标签:names coreos 断开连接 交换 删除 抽象 比特 eth 启用
Docker网络基础由于Kubernetes是基于Docker容器作为应用发布的载体,而Docker本身的网络特性也决定了Kubernetes在构建一个容器互通网络必须要解决Docker自身网络的缺陷。
为了支持网络协议栈的多个实例,Linux在网络命名空间中引入了网络命名空间(Network Namespace),这些网络协议栈被隔离到不同的命名空间中。不同的命名空间中资源完全隔离,彼此之间无法完全通信。通过不同的网络命名空间,就可以在一台宿主机上虚拟多个不同的网络环境。Docker正是利用了网络命令空间的特性实现了不同容器之间的网络隔离。
在Linux的网络命名空间中可以配置自己独立的iptables规则来设置包转发,NAT和包过滤等。
由于网络命名空间彼此隔离,无法直接通信,如果要打通两个隔离的网络命名空间,实现数据互通,就需要用到Veth设备对。Veth设备对的一个主要作用就是打通不同的网络协议栈,它就像是一个网线,两端分别连接不同的网络命名空间的协议栈。
如果想在两个命名空间之间进行通信,就必须有一个Veth设备对。
1、创建一个名为test的网络命名空间:
# ip netns add test2、在此命名空间中执行ip a命令
# ip netns exec test ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00如果想执行多个命令,可以直接进入此网络命名空间中执行:
# ip netns exec test sh
退出执行
# exit我们可以在不同的网络命名空间中转义设备,如上面提到的Veth设备对,由于一个设备只能属于一个网络命名空间,所以当设备被转移后,在当前的命名空间中就无法查看到此设备了。
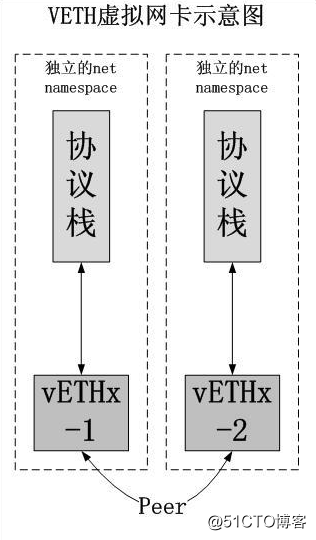
由于Veth需要连接两个不同的网络命名空间,所以Veth设备一般是成对出现的,称其中一端为另一端的peer。
1、创建Veth设备对
# ip link add veth0 type veth peer name veth1创建一个veth设备对,本端为veth0, 对端为veth1
2、查看设备对:
# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT qlen 1000
link/ether 52:54:00:7f:52:5a brd ff:ff:ff:ff:ff:ff
3: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether 26:3f:dd:c0:70:cb brd ff:ff:ff:ff:ff:ff
4: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether a2:91:f4:9c:5b:6b brd ff:ff:ff:ff:ff:ff
3、将veth1 分配到test网络命名空间中:
# ip link set veth1 netns test
4、查看当前设备对情况:
# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT qlen 1000
link/ether 52:54:00:7f:52:5a brd ff:ff:ff:ff:ff:ff
4: veth0@if3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether a2:91:f4:9c:5b:6b brd ff:ff:ff:ff:ff:ff link-netnsid 0
5、查看test网络命名空间的情况,发现此设备对已经分配进来:
# ip netns exec test ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
3: veth1@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 26:3f:dd:c0:70:cb brd ff:ff:ff:ff:ff:ff link-netnsid 0
6、由于两端的设备对还没有地址,所以无法通信,现在分别分配地址:
ip addr add 172.16.0.1/24 dev veth0 # 给本端的veth0分配ip地址
ip netns exec test ip addr add 172.16.0.2/24 dev veth1 # 为对端的veth1 配置IP
7、可以查看veth的状态,默认情况下都为DOWN:
# ip a|grep veth
4: veth0@if3: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast state DOWN qlen 1000
inet 172.16.0.1/24 scope global veth0
# ip netns exec test ip a|grep veth
3: veth1@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast state DOWN qlen 1000
inet 172.16.0.2/24 scope global veth1
8、启动veth设备对,查看网络是否打通:
# ip link set dev veth0 up
# ip netns exec test ip link set dev veth1 up
# ping 172.16.0.2
PING 172.16.0.2 (172.16.0.2) 56(84) bytes of data.
