标签:linear mobile progress hone 分离 class 计算 nec imagenet
设计移动设备上的CNN具有挑战性,需要保证模型小速度快准确率高,人为地权衡这三方面很困难,有太多种可能结构需要考虑。
本文中作者提出了一种用于设计资源受限的移动CNN模型的神经网络结构搜索方法。作者提出将时间延迟信息明确地整合到主要目标中,这样搜索模型可以识别一个网络是否很好地平衡了准确率和时间延迟。
先前的工作中通常用其他量来代表速度指标,如FLOPS,作者的做法是在特定平台(Pixel phone)上运行模型并直接测量其时间延迟。
为适当平衡搜索的灵活性和搜索空间的大小,作者提出了一种新颖的分解分级搜索空间(factorized hierarchical search space),它允许网络中的层的多样性。
实验结果表明,作者的方法始终优于最先进的移动CNN模型。在ImageNet分类任务中,我们的模型在Pixel手机上实现了74.0%的前1精度和76ms延迟,比MobileNetV2(Sandler等2018)快1.5倍,比NASNet快2.4倍(Zoph等2018)在COCO对象检测任务中,我们的模型系列实现了比MobileNets更高的mAP质量和更低的延迟。
卷积神经网络(CNN)在图像分类,物体检测和许多其他应用方面取得了重大进展。随着现代CNN模型变得越来越大(Szegedy等人2017; Hu,Shen和Sun 2018; Zoph等人。 2018年; Real等人,2018年),它们也变得更慢,并且需要更多的计算资源。计算需求的这种增加使得在资源受限的平台(例如手机或嵌入式设备)上部署最先进的CNN模型变得困难。
由于移动设备上可用的计算资源有限,最近的研究主要集中在通过减少网络深度和利用较低成本的操作来设计和改进移动CNN模型,例如深度卷积(Howard et al.2017)和group concon -volution(Zhang et al.2018)。 然而,设计资源受限的移动模型具有挑战性:为了很好地平衡准确性和资源效率,会产生相当大的设计空间。 更复杂的是每种类型的移动设备都有自己的软件和硬件特性,从而可能需要不同的架构以实现最佳的accuracy-efficiency trade-offs。
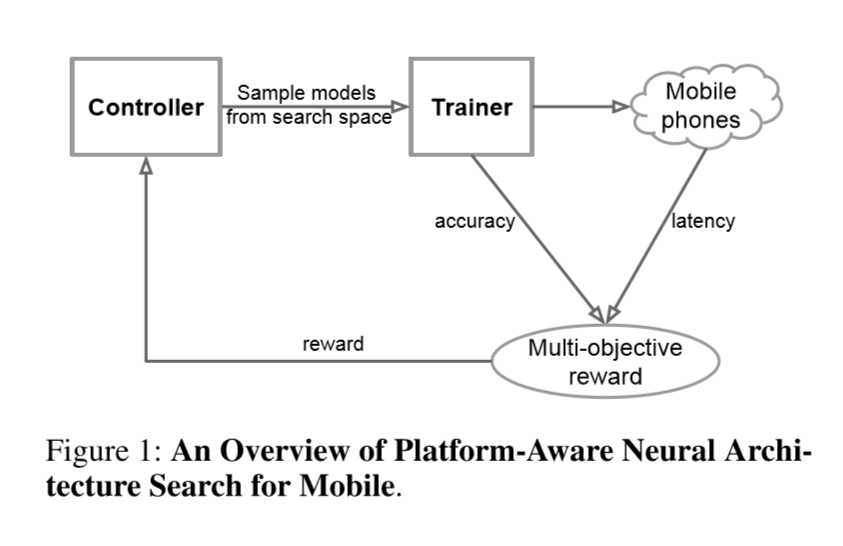
在本文中,作者提出了一种用于设计移动CNN模型的自动神经结构搜索方法。图1显示了我们的方法的整体视图,其中与先前方法的关键差异是延迟感知的多目标奖励(latency aware multi-objective reward)和新颖的搜索空间。
此方法受两个主要想法的启发。
首先,作者将设计问题表述为一个多目标优化问题,该问题考虑了CNN模型的准确性和推理延迟(inference latency)。作者使用强化学习的架构搜索来找到在精确度和延迟之间实现最佳权衡的模型。
其次,我们观察到先前的自动化方法主要是搜索几种类型的小区,然后通过CNN网络重复堆叠相同的小区。那些搜索模型没有考虑到卷积等操作基于它们操作的具体形状不同,在延迟上差异很大:例如,具有相同数量的理论FLOPS但形状不同的两个3x3卷积可能不具有相同的运行时间延迟。
基于这种观察,作者提出了一个由一系列分解块组成的分解层次搜索空间,每个块包含由具有不同卷积运算和连接的分层子搜索空间定义的层列表。结果表明在网络结构的不同深度使用不同的卷积操作,并且可以把测量的推理延迟作为奖励信号的一部分的架构搜索方法能够有效地在这个大的搜索空间中进行搜索。
