标签:假设 比较 short reg 整理 医学图像 技术 and img
写在前面:
一直没有整理的习惯,导致很多东西会有所遗忘,遗漏。借着这个机会,养成一个习惯。
对现有东西做一个整理、记录,对新事物去探索、分享。
因此博客主要内容为我做过的,所学的整理记录以及新的算法、网络框架的学习。基本上是深度学习、机器学习方面的东西。
第一篇首先是深度学习图像分割——U-net网络方面的内容。后续将会尽可能系统的学习深度学习并且记录。
更新频率为每周大于等于一篇。
深度学习的图像分割来源于分类,分割即为对像素所属区域的一个分类。
有别于机器学习中使用聚类进行的图像分割,深度学习中的图像分割是个有监督问题,需要有分割金标准(ground truth)作为训练的标签。
在图像分割的过程中,网络的损失函数一般使用Dice系数作为损失函数,Dice系数简单的讲就是你的分割结果与分割金标准之间像素重合个数与总面积的比值。
【https://blog.csdn.net/liangdong2014/article/details/80573234,医学图像分割中常用的度量指标】
U-net参考文献:
U-net: Convolutional networks for biomedical image segmentation.
https://arxiv.org/pdf/1505.04597.pdf
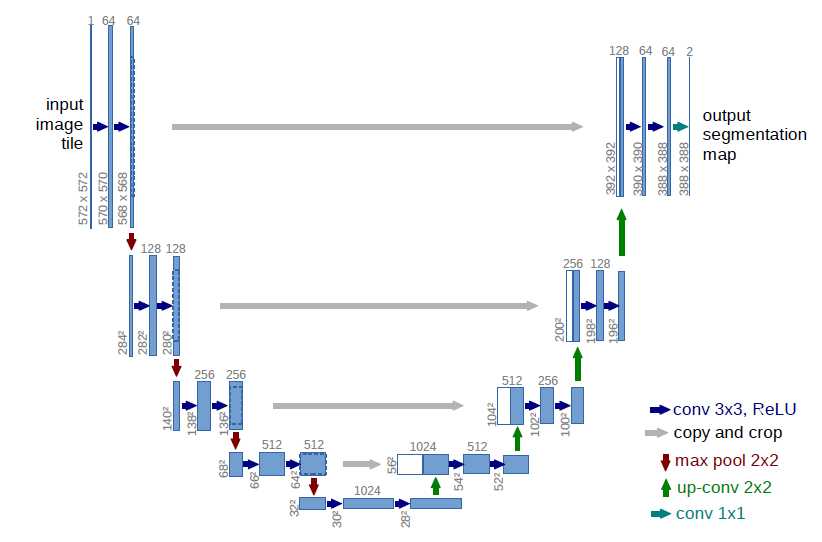
U-net网络结构
U-net网络是一个基于CNN的图像分割网络,主要用于医学图像分割上,网络最初提出时是用于细胞壁的分割,之后在肺结节检测以及眼底视网膜上的血管提取等方面都有着出色的表现。
最初的U-net网络结构如上图所示,主要由卷积层、最大池化层(下采样)、反卷积层(上采样)以及ReLU非线性激活函数组成。整个网络的过程具体如下:
最大池化层,下采样过程:
假设最初输入的图像大小为:572X572的灰度图,经过2次3X3x64(64个卷积核,得到64个特征图)的卷积核进行卷积操作变为568X568x64大小,
然后进行2x2的最大池化操作变为248x248x64。(注:3X3卷积之后跟随有ReLU非线性变换为了描述方便所以没写出来)。
按照上述过程重复进行4次,即进行 (3x3卷积+2x2池化) x 4次,在每进行一次池化之后的第一个3X3卷积操作,3X3卷积核数量成倍增加。
达到最底层时即第4次最大池化之后,图像变为32x32x512大小,然后再进行2次的3x3x1024的卷积操作,最后变化为28x28x1024的大小。
反卷积层,上采样过程:
此时图像的大小为28x28x1024,首先进行2X2的反卷积操作使得图像变化为56X56X512大小,然后对对应最大池化层之前的图像的复制和剪裁(copy and crop),
与反卷积得到的图像拼接起来得到56x56x1024大小的图像,然后再进行3x3x512的卷积操作。
