MySQL自增列的步长问题
-
唯一索引和联合唯一
-
外键的变种
-
SQL数据行的增删改查
-
视图
-
触发器
-
函数
-
存储过程
-
事务
-
游标
-
动态执行SQL(防SQL注入)
1.MySQL自增列的步长问题:
1.基于会话级别(单次登陆状态下):
show session variables like ‘auto_inc%‘; #查看自增长的默认步数,一般为1
set session auto_increment_increment=2; #设置自增长会话步长为2
set session auto_increment_offset=10; #设置默认自增长初始值
2.基于全局级别(所有用户生效):
show global variables like ‘auto_inc%‘; #查看全局变量中的自增长的默认步长
set global auto_increment_increment=2; #设置全局会话步长
set global auto_increment_offset=10; #设置全局自增长初始值
2.唯一索引和联合唯一:
create table t1(
id int,
num int,
name char
unique uql (num) #唯一索引
unique uql (num, name) #联合唯一
);
唯一索引和主键 的共同点:
1.都有加速查找的功能;
2.都是唯一,不能重复
唯一索引和主键的不同点:
主键既不能重复也不能为空;
而唯一索引不能重复,但是可以有值为空,比如联合索引中可以设置一个值为null
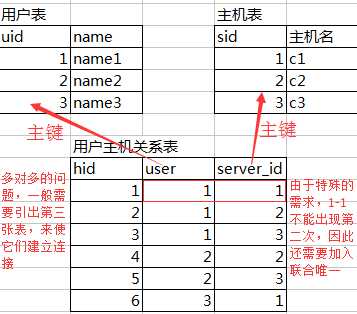
3.外键的变种:
1.一对一:博客用户表
2.一对多:百合网相亲记录表
3.多对多:用户主机关系表
4.SQL数据行的增删改查:
增:
insert into test(name, age) values(‘name‘, 18);
insert into test(name, age) values(‘name1‘, 18),(‘name2‘, 18); #一次性插入多个值
insert into test(name, age) select name,age from test1; #把某张表中的数据插入
删:
delete from test;
delete from test where id>2 and name=‘name1‘;
改:
updata test set name=‘name2‘,age=19 where id>12 and name=‘name1‘;
查:
select * from test;
select id,name from test where id>2;
select name,age,123 from test;
select name as rname from test;
select * from test where id in (1,3,5,7);
select * from test where id in (select id from test1);
select * from test where id between 5 and 9; #闭区间,左右都可以取到
通配符
select * from test where name like ‘name%‘; %匹配无数字符;_匹配一个字符
分页
select * from test limit 10; 取前十条
select * from test limit 0,10; 表示从0开始,取0后面的10条
select * from test limit 10 offset 20; 表示从20开始,取20后的前10条
排序
select * from test order by id desc; id从大到小排列
select * from test order by id asc; id从小到大排列
select * from test order by age desc, id asc; 多个不同排序
select * from test order by desc limit 10; 取后十条
分组(聚合函数:count,max,min,sum,avg求平均值)
select max(id),id from test group by sex; 如果遇到相同的sex,只会取最大id的
select count(id),id from test group by sex; 计数
select count(id) as count,id form test group by sex;
select count(id),id from test group by sex having count(id)>2; 对于聚合函数结果进行二次筛选时,必须使用having
连表操作:
#左右连表 join
select * from test1,test2 where test1.id = test2.part_id;
select * from test1 left join test2 on test1.id = test2.part_id; test1左边会全部显示
select * from test right join test2 on test1.id = test2.part_id; test1右边会全部显示
select * from test innder join test2 on test1.id = test2.part_id; 会把出现null的那一行隐藏
#上下连表 union
select id,name from test1
union #自动去重
select id,name from test2;
select id,name from test1
union all #不去重
select id,name from test2;
转储mysql文件:
mysqldump -uroot test1 > test1.sql -p #数据表结构+数据
mysqldump -uroot -d test1 > test1.sql -p #只有数据表结构
导入mysql文件:
create databases test1;
mysqldump -uroot -d test1 < test1.sql -p;
临时表
select id from (select id from test where num>60) as B;
添加条件
select min(num),min(num)+1,case when num<10 then 0 else min(num) end from score
#创建
create view as view1 select * from test where id>10;
#视图是一个临时表
#视图是虚拟出来的,不是物理表,因此不能插入数据
#修改
alter view 视图名称 as SQL
6.触发器:
#插入前
create trigger t1 BEFORE INSERT on student for EACH ROW
