标签:.com 实现 www. spark 解决 ISE 通过 技术分享 enc
datafrme提供了强大的JOIN操作,但是在操作的时候,经常发现会碰到重复列的问题。在你不注意的时候,去用相关列做其他操作的时候,就会出现问题!
假如这两个字段同时存在,那么就会报错,如下:org.apache.spark.sql.AnalysisException: Reference ‘key2‘ is ambiguous
1.创建两个df演示实例
val df = sc.parallelize(Array(
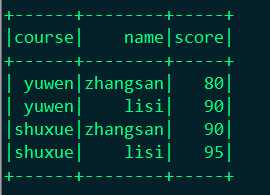
("yuwen", "zhangsan", 80), ("yuwen", "lisi", 90), ("shuxue", "zhangsan", 90), ("shuxue", "lisi", 95)
)).toDF("course", "name", "score")
显示:df.show()
val df2 = sc.parallelize(Array(
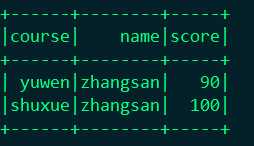
("yuwen", "zhangsan", 90), ("shuxue", "zhangsan", 100)
)).toDF("course", "name", "score")
显示:df2.show
关联查询:
val joined = df.join(df2, df("cource") === df2("cource") && df("name") === df2("name"), "left_outer")
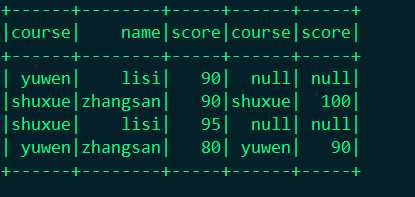
结果展示:
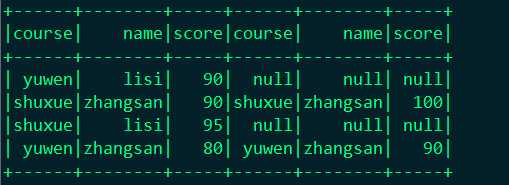
这时候问题出现了这个地方出现了三个两两相同的字段,当你在次操作这个字段的时候就出问题了。

1.你可以使用的时候指定你要用哪个df里面的字段
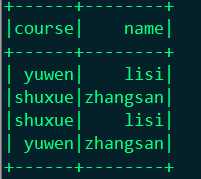
joined.select(df("course"),df("name")).show
结果:
2.你可以删除多余的列,在实际情况中你不可能将两张完全一样的表进行关联,一般就几个字段的名字相同,这样你可以删除你不需要的字段
joined.drop(df2("name"))
结果:
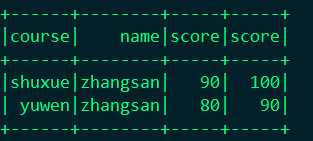
3.就是通过修改JOIN的表达式,完全可以避免这个问题。主要是通过Seq这个对象来实现
df.join(df2, Seq("course", "name")).show()
结果:
转自:https://www.cnblogs.com/chushiyaoyue/p/6927488.html
spark关于join后有重复列的问题(org.apache.spark.sql.AnalysisException: Reference '*' is ambiguous)
标签:.com 实现 www. spark 解决 ISE 通过 技术分享 enc
原文地址:https://www.cnblogs.com/lyy-blog/p/9567101.html