标签:mic user ext 地址 soup ima else color direct
最近看了个爬虫的教程,想着自己也常在斗鱼看直播,不如就拿它来练练手。于是就写了个爬取斗鱼所有在线主播的信息,分别为类别、主播ID、房间标题、人气值、房间地址。
需要用到的工具python3下的bs4,requests,pymongo。我用的IDE是pycharm,感觉这个软件实在太强大,有点离开它什么都不会的感觉,数据库Mongodb,结合pycharm工具可以直接在右侧显示数据。
#-*- coding:utf-8 -*- from bs4 import BeautifulSoup import requests, time ,datetime import json import pymongo class douyu_host_info(): def __init__(self): self.date_time = datetime.datetime.now().strftime(‘%Y-%m-%d_%H-%M‘) self.host_url = ‘https://www.douyu.com‘ self.list_data = [] self.urls_list = [] self.headers = { ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36‘, } def get_url(self): #获取所有类别的网站地址 urls = ‘https://www.douyu.com/directory‘ data = requests.get(urls) Soup = BeautifulSoup(data.text, ‘lxml‘) list = Soup.select(‘.r-cont.column-cont dl dd ul li a‘) for i in list: urls = i.get(‘href‘) self.urls_list.append(urls) print (self.urls_list) return self.urls_list def get_info(self, url): #查询所需信息并写调用写入数据库及本地磁盘的函数 time.sleep(1) #避免服务器承压过大,每个网站爬取设置1s间隔 url = self.host_url + url print (‘Now start open {}‘.format(url)) get_data = requests.get(url, headers=self.headers) Soup = BeautifulSoup(get_data.text, ‘lxml‘) names = Soup.select(‘.ellipsis.fl‘) nums = Soup.select(‘.dy-num.fr‘) titles = Soup.select(‘.mes h3‘) hrefs = Soup.select(‘#live-list-contentbox li a‘) #网站中带directory时只是一个分类页面没有主播信息 if ‘directory‘ in url: pass #异常处理,有少数类别的HTML元素有差别,这里就舍弃了 try: category = Soup.select(‘.listcustomize-topcon-msg h1‘)[0].get_text() except: category = ‘秩名类别‘ for name, num, href, title in zip(names, nums, hrefs, titles): data = { ‘类别‘: category, ‘主播‘: name.get_text(), ‘标题‘: title.get_text().split(‘\n‘)[-1].strip(), ‘链接‘: ‘https://www.douyu.com‘ + href.get(‘href‘), #把人气指数转换成以万为单位的浮点型,方便后面计算查找 ‘人气指数‘: float(num.get_text()[:-1]) if ‘万‘in num.get_text() else float(num.get_text())/10000, } if data[‘人气指数‘] > 2: print (data) self.w_to_local(data) self.w_to_db(data) def open_data(self, date_time): #需要用到时可以输入指定时间点读取本地保存的数据 with open(‘D:\douyu_host{}.csv‘.format(date_time), ‘r‘) as r_data: r_data = json.load(r_data) for i in r_data: print (i) def w_to_local(self,data): #在将数据写入数据库的同时在本地磁盘保存一份 with open(‘D:\douyu_host{}.csv‘.format(self.date_time), ‘a‘) as w_data: json.dump(data, w_data) def w_to_db(self, data): #将数据写入一个以时间为后缀的数据库表, data需要是字典格式 client = pymongo.MongoClient(‘localhost‘, 27017) walden = client[‘walden_{}‘.format(self.date_time)] sheet_tab = walden[‘sheet_tab‘] if data is not None: sheet_tab.insert_one(data) def check_from_db(self, date_time): #输入时间从数据库查询相关人气信息 client = pymongo.MongoClient(‘localhost‘, 27017) walden = client[‘walden_{}‘.format(date_time)] sheet_tab = walden[‘sheet_tab‘] for data in sheet_tab.find({‘人气指数‘:{‘$gte‘:40}}): print (data)
本来没想用类来写的,后来发现很多数据传来传去很乱,而且重要的数据存储时间不好统一,于是就写在一个类里了。里面很关键的一点,用select模块选取元素路径,如下图。
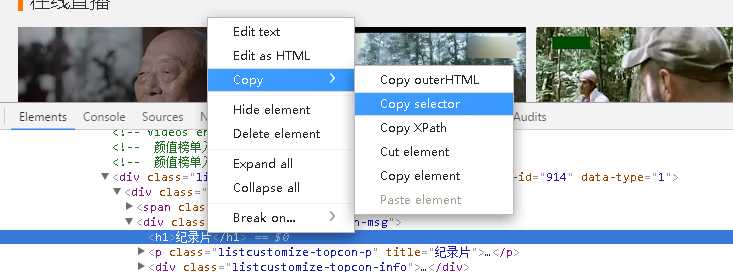
复制出来的是很长的一段路径,可以慢慢观察选取主要的关键字段就好了。
然后新建一个py文件用来调用之前写好的类,实例化后,用pool多线程运行,结果就出来了。
#-*- coding:utf-8 -*- import time from multiprocessing import Pool from test0822 import douyu_host_info douyu = douyu_host_info() if __name__ == ‘__main__‘: #多线程爬取数据 urls_list = douyu.get_url() pool = Pool() pool.map(douyu.get_info, urls_list)
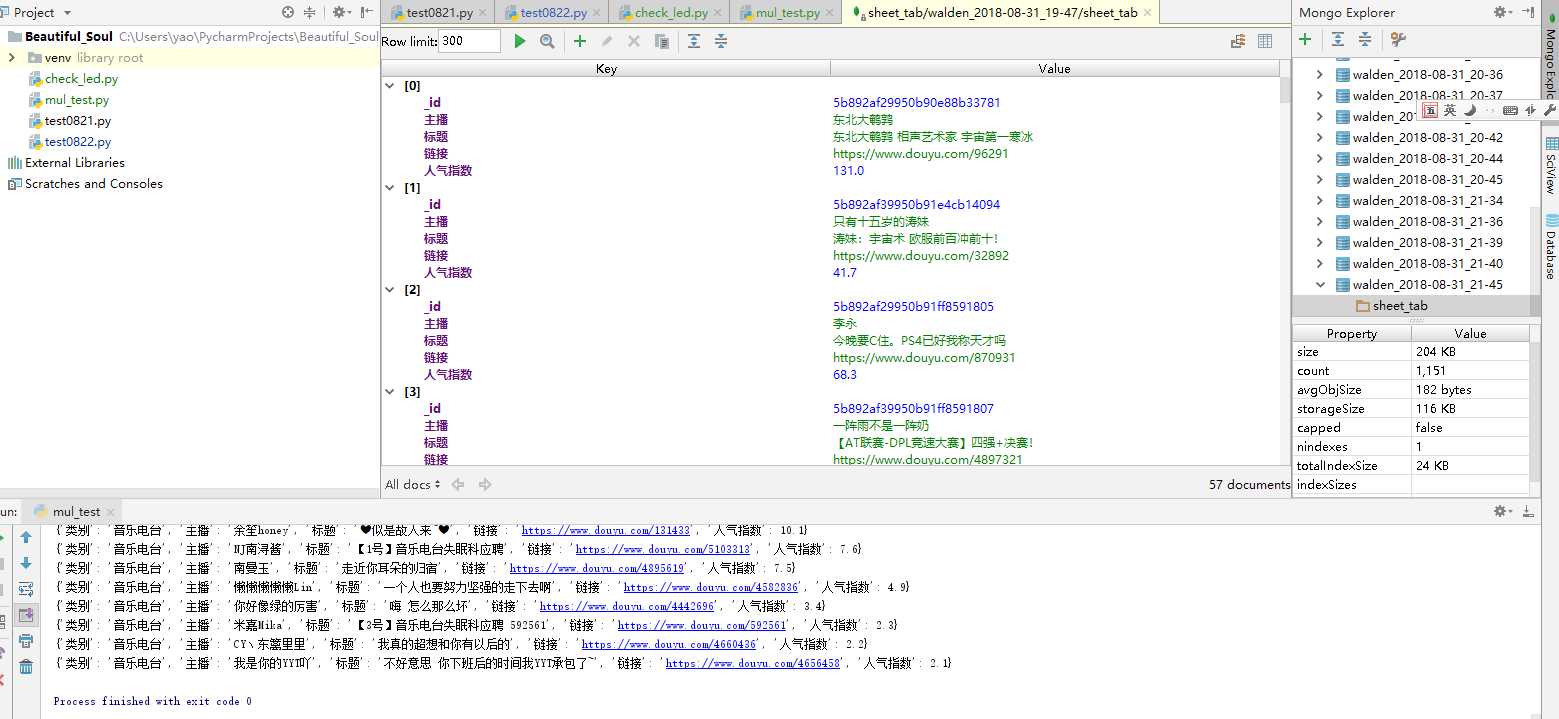
来个运行后的全景图。
标签:mic user ext 地址 soup ima else color direct
原文地址:https://www.cnblogs.com/lkd8477604/p/9568521.html