标签:磁盘io 暂停 对象 red iostat sso eth try lap
背景
“线下没问题的”、 “代码不可能有问题 是系统原因”、“能在线上远程debug么”
线上问题不同于开发期间的bug,与运行时环境、压力、并发情况、具体的业务相关。对于线上的问题利用线上环境可用的工具,收集必要信息 对定位问题十分重要。
对于导致问题的bug、资源瓶颈很难直观取得数据,需要根据资源使用数据、日志等信息推测问题根源。并且疑难问题的定位通常需要使用不同的方法追根溯源。
这篇wiki我对自己使用过的工具做了整理,并分享一些案例。
1. 常见问题
1.1 可用性
这里举几种常见导致服务可用性的情况:
a) 502 Bad Gateway
对应用系统特别是基于http的应用最严重的莫过于"502 Bad Gateway",这表示后端服务已经完全不可用,可能原因
资源不足1:垃圾回收导致,在CMS在应用内存泄漏或内存不足情况下会导致严重的应用暂停。
资源不足2:服务器线程数不足,常见web server如tomcat jetty都是有最大工作线程配置的
资源不足3:数据库资源不足,数据库通常使用连接池配置,maxConnection配置低加上过多慢查询会block住web server的工作线程
资源不足4:IO资源瓶颈,线上环境IO是共享的,尤其对于混布环境(CRM还好 没有这种情况,但是有很多agent),我们常用的log4j日志工具对于每个记录的日志文件也是一种独占资源,线程先要获得锁才能向日志记录数据。
... ...
各种OOM
b) Socket异常
常见Connection reset by peer,Broken Pipe,EOFException
网络问题:在跨运营商、机房访问情况下可能遇到
程序bug:socket异常关闭
1.2 平均响应时间
系统发生问题时最直观的表象,这个参数在情况恶化传染其他服务 导致整个系统不可用前,可以提前预警,可能原因:
资源竞争1:CPU
资源竞争2:IO
资源竞争3:network IO
资源竞争4:数据库
资源竞争5:solr、medis
下游接口:异常导致响应延时
1.3 机器报警
与应用服务不可用相比,这类错误不会直接导致服务不可用,而且如果存在混不,机器部署多个服务可能相互干扰:
CPU
磁盘
fd
IO(网络 磁盘)
1.4 小结
写了半天,很多情况是重复提到,通常线上问题的原因不外乎系统资源、应用程序,掌握监控查看这些资源、数据的工具就更容易定位线上的问题。
2常用工具
2.1 Linux工具
a) sysstat:
iostat:查看读写压力
sar:查看CPU 网络IO IO,开启参数可以查看历史数据
b) top
关注load、cpu、mem、swap
可按照线程查看资源信息(版本大于3.2.7)
c) vmstat
d) tcpdump
定位网络问题神器,可以看到TCPIP报文的细节,需要同时熟悉TCPIP协议,可以和wireshark结合使用。
常见场景分析网络延迟、网络丢包,复杂环境的网络问题分析。
2.2 java工具
a) jstat
b) jmap
c) jstack or kill -3
查看死锁、线程等待。
线程状态:
Running
TIMED_WAITING(on object monitor)
TIMED_WAITING(sleeping)
TIMED_WAITING(parking)
WAINTING(on object monitor)
d) jhat jconsole
jhat很难用 jconsole通过jmx取信息对性能有影响
e) gc日志
-XX:+UseParallelOld
-XX:+ConcurrentMultiSweep
2.3 第三方工具
a) mat
对象详细
inboud/outbound
thread overview
配置项
./MemoryAnalyzer -keep_unreachable_objects heap_file
3. 案例分析
3.1 cpu高
现象:CPU报警
定位问题:
查看CPU占用高的线程
thread dump
查找线程执行的代码
3.2 io高
现象:磁盘IO报警
环境:需要安装sysstat工具
定位问题:
a) 查看CPU占用高的线程
b) 其他同4.1
3.3 资源
a) 数据库
b) log
c) web server
有两个非常重要的系统参数:
maxThread: 工作线程数
backlog:TCP连接缓存数,Jetty(ServerConnector.acceptQueueSize) Tomcat(Connector.acceptCount),高并发下设置过小会有502
3.4 gc
a) CMS fail
promotion failed
concurrent fail
b) 连续Full GC
应用存在内存泄漏,垃圾收集会占用系统大量cpu时间,极端情况下可能发生90%以上时间在做GC的情况。
在系统使用http访问check alive或者使用了Zookeeper这种通过心跳保证存活性的应用中,会可用性异常或者被zk的master剔除。
4. 注意
保留现场:threaddump top heapdump
注意日志记录:文件 数据库
5.从运维角度谈谈故障定位
面试时,经常会被问到:在线业务出现故障,该如何定位?