作者将提出的方法应用于ImageNet分类(Russakovsky等人2015)和COCO目标检测(Lin等人,2014)。实验结果表明,此方法发现的最佳模型明显优于最先进的移动模型。与最近的MobileNetV2(Sandler等人,2018)相比,作者的模型在Pixel手机上的延迟相同,将Im-ageNet top-1精度提高了2%。另一方面,如果限制目标top-1准确度,那么此方法可以找到另一个模型,比MobileNetV2快1.5倍,比NAS-Net快2.4(Zoph等人,2018),并且具有相同的准确度。通过额外的挤压和激励优化(squeeze-and-excitation optimization)(Hu,Shen和Sun 2018),此的方法实现了ResNet-50(He等人2016)精度达到76.13%,参数减少19x,参数乘加运算减少10x。此模型也很好地概括了不同的模型缩放技术(例如,变化的输入图像尺寸),与MobileNetV2相比,ImageNet的top-1 accuracy始终提高了约2%。通过将我们的模型作为特征提取器用于SSD对象检测框架中,与MobileNetV1和MobileNetV2相比,作者的模型改善了COCO数据集的推理延迟和mAP质量,并实现了与SSD300相当的mAP质量(22.9 vs 23.2)(Liu et al 2016),而计算成本降低35。
在过去几年中,提高CNN模型的资源效率一直是一个活跃的研究课题。一些常见的方法包括:
1. quantizing the weights and/or activations of a baseline CNN model into lower-bit representations (Han, Mao, and Dally 2015; Jacob et al. 2018)
2. pruning less important filters (Gor-don et al. 2018; Yang et al. 2018) during or after training, in order to reduce its computational cost.
然而,这些方法依赖2基线模型,并无法觉得学习CNN操作的新颖组合。
另一种常见方法是直接人工设计更高效的操作和神经架构:
1. SqueezeNet(Iandola et al. 2016) reduces the number of parameters and computation by pervasively using lower-cost 1x1 convolu-tions and reducing filter sizes;
2. MobileNet (Howard et al. 2017) extensively employs depthwise separable convolu-tion to minimize computation density;
3. ShuffleNet (Zhang et al. 2018) utilizes low-cost pointwise group convolution and channel shuffle; Condensenet (Huang et al. 2018) learns to connect group convolutions across layers;
4. Recently, MobileNetV2 (Sandler et al. 2018) achieved state-of-the-art re-sults among mobile-size models by using resource-efficient inverted residuals and linear bottlenecks.