按照上述过程重复进行4次,即进行(2x2反卷积+3x3卷积)x4次,在每进行一次拼接之后的第一个3x3卷积操作,3X3卷积核数量成倍减少。
达到最上层时即第4次反卷积之后,图像变为392X392X64的大小,进行复制和剪裁然后拼接得到392X392X128的大小,然后再进行两次3X3X64的卷积操作。
得到388X388X64大小的图像,最后再进行一次1X1X2的卷积操作。
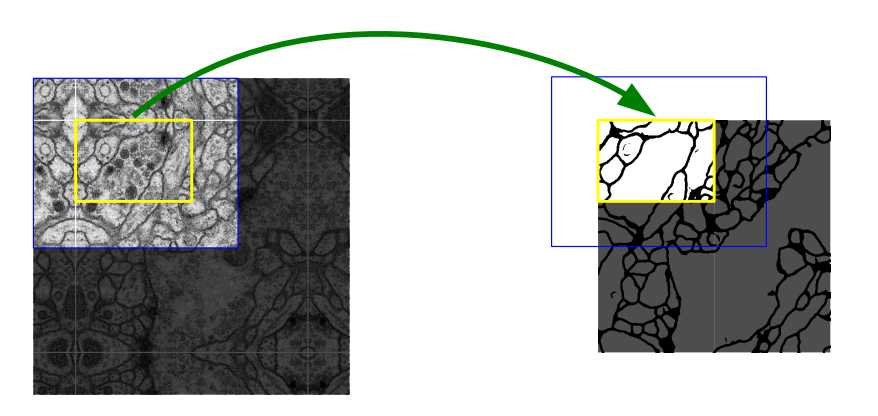
然后得到的结果大概是这样的(下图),需要通过黄色区域的分割结果去推断蓝色区域的分割结果,当然在实际应用中基本上都是选择保持图像大小不变的进行卷积(卷积后周围用0填充)。
【关于卷积、反卷积相关的内容可以参考:https://blog.csdn.net/qq_38906523/article/details/80520950】
讲完了具体怎么做的,再来讲讲U-net的优缺点,可以看到网络结构中没有涉及到任何的全连接层,同时在上采样过程中用到了下采样的结果,
使得在深层的卷积中能够有浅层的简单特征,使得卷积的输入更加丰富,自然得到的结果也更加能够反映图像的原始信息。
(CNN卷积网络,在浅层的卷积得到的是图像的简单特征,深层的卷积得到的是反映该图像的复杂特征)
像上面说的那样,U-net网络的结构主要是对RPN(Region Proposal Network)结构的一个发展,它在靠近输入的较浅的层提取的是相对小的尺度上的信息(简单特征),
靠近输出的较深的层提取的是相对大的尺度上的信息(复杂特征),通过加入shortcut(直接将原始信息不进行任何操作与后续的结果合并拼接)整合多尺度信息进行判断。
但是U-net网络结构仅在单一尺度上进行预测,不能很好处理尺寸变化的问题。
【天池医疗第一名队伍:https://tianchi.aliyun.com/forum/new_articleDetail.html?spm=5176.8366600.0.0.6021311f0WILtQ&raceId=231601&postsId=2947】
因此对于该网络的改进,就我而言,尝试过:1、在最后一层(最后一次下采样之后,第一次上采样之前)加入一个全连接层,目的是增加一个交叉熵损失函数,为了加入额外的信息(比如某张图是是否为某一类的东西)
2、对于每一次的上采样都进行一次输出(预测),将得到的结果进行一个融合(类似于FPN网络(feature pyramid networks),当然这个网络里有其他的东西)
3、加入BN(Batch Normalization)层
改进的结果自然是对于特定要处理的问题有一些帮助。
最后就是相应的代码,由于U-net网络结构较为简单,所以一般使用Keras去写的会比较多,我也是用Keras写的。后续整理了之后将代码的链接贴上。
标签:假设 比较 short reg 整理 医学图像 技术 and img
原文地址:https://www.cnblogs.com/kamekin/p/9574172.html