一般刚毕业不久的会回答:我们有监控;看日志等之类的答案。
工作几年的人会回答:从网络,机器,资源等方面排查有没有问题,如果没有问题,再看看日志,找开发核对。
也有人回答这个是开发的问题,我们运维还没有精确到业务层面。
故障定位,这个话题可能很大,不同角色认识是不一样的。对于开发,故障定位往往会根据问题现象,从代码角度去分析,尝试从代码或架构方面进行解决。对于运维而言,故障定位,一般理解为:在线业务的核心功能受到影响,应该如何快速定位到原因。
本文要讨论的范围,也仅限于运维角度进行在线问题故障定位。
运维人员进行故障定位时,遇到主要问题:
1)业务掌握深入程度有限。不像某个应用的开发那样,能很清楚一个小问题的处理逻辑。
2)要对在线业务的稳定性负责。
3)造成故障的原因很多。除了代码bug可能导致问题外,IDC,机器,流量波动等外在条件都会有影响。
4)不同运维人员对于业务理解或运维能力不同。不同的业务运维人员由于经验等不同,遇到故障时的心态、决策等区别很大。
“核心功能告警,执行预案”是运维处理在线故障的思路。但是,当预案执行后,故障仍然存在,该如何做呢?
这时候,就要快速、准确定位出故障原因,至少要知道造成这次故障的一个范围是什么,以便采取相应措施。
网络方面
网络无疑是造成服务故障的第一杀手。
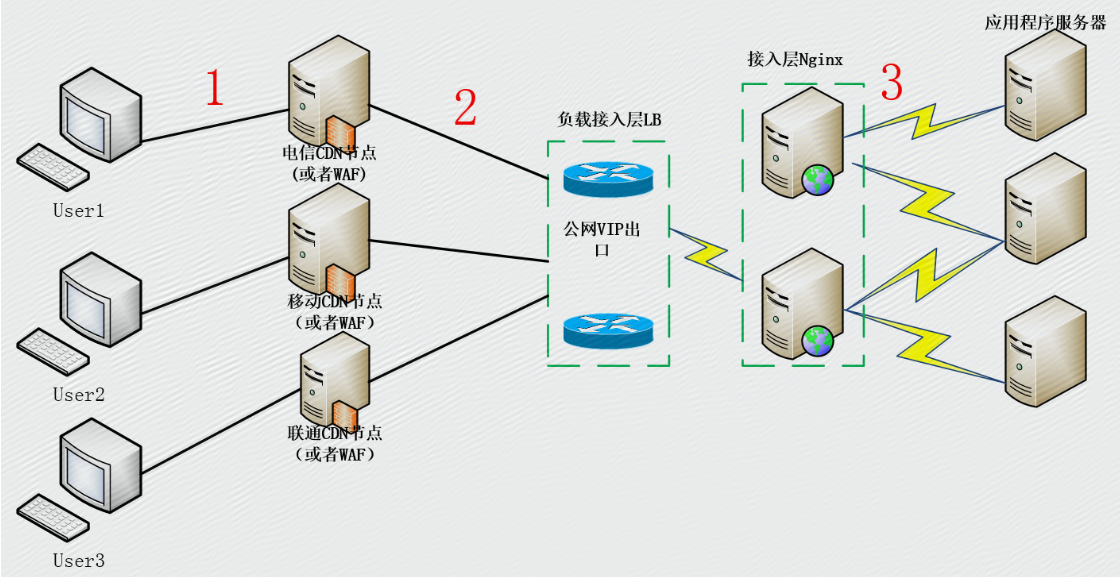
用户->CDN->源站IDC->业务接入层->后端服务
用户->源站IDC->业务接入层->后端服务
服务健康
资源使用
核心依赖
上线变更
容量方面
文章参考资料来源:
https://blog.csdn.net/sunjiangangok/article/details/79266238
http://blog.51cto.com/yingtju/1908197
标签:磁盘io 暂停 对象 red iostat sso eth try lap
原文地址:https://www.cnblogs.com/pony1223/p/9567518.html