits = slim.conv2d(aux_logits, 128, [1, 1],
scope=‘Conv2d_1b_1x1‘)
# Shape of feature map before the final layer.
aux_logits = slim.conv2d(
aux_logits, 768, [5,5],
weights_initializer=trunc_normal(0.01),
padding=‘VALID‘, scope=‘Conv2d_2a_5x5‘)
aux_logits = slim.conv2d(
aux_logits, num_classes, [1, 1], activation_fn=None,
normalizer_fn=None, weights_initializer=trunc_normal(0.001),
scope=‘Conv2d_2b_1x1‘)
if spatial_squeeze:
aux_logits = tf.squeeze(aux_logits, [1, 2], name=‘SpatialSqueeze‘)
end_points[‘AuxLogits‘] = aux_logits
# Final pooling and prediction
with tf.variable_scope(‘Logits‘):
net = slim.avg_pool2d(net, [8, 8], padding=‘VALID‘,
scope=‘AvgPool_1a_8x8‘)
# 1 x 1 x 2048
net = slim.dropout(net, keep_prob=dropout_keep_prob, scope=‘Dropout_1b‘)
end_points[‘PreLogits‘] = net
# 2048
logits = slim.conv2d(net, num_classes, [1, 1], activation_fn=None,
normalizer_fn=None, scope=‘Conv2d_1c_1x1‘)
if spatial_squeeze:
logits = tf.squeeze(logits, [1, 2], name=‘SpatialSqueeze‘)
# 1000
end_points[‘Logits‘] = logits
end_points[‘Predictions‘] = prediction_fn(logits, scope=‘Predictions‘)
return logits, end_points
# 用来生成网络中经常用到的函数的默认参数
def inception_v3_arg_scope(weight_decay=0.00004, # L2正则的weight_decay默认值
stddev=0.1, # 标准差
batch_norm_var_collection=‘moving_vars‘):
batch_norm_params = { # batch normalization的参数字典
‘decay‘: 0.9997, # 衰减系数
‘epsilon‘: 0.001,
‘updates_collections‘: tf.GraphKeys.UPDATE_OPS,
‘variables_collections‘: {
‘beta‘: None,
‘gamma‘: None,
‘moving_mean‘: [batch_norm_var_collection],
‘moving_variance‘: [batch_norm_var_collection],
}
}
with slim.arg_scope([slim.conv2d, slim.fully_connected], # 能够给函数的参数自动赋予某些默认值
weights_regularizer=slim.l2_regularizer(weight_decay)):
with slim.arg_scope(
[slim.conv2d],
weights_initializer=trunc_normal(stddev),
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params) as sc:
return sc
# 这个函数事先定义好了slim.conv2d中的各种默认参数,包括激活函数和标准化器,后面可以一行定义一个卷基层
网络每经过一个Inception Module ,即使输出tensor尺寸不变,但是特征都相当于精炼了一遍,其中丰富的卷积和非线性对提升网络性能帮助很大。
每一层卷积、池化或者Inception模块组的目的都是将空间结构简化,同时将空间信息转化为高阶抽象的特征信息,即将空间的维度转为通道的维度。可以发现Inception Module的规律,一般情况下有4个分支,第一个分支一般是1*1卷积,第二个分支一般是1*1卷积再接分解后的1*n和n*1卷积,第三个分支和第二个分支类似,但是更深一些,第四个分支一般具有最大池化或者平均池化。因此,Inception Module是通过组合比较简单的特征抽象(分支1)、比较复杂的特征抽象(分支2和3)和一个简化结构的池化层(分支4),一共4种不同程度的特征抽象和变换来有选择地保留不同层次的高阶特征,这样可以最大程度地丰富网络的表达能力。
from datetime import datetime
import math
import time
def time_tensorflow_run(session, target, info_string):
num_steps_burn_in = 10
total_duration = 0.0
total_duration_squared = 0.0
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target)
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print (‘%s: step %d, duration = %.3f‘ %
(datetime.now(), i - num_steps_burn_in, duration))
total_duration += duration
total_duration_squared += duration * duration
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn * mn
sd = math.sqrt(vr)
print (‘%s: %s across %d steps, %.3f +/- %.3f sec / batch‘ %
(datetime.now(), info_string, num_batches, mn, sd))
batch_size = 32
height, width = 299, 299
inputs = tf.random_uniform((batch_size, height, width, 3))
with slim.arg_scope(inception_v3_arg_scope()):
logits, end_points = inception_v3(inputs, is_training=False)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
num_batches=100
time_tensorflow_run(sess, logits, "Forward")
Inception V3有2500万个参数量,仍然不到AlexNet的6000万参数量的一半,相比VGGNet的1.4亿参数量更少。较小的计算量让Inception V3变得更加实用,甚至可以移植到手机上进行实时的图像识别。Inception V3中一些值得借鉴的思想:
1.Factorization into samll convolutions很有效,可以降低参数量、减轻过拟合、增加网络非线性的表达能力。
2.卷积网络从输入到输出,应该让图片尺寸逐渐减小,输出通道数逐渐增加,即让空间结构简化,将空间信息转化为高阶抽象的特征信息。
3.Inception Module 用多个分支提取不同抽象程度的高阶特征的思路很有效,可以丰富网络的表达能力。
【TensorFlow实战】TensorFlow实现经典卷积神经网络之Google Inception Net
标签:分布 传统 完成 on() sam param lam spatial iar
原文地址:https://www.cnblogs.com/Negan-ZW/p/9534494.html