标签:自己 教学 item latest err 模板 art mic requests
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。(引用自:百度百科)
scrapy官方网站:https://scrapy.org/
scrapy官方文档:https://doc.scrapy.org/en/latest/
首先我们安装scrapy,使用如下命令
pip install scrapy此时很多人应该都会遇到如下问题
error: Microsoft Visual C++ 10.0 is required.
Get it with "Microsoft Windows SDK 7.1": www.microsoft.com/download/details.aspx?id=8279这是因为scrapy中使用了许多C++的内容,所以在安装时需要首先有C++ 10.0环境。最直接的解决办法就是下载并安装Microsoft Visual C++ 10.0。但为此下一个这么大的环境,配置又是蛋疼的巨硬风,实在令人畏惧。
所以笔者建议采用第二种方式,我们仔细观察到pip报错前正在运行
Running setup.py clean for Twisted
Failed to build Twisted也就是说是安装Twisted模块时出错了,那么我们可以选择手动下载Twisted模块并安装。python的各种库有很多下载地,不少人可能会下载到 Twisted-xx.x.x.tar.bz2 ,解压后进行安装,发现会出现同样的错误。此时我们仔细观察之前安装scrapy时的信息,就会发现,pip指令自动安装时其实也是采用的下载 bz2 文件,解压,运行解压出的setup.py文件,所以这与我们上述的手动安装过程并没有任何区别。
笔者推荐一个网站https://www.lfd.uci.edu/~gohlke/pythonlibs,此网站中包含几乎所有常用的python库。例如我们此次需要下载Twisted库,那么我们在网页中搜索Twisted,然后下载自己对应位数和python版本的Twisted库。然后在Twisted下载位置运行cmd,执行如下命令(记得替换为自己下载的文件名)
pip install Twisted-xx.x.x-cpxx-cpxxm-win_amd64.whl然后我们只需要等待其运行完成安装,至此我们安装好了scrapy必须的Twisted库,然后我们重新执行
pip install scrapy安装成功!
在安装过程中,我们可以看到它为我们下载了许多辅助库,这使得scrapy成为了一个完整的成体系的爬虫框架,这些框架极大地简化了我们的编程难度,降低了学习成本。
scrapy是基于requests库搭建的,所以我们还需要执行以下命令
pip install requests至此,我们已经完成了scrapy爬虫框架的安装。
scrapy是一个系统的框架,使用前的准备工作与其他一些爬虫库相比略显复杂,但这有限的几步,能够极大地降低我们后续编程的难度。
由于我们现在对scrapy框架还不熟悉,所以我们使用scrapy自带的命令来生成scrapy的模板。此次我们以爬取jobbole为例。
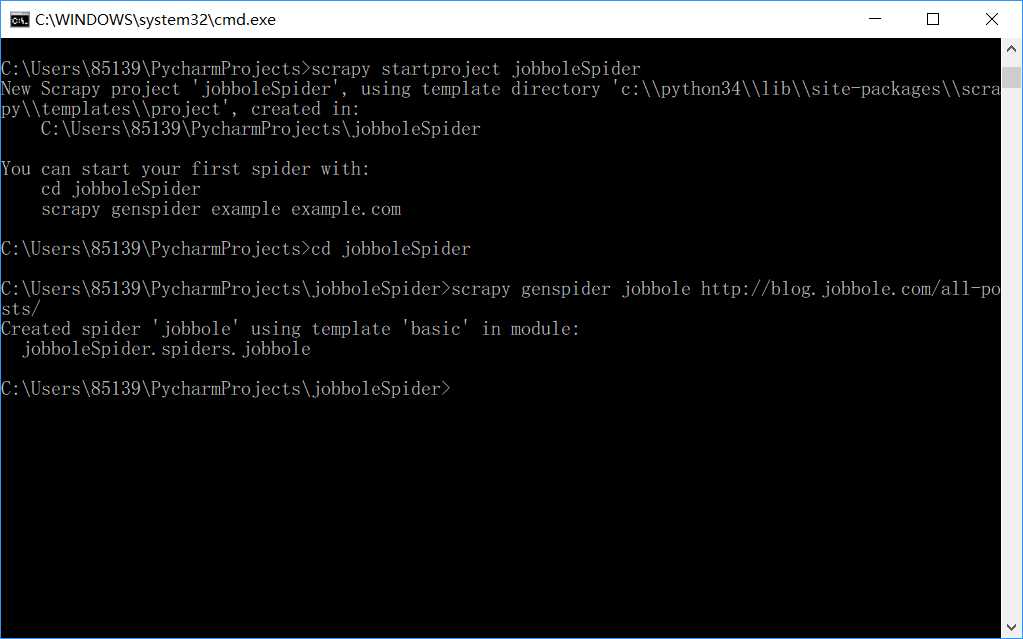
如上图,首先,我们使用如下命令
scrapy startproject jobboleSpider这样我们就能在当前路径下创建了一个scrapy爬虫项目,但这个项目此时还不完整,所以我们根据它的提示使用以下命令创建一个scrapy自带的模板
cd jobboleSpider
scrapy genspider jobbole http://blog.jobbole.com/all-posts/根据提示信息,我们知道了我们使用了scrapy的"basic"模板成功创建了一个scrapy项目并构建了基本的结构。那么接下来我们打开IDE来了解一下我们创建的模板。
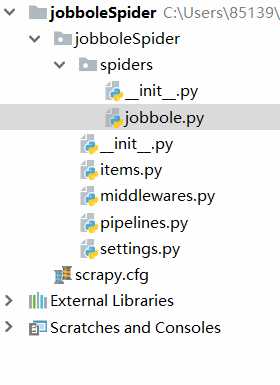
其中scrapy.cfg使我们的全局配置文件,包含我们的设置文件路径,项目名称等。
jobbole.py是我们以后实现爬虫逻辑的主要文件。
items.py是我们的定义数据储存结构的文件。
middlewares.py包含了大量中间件,例如下载中间件,重定向中间件,是scrapy引擎与其他部分代码之间发送信息的重要通道。
pipelines.py正如其名,是一个管道,主要用于将我们获得的数据储存到数据库中。
setteings.py则由大量关于scrapy的设置,例如是否遵循robot协议等。
至此我们已经实现了scrapy的安装和基本框架的实现,但还没有进行具体的编程,接下来笔者将会带着大家首先实现对jobbole“最新文章”的所有文章的爬取,以初步体验到scrapy爬虫的乐趣。然后逐步深入到模拟登陆,突破反爬虫限制等。
我会尽量详细的说明我的每一步操作,以实现一个“小白教程”。后面的教程中我们会使用到xpath和正则表达式,限于篇幅,笔者对这两个知识点只会进行一些基本的教学,如果大家想要熟练运用的话,最好能够查阅其他一些资料进行更深入的学习。
python爬虫随笔-scrapy框架(1)——scrapy框架的安装和结构介绍
标签:自己 教学 item latest err 模板 art mic requests
原文地址:https://www.cnblogs.com/AlbertShen99/p/9563434.html