然而,考虑到潜在的巨大设计空间,这些人工设计的模型通常需要相当大的人力,并且仍然不是最理想的。
最近,人们越来越关注自动化神经结构设计过程,特别是对于CNN模型。
NASNet(Zoph和Le 2017; Zoph等人,2018)和MetaQNN(Baker等人,2017)使用强化学习开始了自动神经结构搜索的浪潮。
自此,神经结构搜索得到进一步发展,出现了渐进式搜索方法(Liu et al.2018a),参数共享(Pham et al.1188),分层搜索空间(Liu et al.2018b),网络传输(Cai et al al.2018),进化搜索(Real et al.2018),或差异搜索算法(Liu,Simonyan和Yang 2018)。虽然这些方法可以通过重复堆叠搜索的单元格来生成可用于移动设备大小的模型,但是它们不会将移动平台约束结合到搜索过程或搜索空间中。最近,MONAS(Hsu等2018),PPP-Net(Dong等2018),RNAS(Zhou等2018)和Pareto-NASH(Elsken,Metzen和Hutter 2018)试图在搜索CNN结构的同时优化多个目标,例如搜索CNN时的模型大小和准确性,但它们仅限于CIFAR-10等小型任务。相比之下,本文针对实际测得的移动延迟约束,并关注更大的任务,如ImageNet分类和COCO对象检测。
作者将设计问题表述为多目标搜索,旨在寻找具有高精度和低推理延迟的CNN模型。 与先前优化间接指标(如FLOPS或参数数量)的工作不同,我们通过在真实移动设备上运行CNN模型,然后将真实世界推理延迟纳入我们的目标,来考虑直接的实际推理延迟。 这样做可以直接衡量实践中可实现的目标:我们在代理推理设备上的早期实验,包括单核桌面CPU延迟和模拟成本模型,表明由于移动设备硬件/软件配置的多样性,很难接近实际延迟。
给定模型m,用ACC(m)表示其在目标任务上的准确性,LAT(m)表示目标移动平台上的推断延迟,T是目标延迟。 一个通用的方法是将T视为硬性约束条件并在此约束下最大化准确度:

但是,这种方法仅最大化单个度量,并且不提供多个Pareto最优解。 事实上,如果模型具有最高的准确度而不增加延迟,或者它具有最低的延迟而不降低准确性,那么该模型称为Pareto最优(Deb 2014)。 考虑到执行体系结构搜索的计算成本,我们更感兴趣的是在单个体系结构搜索中找到多个Pareto最优解决方案。
虽然文献中有许多方法(Deb 2014),但我们使用定制的加权乘积法1来近似Pareto最优解,将优化目标设定为:

其中α和β是应用特定常数。选择α和β的经验规则是检查如果我们将延迟加倍或减半,预期准确度增益或损失的程度。例如,将MobileNetV2的延迟加倍或减半(Sandler et al. 2018)会带来约5%的准确度增益或损失,因此可以凭经验设置α=β= -0.07,![]() 。通过以这种方式设置(α,β),等式2可以有效地近似目标延迟T附近的帕累托解。
。通过以这种方式设置(α,β),等式2可以有效地近似目标延迟T附近的帕累托解。
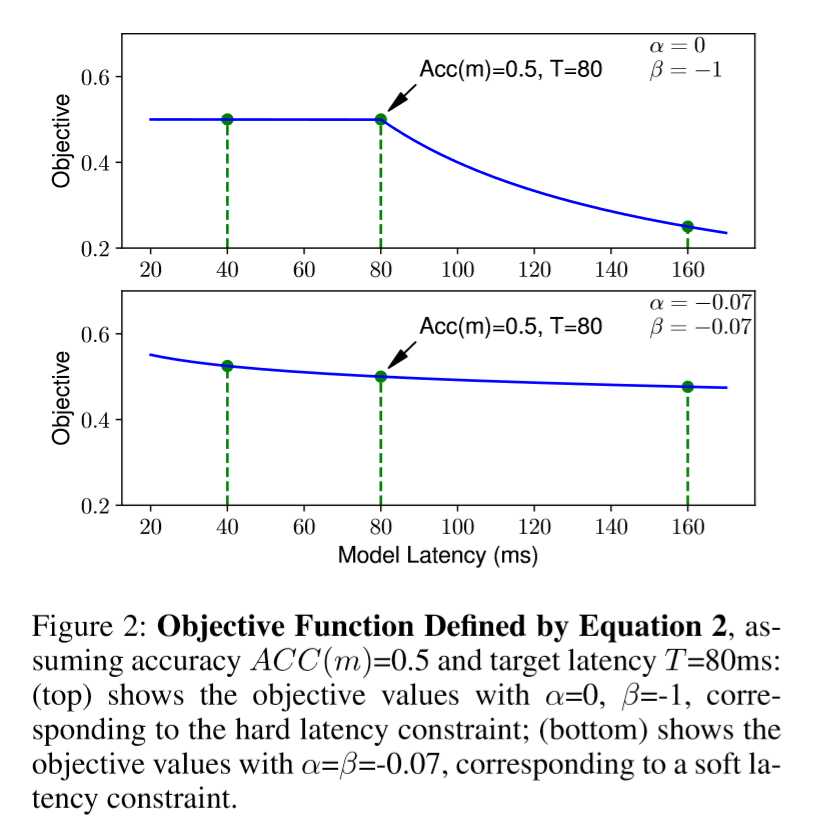
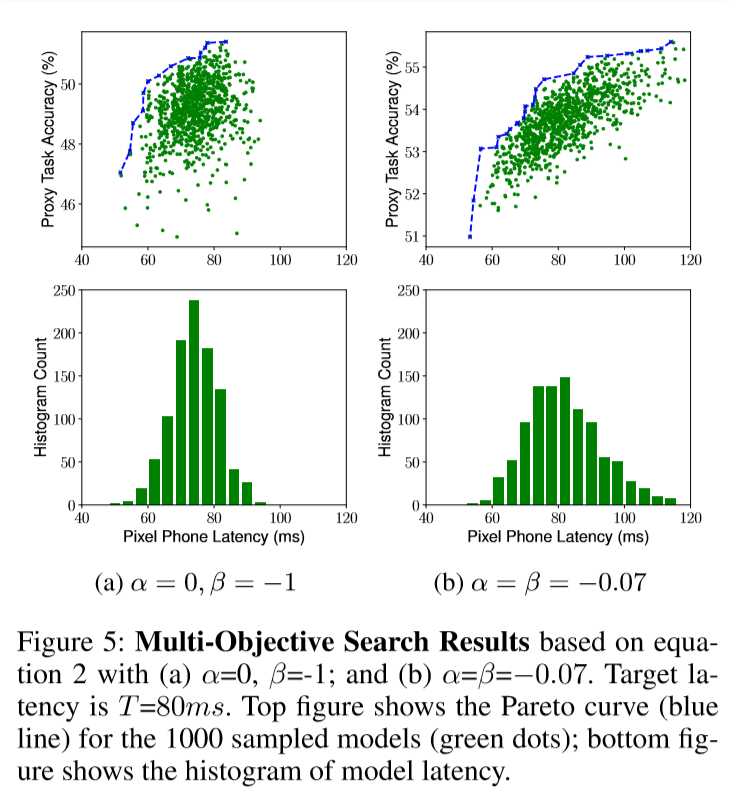
图2显示了具有两个典型值(α,β)的目标函数。在上方图像(α= 0,β= -1)中,当测量到的时间延迟小于目标延迟时,我们只是使用准确度作为目标值;否则,严重地惩罚目标值以阻止 违反延迟约束的模型(otherwise,wesharply penalize the objective value to discourage models from violating latency constraints.)。 下方图形(α=β= -0.07)将目标延迟T视为软约束,并基于测量的等待时间平滑地调整目标值。 在本文中,我们设置α=β= -0.07,以便在单个搜索实验中获得多个Pareto最优模型。 探索动态适应帕累托曲线的奖励函数将是一个有趣的未来方向。
受近期工作的启发(Zoph和Le 2017; Pham等,2018; Liu等,2018b),作者采用基于梯度的强化学习方法为我们的多目标搜索问题找到Pareto最优解。 我们选择强化学习是因为它很方便且奖励很容易定制,但是我们期望其他搜索算法如evolution(Real et al.2018)也应该有效。
具体地说,我们遵循与(Zophetal.2018)相同的想法,并将搜索空间中的每个CNN模型映射到一系列tokens。 These tokens are determined by a sequence of actions ![]() from the reinforcement learning agent based on its parameters θ. 我们的目标是最大化预期的奖励:
from the reinforcement learning agent based on its parameters θ. 我们的目标是最大化预期的奖励:
![]()
where m is a sampled model uniquely determined by action a1:T,and R(m) is the objective value de?ned by equation 2.