64 bytes from 172.16.0.2: icmp_seq=1 ttl=64 time=0.150 ms
64 bytes from 172.16.0.2: icmp_seq=2 ttl=64 time=0.028 ms
9、查看对端设备
当设备对比较多的情况下,无法确认对端的设备是属于哪个设备对的,可以使用ethtool命令来查看对端的设备编号:
# ethtool -S veth0 # 查看veth0的对端设备编号
NIC statistics:
peer_ifindex: 3 # 这里显示的对端的设备编号为3
# ip netns exec test ip link |grep 3: # 对端设备编号为3的设备信息
3: veth1@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT qlen 1000
# 本地的veth0 编号为4
# ip link |grep veth
4: veth0@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT qlen 1000
#在对端验证
# ip netns exec test ethtool -S veth1
NIC statistics:
peer_ifindex: 4
Linux中的网桥和现实中的交换机类似,是一个虚拟的二层设备。网桥上可以attach若干个网络接口设备,如eth0,eth1等,当有数据到达网桥时,网桥会根据报文中MAC地址信息进行转发或丢弃处理。网桥会自动学习内部的MAC端口映射,并会周期性的更新。
网桥和现实中的设备有一个区别,那就是从网络接口过来的数据会直接发送到网桥上,而不是从特定的端口接收。
网桥可以设置IP地址,当一个设备如eth0添加到网桥上之后,绑定在设备上的IP就无效了,如果要实现通信,需要给网桥配置一个IP。
1、如果要配置桥接网卡,需要安装bridge-utils工具:
# yum install bridge-utils -y2、添加一个网桥设备br0
# brctl addbr br0
3、将eth0添加到br0上(此步执行后,eth0上的IP会失效,虽然IP还在eth0上,但是无法接收数据,如果使用ssh将会断开连接):
# brctl addif br0 eth0 4、 删除eth0上的ip:
ip addr del dev eth0 10.0.0.1/245、给br0添加此IP
ifconfig br0 10.0.0.1/24 up6、给br0添加默认路由:
route add default gw 10.0.0.2547、我们可以通过如下命令查卡当前的路由信息:
ip route list
netstat -rn
route -n在纯Docker的环境,Docker支持4类网络模式:
由于Kubernetes中只使用bridge模式,所以这里只讨论bridge模式。
网络示例图:
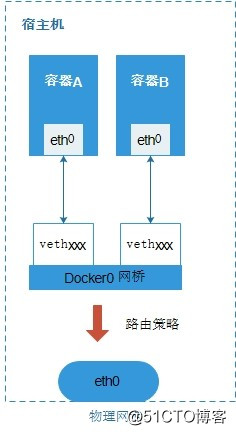
通过上图,可以清楚的表示容器的网络结构,其中容器中的网卡eth0和绑定在Docker0网桥上的vethxxx设备是一对veth设备对。其中vethxxx由于绑定到docker0网桥,所以没有IP地址,容器中的eth0分配了和docker0同一网段的地址,这样就实现了容器的互联。
通过查看运行两个容器的宿主:
# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:15:c2:12 brd ff:ff:ff:ff:ff:ff
inet 192.168.20.17/24 brd 192.168.20.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe15:c212/64 scope link
valid_lft forever preferred_lft forever
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
link/ether 02:42:fa:6f:13:18 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:faff:fe6f:1318/64 scope link
valid_lft forever preferred_lft forever
7: veth37e9040@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP
link/ether f2:4e:50:a5:fb:b8 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::f04e:50ff:fea5:fbb8/64 scope link
valid_lft forever preferred_lft forever
19: veth36fb1f6@if18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP
link/ether 7a:96:bc:c7:03:d8 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::7896:bcff:fec7:3d8/64 scope link
