标签:image 字符串转换 close 建议 ima windows enc 报错 write
python2最大的坑在于中文编码问题,遇到中文报错首先加u,再各种encode、decode。
当list、tuple、dict里面有中文时,打印出来的是Unicode编码,这个是无解的。
对中文编码纠结的建议尽快换python3吧,python2且用且珍惜!
1.open打开csv文件,用writer写入带有中文的数据时
# coding:utf-8
import csv
f = open("xieru.csv", ‘wb‘)
writer = csv.writer(f)
# 需要写入的信息
data = ["客户名称", "行业类型", "客户联系人", "职位", "联系方式", "邮箱","地址"]
writer.writerow(data) # 写入单行
# writer.writerows(datas) # 写入多行
f.close()2.打开csv文件,发现写入的中文乱码了
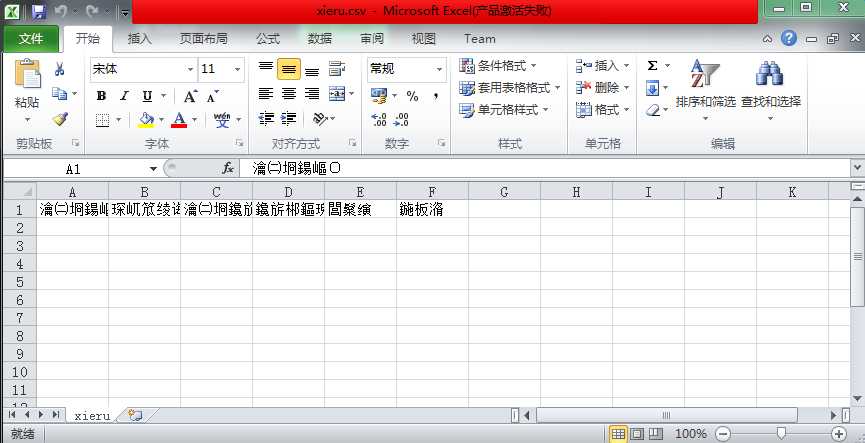
1.中文乱码问题一直是python2挥之不去的痛,这里先弄清楚乱码原因:
所以就导致了乱码问题
2.先把python里面的中文字符串decode成utf-8,再encode为gbk编码
data.decode(‘utf-8‘).encode(‘gbk‘)
3.如果是读取csv文件的话,就反过来:
data.decode(‘gbk‘).encode(‘utf-8‘)
1.方案一:对字符串转换编码(这个太麻烦了,不推荐)
# coding:utf-8
import csv
f = open("xieru1.csv", ‘wb‘)
writer = csv.writer(f)
# 需要写入的信息
data = ["客户名称", "行业类型", "客户联系人", "职位", "联系方式", "邮箱","地址"]
a = []
for i in data:
a.append(i.decode("utf-8").encode("gbk"))
writer.writerow(a) # 写入单行
# writer.writerows(datas) # 写入多行
f.close()2.方法二:用codecs提供的open方法来指定打开的文件的语言编码,它会在读取的时候自动转换为内部unicode (推荐)
# coding:utf-8
import csv, codecs
import sys
reload(sys)
sys.setdefaultencoding(‘utf8‘)
f = codecs.open("xx.csv", ‘wb‘, "gbk")
writer = csv.writer(f)
writer.writerow(["客户名称", "行业类型", "客户联系人", "职位", "联系方式", "邮箱","地址"])
# 多组数据存放list列表里面
datas = [
["客户名称", "行业类型", "客户联系人", "职位", "联系方式", "邮箱","地址"],
["客户名称", "行业类型", "客户联系人", "职位", "联系方式", "邮箱","地址"],
["客户名称", "行业类型", "客户联系人", "职位", "联系方式", "邮箱","地址"],
]
writer.writerows(datas)
f.close()
从悠悠处搬过来的。标签:image 字符串转换 close 建议 ima windows enc 报错 write
原文地址:https://www.cnblogs.com/phyger/p/9561283.html