如图1所示,搜索框架由三个部分组成:基于递归神经网络(RNN)的控制器,用于获得模型精度的训练器,以及用于测量延迟的基于移动电话的推理引擎。 我们遵循众所周知的sample-eval-update循环来训练控制器。 在每个步骤中,控制器首先使用其当前参数对一批模型进行采样,方法是基于来自其RNN的softmax logits预测一系列tokens。 对于每个采样模型m,我们在target任务上训练它以获得其精度ACC(m),并在真实手机上运行它以获得其推理延迟LAT(m)。 然后,我们使用等式2计算奖励值R(m)。在每个步骤结束时,通过使用近端策略优化最大化等式4定义的预期奖励来更新控制器的参数(Schulman等人2017)。 重复sample-eval-update循环,直到达到最大步数或参数收敛。
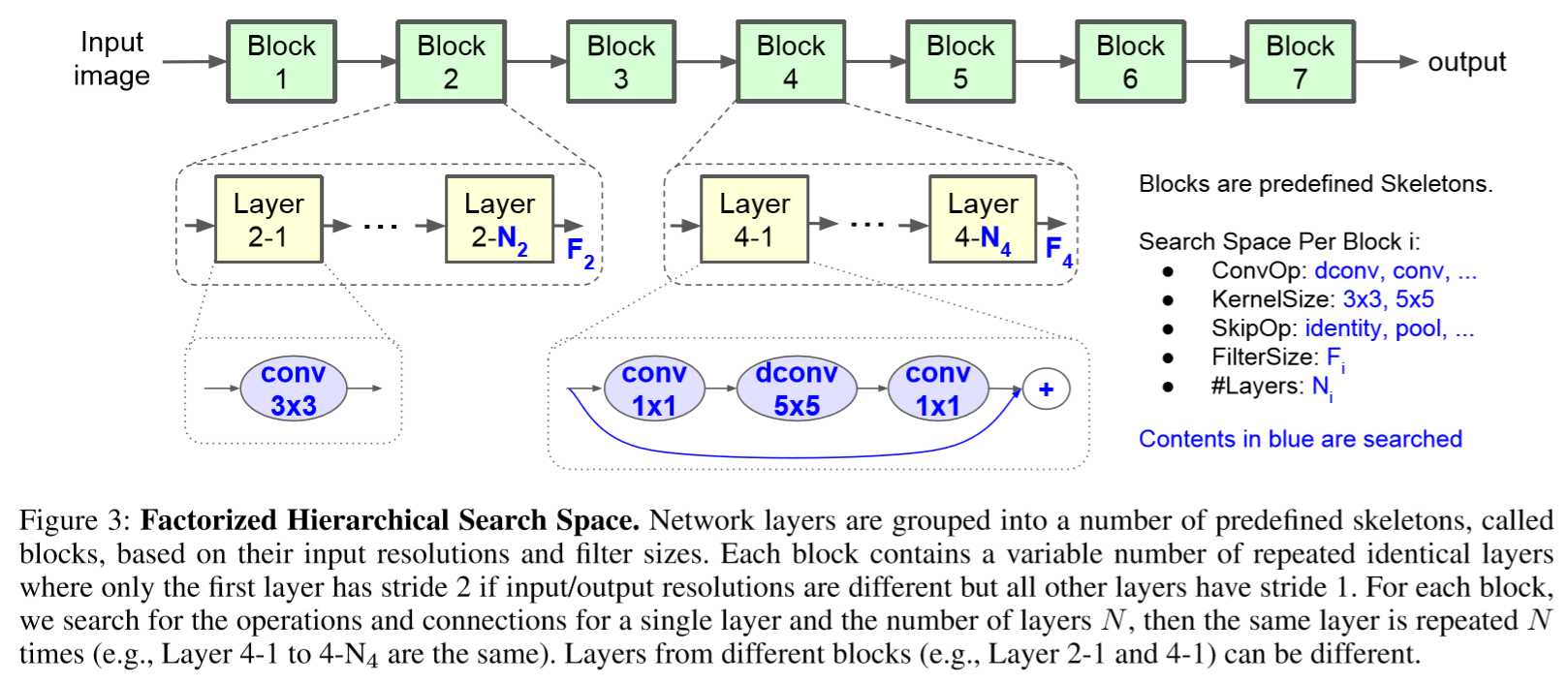
最近的研究(Zoph等人,2018; Liu等人,2018b)显示,明确定义的搜索空间对于神经结构搜索非常重要。 在本节中,我们将介绍一种新颖的分解分层搜索空间,它将CNN层分成组并搜索每组的操作和连接。 与之前的架构搜索方法(Zoph和Le 2017; Liu et al。2018a; Real et al.2018)相反,之前的搜索方法只搜索少量复杂的单元,然后重复堆叠相同的单元,我们简化了每单元搜索空间,但允许出现不同的单元。
我们的直觉是,我们需要根据输入和输出形状搜索最佳操作,以获得最佳的准确延迟权衡。 例如,CNN模型的早期阶段通常处理更大量的数据,因此比后期阶段对推理延迟具有更高的影响。 形式上,考虑广泛使用的深度可分离卷积(Howard et al.2017)内核,表示为四元组(K,K,M,N),它将大小(H,W,M)2的输入转换为输出 尺寸(H,W,N),其中(H,W)是输入分辨率,M,N是输入/输出滤波器尺寸。 乘加计算的总数可以描述为:
![]()

直接在像ImageNet或COCO这样的大型任务上搜索CNN模型是非常昂贵的,因为每个模型需要数天才能收敛。按照之前的工作常规做法(Zoph et al.1188; Real et al.1188),我们在较小的替代任务上进行结构搜索实验,然后将结构搜索期间发现的表现最佳的模型转移到完全的目标任务上。但是,找到准确性和延迟的良好替代任务并非易事:必须考虑任务类型,数据集类型,输入图像大小和类型。我们对CIFAR-10和Stanford Dogs Dataset的初步实验(Khosla等人2011)表明,当考虑模型延迟时,这些数据集对于ImageNet来说不是很好的替代任务。在本文中,我们直接在ImageNet训练集上执行我们的架构搜索,但训练步骤较少。由于在架构搜索文献中通常有一个单独的设置来测量精度,我们还保留了从训练集中随机选择的50K图像作为固定的值集。在架构搜索期间,我们使用积极的学习计划在代理训练集的5个时期训练每个抽样模型,并在50K验证集上评估模型。