valid_lft forever preferred_lft forever
通过查看桥接网卡信息,可以验证这两个veth绑定在docker0上:
# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242fa6f1318 no veth36fb1f6
veth37e9040
默认情况下,docker隐藏了网络命名空间的配置,如果要通过ip netns list命令查看信息,需要进行如下操作:
# docker inspect 506a694d09fb|grep Pid
"Pid": 2737,
"PidMode": "",
"PidsLimit": 0,
# mkdir /var/run/netns
# ln -s /proc/2737/ns/net /var/run/netns/506a694d09fb
# ip netns list
506a694d09fb (id: 0)
6d9742fb3c2d (id: 1)
分别查看两个容器的IP:
# ip netns exec 506a694d09fb ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
6: eth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 scope global eth0
valid_lft forever preferred_lft foreve
# ip netns exec 6d9742fb3c2d ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
18: eth0@if19: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
link/ether 02:42:ac:11:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.3/16 scope global eth0
valid_lft forever preferred_lft forever
可以发现这两个容器属于不同网络命名空间,但是在同一网段,通过veth设备对,绑定docker0互联。
通过ethtool -S veth-name 可以查看到对应的peer端,这里就不再演示,其实通过veth的名称(vethxxx@ifNO)也可以发现所指的接口信息。
Kubernetes主要解决以下几个问题:
同一个Pod中的容器属于同一个网络命名空间,共享同一个Linux网络协议栈,通过本地的localhost网络来与Pod内的其他容器通信,pod中的容器如下图:
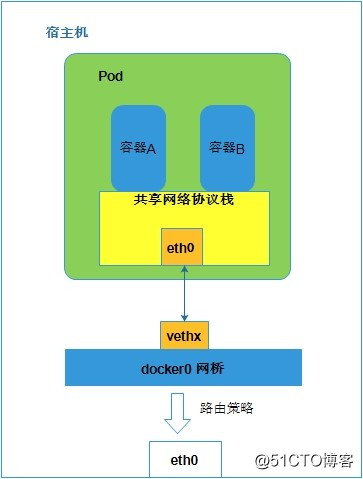
同宿主机上的通信示意图:
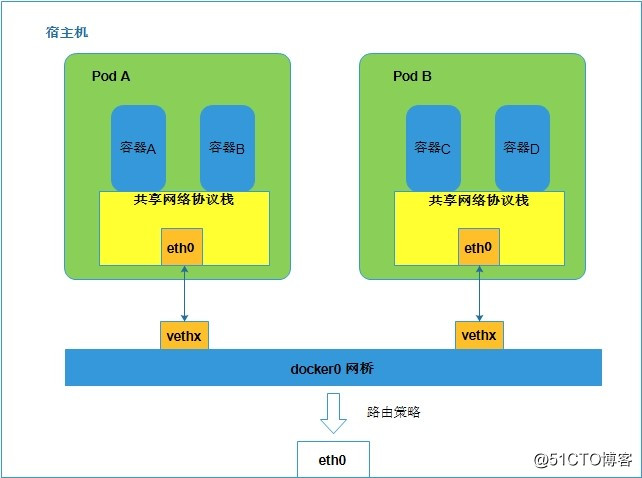
在宿主机内部通过docker0的桥接网卡,可以实现Pod之间的直接通信,这里和纯docker环境下的多个容器互通原理相似。
另一种情况是在不同宿主机上的不同Pod之间通信,其原理图如下:
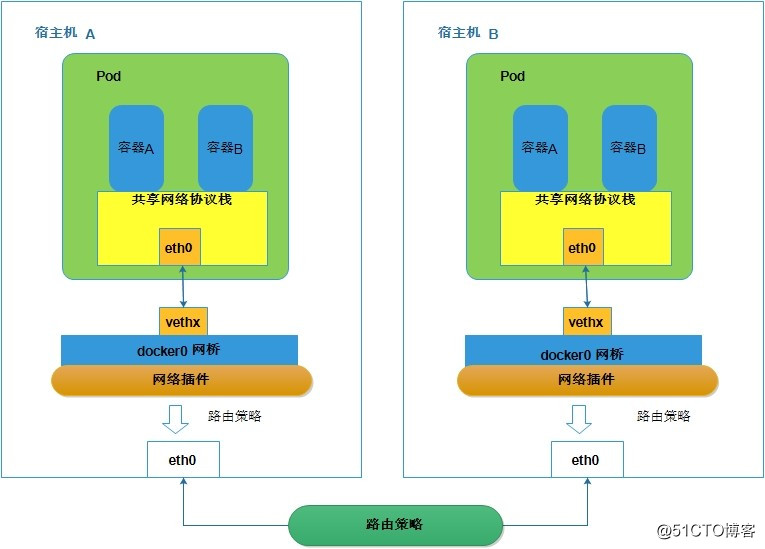
CNI是由CoreOS公司提出的一种容器网络规范,定义容器运行环境与网络插件之间的简单接口规范。
CNI模型涉及两个概念:
Kubernetes目前支持多种网络插件,可以使用CNI插件规范实现的接口,与插件提供者进行对接。当在Kubernetes中指定插件时,需要在kubelet服务启动参数中指定插件参数:
...
--network-plugin=cni --cni-conf-dir=/etc/cni/net.d \ # 此目录下的配置文件要符合CNI规范。
--cni-bin-dir=/opt/kubernetes/bin/cni ...目前有多个开源的项目支持以CNI网络插件的形式部署到Kubernetes,包括 Calico、Canal、Cilium、Contiv、Fannel、Romana、Weave等。
Flannel原理图:
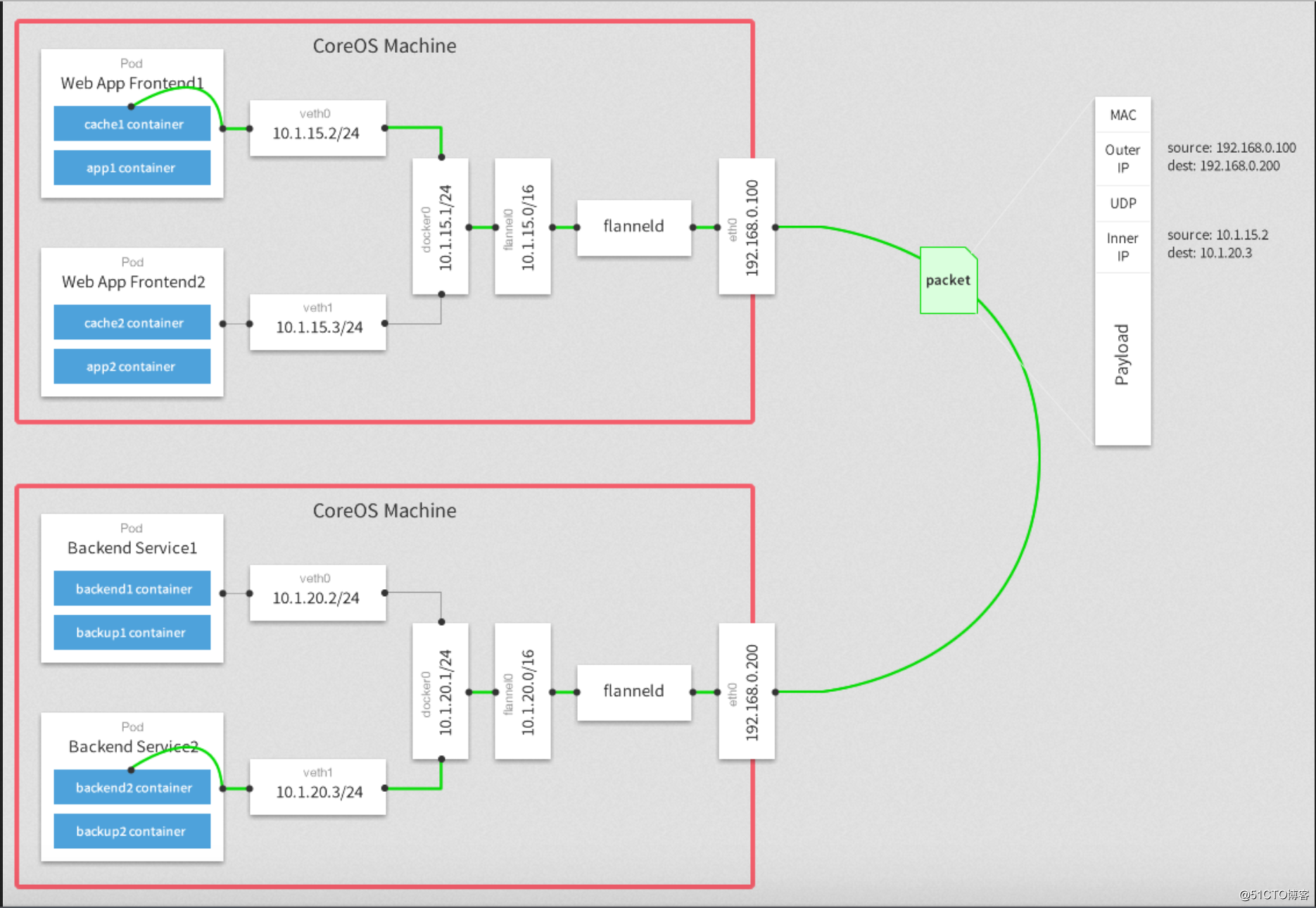
我们之所以要单独使用第三方的网络插件来扩展k8s,主要原因是在使用docker的环境中,在每个node节点的docker0默认的网段都是172.17.0.0/16的网络。如果要实现不同宿主node上pod(这里也可以理解为容器)互相通信,就不能使用默认的docker0提供的网段,我们需要部署一个Fannel的覆盖网络,让每个node节点的docker0网络都处于不同的网段,这样,通过添加一些路由转发策略,就能让集群中各个pod在同一个虚拟的网络中实现通信。
Fannel首先连上etcd,利用etcd来管理可分配的IP地址段资源,同时监控etcd中每个Pod的实际地址,并在内存中建立一个Pod节点路由表,将docker0发给它的数据包封装,利用物理网络的连接将数据投递到目标flannel上,从而完成Pod到Pod之间的通信。
Fannel为了不和其他节点上的Pod IP产生冲突,每次都会在etcd中获取IP,Flannel默认使用UDP作为底层传输协议。
