标签:表单 htm info 项目需求 语法规则 eva -- java爬虫 code
由于项目需求,综合了几种考虑方案,准备使用java 爬虫进行数据的获取,不用自己去费劲的想逻辑的实现
使用java爬虫之前,我们必须要掌握的知识:
1. 对前端HTML的元素有一定的认识
2. 使用httpclient
3. jsoup 工具进行HTML的解析判断
4. 能够使用一款网络抓包工具
抓包工具的使用请参考:https://www.cnblogs.com/miantest/p/7289694.html
jsoup 的api的地址:http://www.open-open.com/jsoup/attributes-text-html.htm -->语法规则只要会HTML元素属性,jquery,javascript 就会玩它
介绍几个常用的吧:
1.将抓取到的html文本转为JSOUP 可操作的Document Document doc=Jsoup.parse(你的html文本);
2.select 元素的使用(有很多哦):注意点是只有属性才会被[]括起来,都可以进行混合使用的如select("div#id")
doc.select("a[target][title]") -------> 匹配 a 标签下的 带有target 和 title 属性的标签
doc.select("div") ------------>标签名查找,匹配所有带div标签的元素
doc.select("[title]") --------->属性查找,匹配属性带有title的元素
doc.select(".classname")-------->class名称查找,匹配class 名称为classname的元素
doc.select("#id")-----------> id查找,匹配id 名为id的元素
doc.select("[title=斗图网? RSS Feed]")-------->利用属性值进行查找,匹配title=斗图网? RSS Feed 的元素
3.获取属性值与文本的方法
element.attr("name") ------->获取元素中的name属性值
element.text()
element.html()----------->获取元素的文本内容
4.也有很多我们javascript操作元素的选择器
.getElementById(); -----id 查
.getElementsByClass(); -----class 查
.getElementsByAttribute();------属性查
.getElementsByAttributeValue(key, value) -------属性值查
..........等等,次数省略一万字
pom依赖导入:
是为了让我们方便快捷的操作HTML中的元素
<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.11.2</version> </dependency>
httpclient :可以让我们便捷的进行post 与get 的请求方式
我们现在进行爬去人人网获取人人网的数据
----1.首先我们先进行人人网的模拟登陆
(1),分析人人网的登录表单,可以看出来,内部有一个唯一ID loginForm ,action 地址,以及post的请求方式,以及我们需要的账号密码框
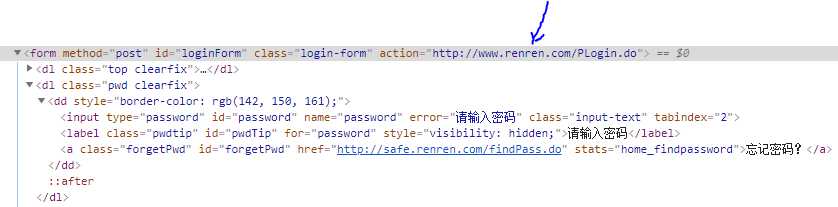
(2).知道这个后,我们就可以通过java 代码的形式进行数据的抓取与提交,实现登录的效果
标签:表单 htm info 项目需求 语法规则 eva -- java爬虫 code
原文地址:https://www.cnblogs.com/iscys/p/9573298.html