( During architecture search, we train each sampled model on 5 epochs of the proxy training set using an aggressive learning schedule, and evaluate the model on the 50K validation set.)同时,我们通过将模型转换为TFLite格式并在Pixel 1手机的单线程大CPU核心上运行来测量每个采样模型的实际延迟。总的来说,我们的控制器在架构搜索期间对大约8K模型进行采样,但只有少数表现最佳的型号(<15)被传输到完整的ImageNet或COCO。请注意,在架构搜索期间,我们从不评估原始ImageNet验证数据集。
RMSProp optimizer with decay 0.9 and momentum 0.9.
Batch norm is added after every convolution layer with momentum 0.9997, and weight decay is set to 0.00001.
Following (Goyal et al. 2017), we linearly increase the learning rate from 0 to 0.256 in the first 5-epoch warmup training stage,
and then decay the learning rate by 0.97 every 2.4 epochs.
These hyperparameters are determined with a small grid search of 8 combinations of weight decay {0.00001, 0.00002}, learning rate {0.256, 0.128}, and batchnorm momentum {0.9997, 0.999}. We use standard Inception preprocessing and resize input images to 224 224 unless explicitly specified in this paper.
we plug our learned model architecture into the open-source TensorFlow Object Detection framework, as a new feature extractor. Object detection training settings are set to be the same as (Sandler et al. 2018), including the input size 320×320.