Kubernetes中如果要实现Network Policy,仅仅使用Flannel网络是无法实现的,其本身只是解决了Pod互联的问题,如果需要Network Policy功能,需要使用如Calico、Romana、Weave Net和trireme等支持Network Policy的网络插件。这里将介绍常用的Calico的原理。
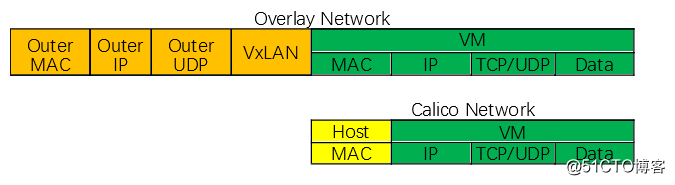
Calico是一个基于BGP的纯三层的网络解决方案。Calico在每个节点利用Linux Kernel实现了一个高效的vRouter来负责数据的转发。 每个vRouter通过BGP1协议把在本节点上运行的容器的路由信息向整个Calico网络广播,并自动设置到其它节点的路由转发规则。Calico保证所有所有容器之间的数据流量都是通过IP路由的方式完成互联。Calico节点组网可以直接利用数据中心的网络结构(L2和L3),不需要额外的NAT、隧道或者Overlay Network,所以就不会有额外的封包和解包过程,能够节省CPU的运算,提升网络效率,相比而言Calico网络比Flannel性能更高。
Overlay网络和Calico网络数据包结构对比(简图):
特性:
使用Calico的简单策略语言,您可以实现对容器,虚拟机工作负载和裸机主机端点之间通信的细粒度控制。
Calico v3.0与Kubernetes和OpenShif集成的环境已经过大规模的生产验证。
Calico架构图:
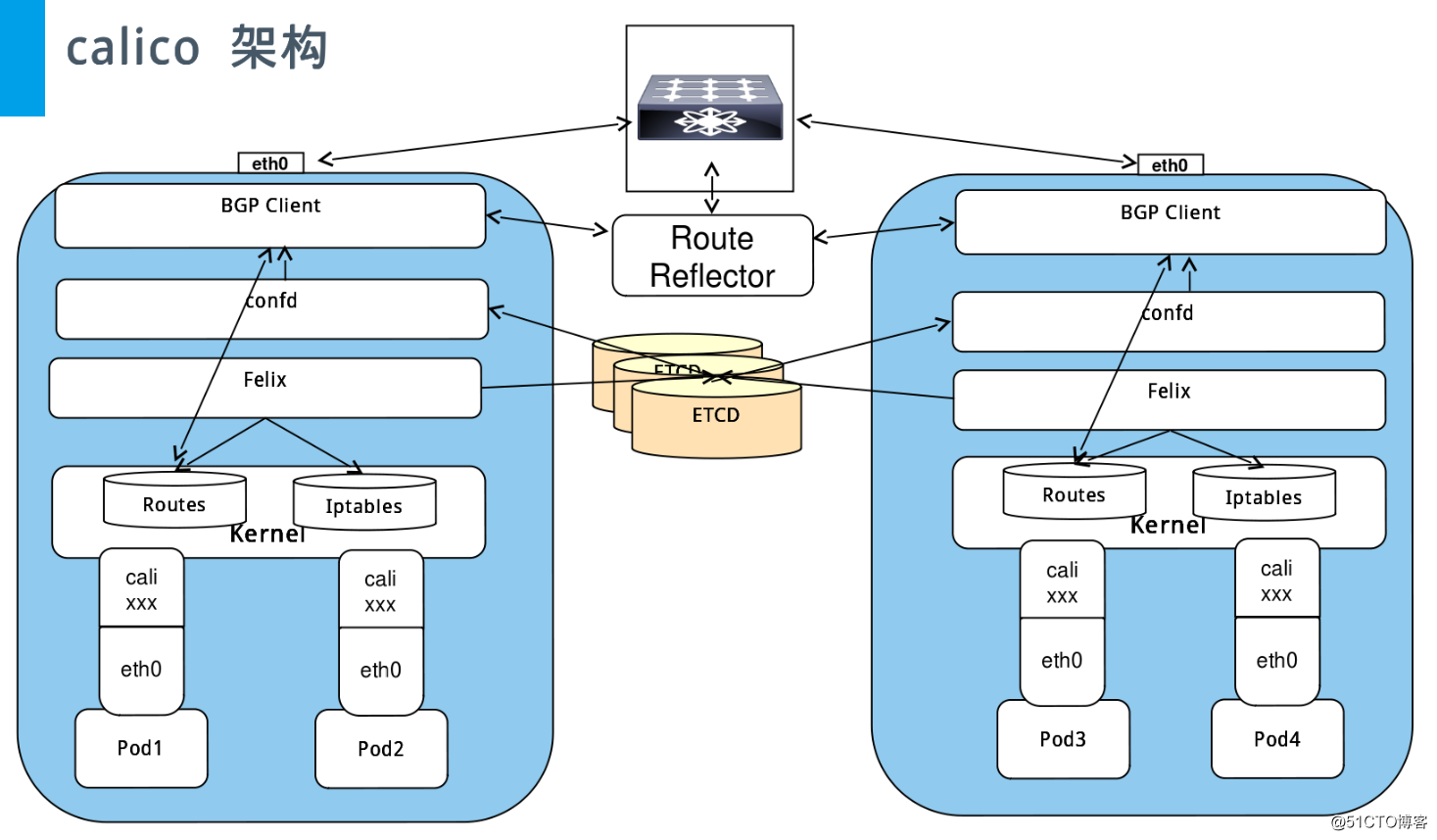
Calico组件:
Felix是一个守护进程,它在每个提供endpoint的计算机上运行:在大多数情况下,这意味着在托管容器或VM的宿主节点上运行。 它负责设置路由和ACL以及主机上所需的任何其他任务,以便为该主机上的端点提供所需的连接。
Felix一般负责以下任务:
==接口管理==:
Felix将有关接口的一些信息编程到内核中,以使内核能够正确处理该端点发出的流量。 特别是,它将确保主机使用主机的MAC响应来自每个工作负载的ARP请求,并将为其管理的接口启用IP转发。它还监视出现和消失的接口,以便确保在适当的时间应用这些接口的编程。
==路由规划==:
Felix负责将到其主机端点的路由编程到Linux内核FIB(转发信息库)中。 这确保了发往那些到达主机的端点的数据包被相应地转发。
==ACL规划==:
Felix还负责将ACL编程到Linux内核中。 这些ACL用于确保只能在端点之间发送有效流量,并确保端点无法绕过Calico的安全措施。
与Felix 没有单独的Orchestrator插件相反,每个主要的云编排平台(如Kubernetes)都有单独的插件。这些插件时将Calico更紧密的绑定到协调器中,允许用户管理Calico网络,就像他们管理协调器中的网络工具一样。Kubernetes中可以直接使用CNI插件来代替此功能。