BEGIN
INSERT into teacher(tname) values(NEW.sname);
END
#插入后 after insert
#删除前 before delete
#删除后 after delete
#更新前 before update
#更新后 after update
#由于默认;结束,因此不会执行end,所以要执行触发器之前要先修改终止符
delimiter //
create trigger t1 BEFORE INSERT on student for EACH ROW
BEGIN
INSERT into teacher(tname) values(sname);
END //
delimiter ;
#创建时自动插入:
drop trigger t1; #结束上一个触发器
delimiter //
create trigger t1 BEFORE INSERT on student for EACH ROW
BEGIN
INSERT into teacher(tname) values(NEW.sname);
END //
delimiter ;
insert into student(gender,class_if,sname) values(‘女‘,1,‘abc‘)
#自定义函数(有返回值)
#创建函数
delimiter \\
create function f1(
i1 int,
i2 int)
returns int
BEGIN
declare num int; 声明一个变量类型是整数
set num = i1 + i2;
return(num);
END \\
delimiter ;
#运行函数
select f1(1,100);
1.简单存储过程
delimiter //
create PROCEDURE p1()
BEGIN
select * from student;
insert into teacher(tname) values(‘ct‘);
END
delimiter ;
#调用存储过程
call p1;
cursor.callproc(‘p1‘)
2.传参数(in,out,inout)
delimiter //
create PROCEDURE p2(
in n1 int,
in n2 int
)
BEGIN
select * from student where sid>n1;
END
#调用
call p2(12,2);
cursor.callproc(‘p2‘,(12,2))
delimiter //
create PROCEDURE p2(
in n1 int,
out n2 int #out伪装返回值
)
BEGIN
set n2 = 123123;
select * from student where sid>n1;
END
#调用
set @vi = 0 #创建了一个session级的变量叫做v1,可以在外部接收
call p2(12,@v1)
select @v1; 接收变量
cursor.execute(‘select @_p2_0,@_p2_1‘) #pymysql中接收存储过程变量
存储过程的特性:
a.可传参 (in out inout)
b.pymysql
为什么有结果值又有out伪造的返回值:
out的作用:用于标识存储过程的执行结果,如1为失败,2为成功,3为局部成功
9.事务:
delimiter //
create procedure p4(
out status int
)
BEGIN
1.声明如果出现异常则执行{
set status = 1;
rollback; #回滚
}
开始事务
--a账户减少100
--b账户增加100
commit;
结束
set status = 2;
#如果这里的事务执行顺利,会得到变量等于2,不会执行回滚
END //
delimiter ;
delimiter \\
create PROCESDURE p1(
out p_return_code tinyint
)
BEGIN
declare exit handler for sqlexception #这样代码的意思是如果没有顺利执行,就执行下面的代码
BEGIN
-- ERROR
set p_return_code = 1;
rollback;
END;
START TRANSACTION;
DELETE from tb1;
insert into tb2(name) values(‘seven‘);
COMMIT;
--SUCCESS
set p_return_code = 0;
END\\
delimiter ;
#正确的返回0,错误的返回1
10.游标:
delimiter //
create procedure p6()
begin
declare row_id int; --自定义变量1
declare row_num varchar(50); --自定义变量2
declare done INT DEFAULT FALSE;
declare my_cursor CURSOR FOR select id,num from A;
declare CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
open my_cursor; #打开游标
xxoo: LOOP #开始循环
fetch my_cursor into row_id,row_num; #取一行数据赋值给row_id和row_num
if done then
leave xxoo;
END IF;
insert into teacher(tname) values(ssname);
end loop xxoo; #终止循环
close my cursor; #关闭游标
end //
delimter;
delimiter //
create procefure p7(
in tpl varchar(255),
in arg int
)
begin
1.预检测某个东西,SQL语句合法化
2.SQL = 格式化 tp+arg
3.执行SQL语句
set @x0 = arg; #声明变量
PREPARE(准备) XXX(变量) FROM ‘select * from student where sid > ?‘;
EXECUTE(执行) xxx USING @arg(替换上面的?);
DEALLOCATE prepare prod;(执行已经格式化完成的SQL语句)
end //
delimter;
call p7(‘select * from tb where id > ?‘,9)
delimiter \\
CREATE PROCEDURE p8 (
in nid int
)
BEGIN
set @nid = nid;
PREPARE prod FROM ‘select * from student where sid > ?‘;
EXECUTE prod USING @nid;
DEALLOCATE prepare prod;
END\\
delimiter ;