标签:src port bytes repr 实例 encode class 一句话 alt
py2编码
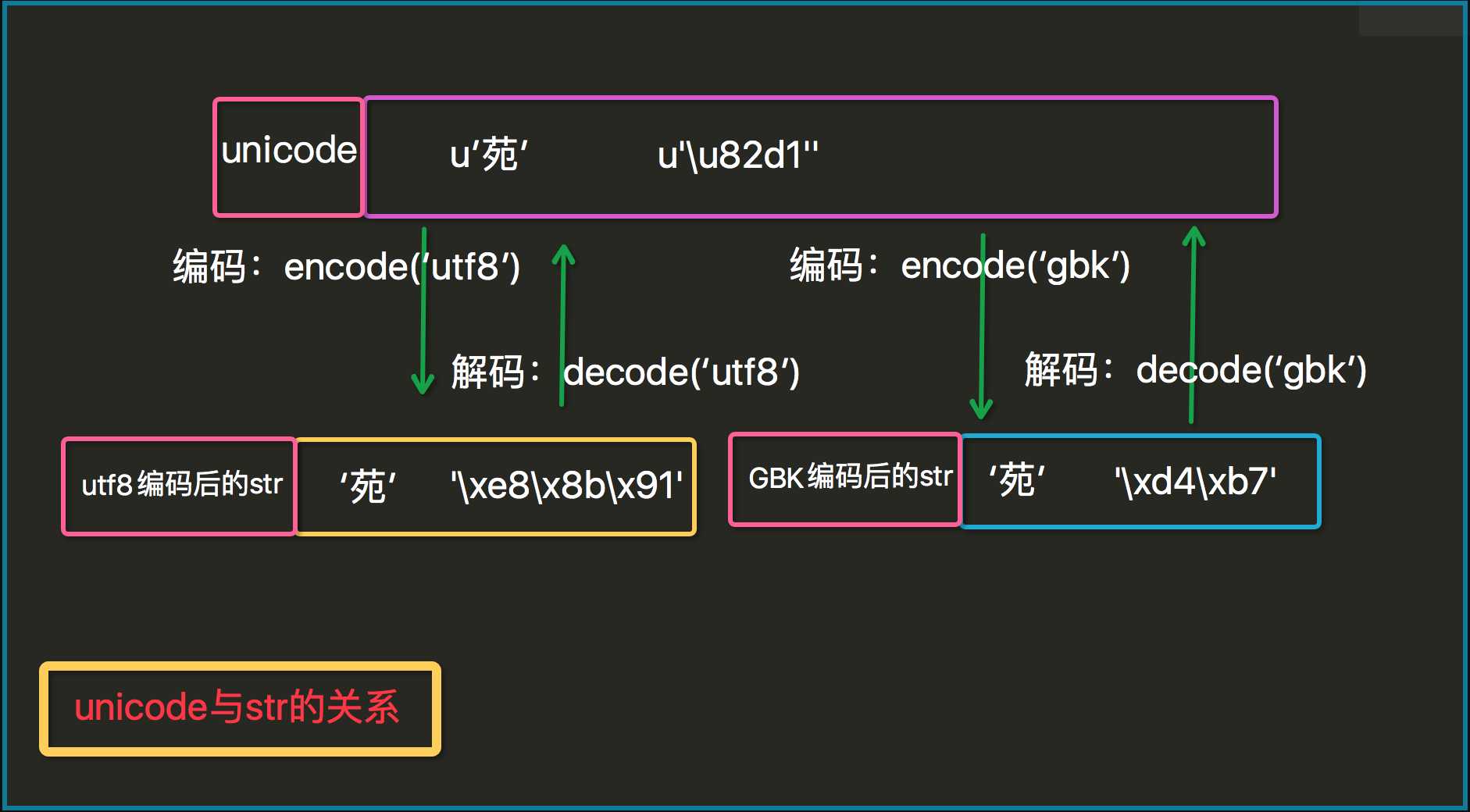
py2中的数据类型:str和unicode
str存储的是对应的字节,一个汉字占3个字节
# -*- coding: UTF-8 -*- s="余hello" print len(s) #8 print(repr(s)) #‘\xe4\xbd\x99hello‘ print(type(s)) #<type ‘str‘>
unicode存储是对应的unicode
# -*- coding: UTF-8 -*- s=u"余hello" print len(s) #6 print(repr(s)) #u‘\u4f59hello‘ print(type(s)) #<type ‘unicode‘>
py2特点:
print "余"+u"最帅" 报错
print "hello"+u"yu" 正确
py2编码的最大特点是Python 2 将会自动的将bytes数据解码成 unicode 字符串,Python 2 悄悄掩盖掉了 byte 到 unicode 的转换,让程序在处理 ASCII 的时候更加简单。你复出的代价就是在处理非 ASCII 的时候将会失败。
再来看看encode()和decode()两个basestring的实例方法,理解了str和unicode的区别后,这两个方法就不会再混淆了:
py3编码
py3里是str和bytes数据类型
str对应的是unicode,bytes对应的是bytes
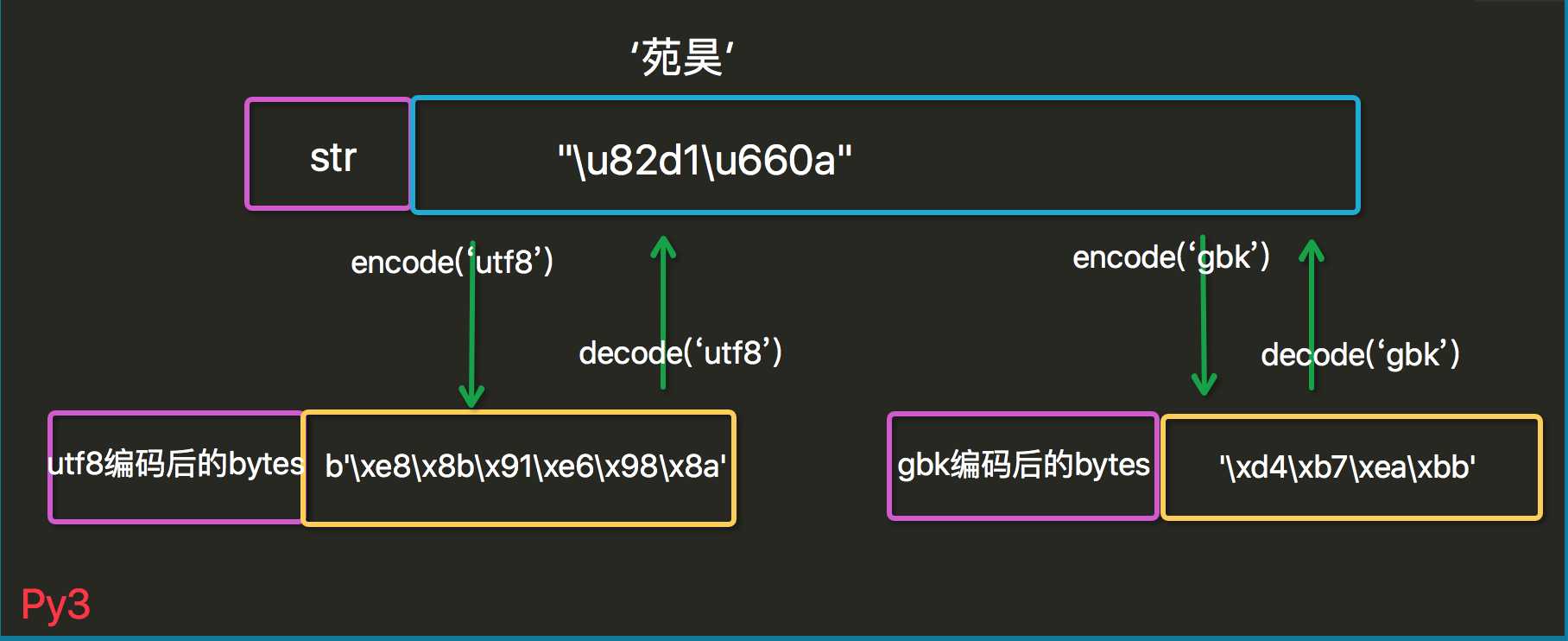
import json s=‘苑昊‘ print(json.dumps(s)) #"\u82d1\u660a" b1=s.encode(‘utf8‘) print(b1,type(b1)) #b‘\xe8\x8b\x91\xe6\x98\x8a‘ <class ‘bytes‘> print(b1.decode(‘utf8‘))#苑昊 # print(b1.decode(‘gbk‘))# 鑻戞槉 b2=s.encode(‘gbk‘) print(b2,type(b2)) #‘\xd4\xb7\xea\xbb‘ <class ‘bytes‘> print(b2.decode(‘gbk‘)) #苑昊
默认编码
py2默认的ASCII码,在程序开头需要加上#-*- coding: UTF-8 -*-,如果不加上这么一句话,程序一旦出现中文就会报错,对于中文这些特殊字符无法编码。
标签:src port bytes repr 实例 encode class 一句话 alt
原文地址:https://www.cnblogs.com/yhengwei2018/p/9557616.html