一个好的Orchestrator插件示例是Calico Neutron ML2机制驱动程序。 该组件与Neutron的ML2插件集成,允许用户通过Neutron API调用来配置Calico网络。 这提供了与Neutron的无缝集成。主要有以下功能:
==API转换==:
协调器将不可避免地拥有自己的一套用于管理网络的API。 Orchestrator插件的主要工作是将这些API转换为Calico的数据模型,然后将其存储在Calico的数据存储区中。
这种转换中的一些将非常简单,其他比特可能更复杂,以便将单个复杂操作(例如,实时迁移)呈现为Calico网络的其余部分期望的一系列更简单的操作。
Calico使用etcd提供组件之间的通信,并作为一致的数据存储,确保Calico始终可以构建准确的网络。
根据orchestrator插件,etcd可以是主数据存储,也可以是单独数据存储的轻量级副本镜像.主要功能:
==数据存储==:
etcd以分布式,容错的方式存储Calico网络的数据(这里指使用至少三个etcd节点的etcd集群)。 这确保Calico网络始终处于已知良好状态。
Calico数据的这种分布式存储还提高了Calico组件从数据库读取的能力,使它们可以在集群周围分发读取。
Calico在每个也承载Felix的节点上部署BGP客户端。 BGP客户端的作用是读取Felix程序进入内核并将其分布在数据中心周围的路由状态。
在Calico中,这个BGP组件最常见的是BIRD,但是任何BGP客户端(例如可以从内核中提取路由并分发它们的GoBGP)都适用于此角色。
对于大型集群的部署,简单的BGP可能由于瓶颈而成为限制因素,因为它要求每个BGP客户端连接到网状拓扑中的每个其他BGP客户端。 这使得客户端的连接将以N ^ 2量级增长,当节点越来越多将变得难以维护。因此,在大型集群的部署中,Calico将部署BGP Route Reflector。 通常在Internet中使用的此组件充当BGP客户端连接的中心点,从而防止它们需要与群集中的每个BGP客户端进行通信。为了实现冗余,可以无缝部署多个BGP Route Reflector。
BGP Route Reflector纯粹参与网络控制:没有端点数据通过它们。在Calico中,此BGP组件也是最常见的BIRD,配置为BGP Route Reflector而不是标准BGP客户端。
标签:names coreos 断开连接 交换 删除 抽象 比特 eth 启用
原文地址:http://blog.51cto.com/tryingstuff/2165805