标签:== .com 内存不足 频繁 大于 交换分区 时间间隔 大量 存在
一、使用说明
vmstat 可以对操作系统的内存信息、进程状态、CPU 活动、磁盘等信息进行监控,不足之处是无法对某个进程进行深入分析。
二、用法及参数说明

三、结果说明

2表示两秒采集一次服务器状态,5表示采集5次。在实际运用过程中,一般会在一段时间内一直监控,不想监控直接结束就行了,如下:
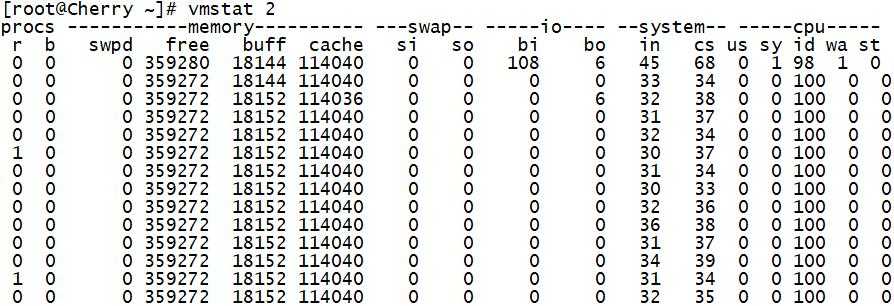
重点参数:r,b,swpd,free,buff,cache,si,so,bi,bo
四、性能分析信息
1、IO/CPU/men连锁反应
2、内存不足
3、io瓶颈
4、CPU瓶颈:load,vmstat中r列
标签:== .com 内存不足 频繁 大于 交换分区 时间间隔 大量 存在
原文地址:https://www.cnblogs.com/L-Test/p/9541306.html