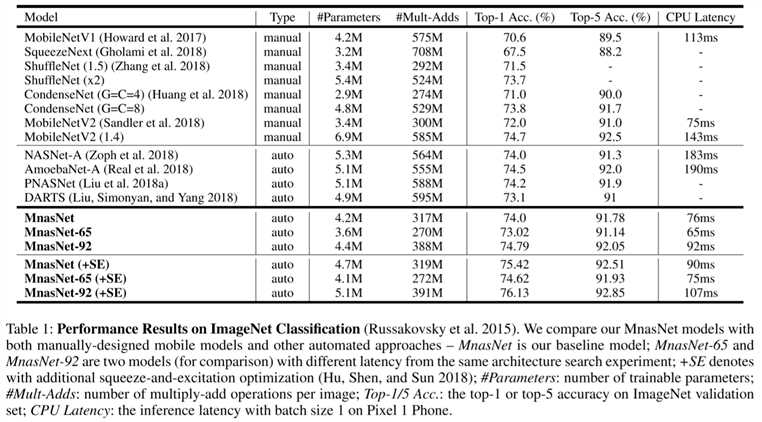
表1显示了我们的ImageNet模型的性能(Russakovsky等,2015)。 我们将目标延迟设置为T = 80ms,这与MobileNetV2(Sandler等人,2018)类似,并使用等式2,其中α=β= -0.07作为我们在架构搜索期间的奖励函数。 之后,我们选择三个表现最佳的MnasNet模型,在同一搜索实验中进行不同的延迟准确性权衡,并将结果与现有的移动CNN模型进行比较。
如表中所示,我们的MnasNet型号在Pixel手机上实现了74%的top-1 accuracy,3.17亿次乘法和76ms延迟,在这种典型的移动设备延迟约束下实现了最先进的精确度 。 与最近的MobileNetV2(Sandler等人,2018)相比,Mnas-Net将top-1 accuracy提高了2%,同时保持了相同的延迟; 更准确地说,MnasNet-92在同一个Pixel手机上的top-1 accuracy为74.79%,比MobileNetV2快1.55倍。 与最近的自动搜索的CNN模型相比,我们的MnasNet比移动大小的NASNet-A(Zoph等人,2018)快2.4倍,具有相同的top-1 accuracy。
为了公平比较,最近的挤压和激励优化(squeeze-and-excitation optimization)(Hu,Shen和Sun 2018)未包含在我们的基线MnasNet模型中,因为表1中的所有其他模型都没有这种优化。 但是,我们的方法可以利用这些最近引入的操作和优化。 例如,通过在表1中引入squeeze-and-excitation optimization表示为(+ SE),我们的MnasNet-92(+ SE)模型实现了ResNet-50(He等人2016)top-1 accuracy为76.13%,参数量减少19x,乘加运算减少10x。
值得注意的是,我们只调MnasNet的超参数,只用了8种learning rate、weight decay、batch norm momentum的8种组合,然后简单地使用MnasNet-65和MnasNet-92的相同训练设置。 因此,我们确认性能增益来自我们新颖的搜索空间和搜索方法,而不是训练的超参数设置。
我们的多目标搜索方法允许我们通过设置奖励等式2中α和β的不同值来处理硬延迟和软延迟约束。
图5显示了典型α和β值的多目标搜索结果。 当α= 0,β=-1时,延迟被视为硬约束,因此控制器倾向于在目标延迟值附近的非常小的延迟范围内搜索模型。 另一方面,通过设置α=β=0.07,控制器将目标延迟视为软约束,并尝试在更宽的延迟范围内搜索模型。 它在80ms内围绕目标延迟值采样更多模型,但也探索延迟小于60ms或大于110ms的模型。 这允许我们在单个架构搜索中从Pareto曲线中选择多个模型,如表1所示。
标签:linear mobile progress hone 分离 class 计算 nec imagenet
原文地址:https://www.cnblogs.com/Rainbow2015/p/9568776.html