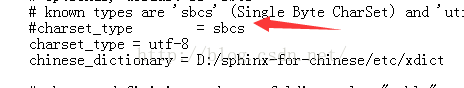标签:管理员 自带 indexer 不用 使用方法 term 均衡 一段 集成
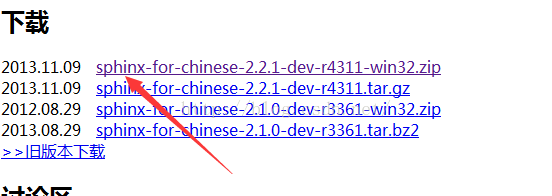
sphinx-for-chinese的使用方法将使用 sphinx-for-chinese-2.2.1-dev-r4311-win32 为例子,目前我只找到最新的是这个版本2013.11.09发布。
下载地址:http://sphinxsearchcn.github.io/
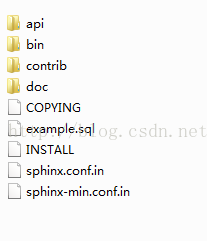
下载完后解压出来得到以下文件
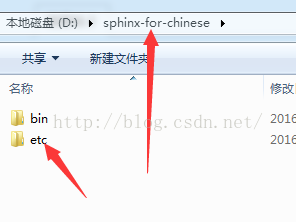
将bin目录与及所有文件复制到你喜欢的安装目录,比如D盘或E盘,这里我放到D盘sphinx-for-chinese文件夹(名字任意,你可以取别的英文名)
然后在刚才的sphinx-for-chinese目录下建一个etc文件夹并复制 sphinx.conf.in 到刚才建立的etc目录中,然后将sphinx.conf.in重命名成sphinx.conf。最终我的D盘sphinx-for-chinese目录文件结构如下:
现在将 sphinx-for-chinese 安装成windows服务程序,这样系统启动时会自行运行sphinx-for-chinese。
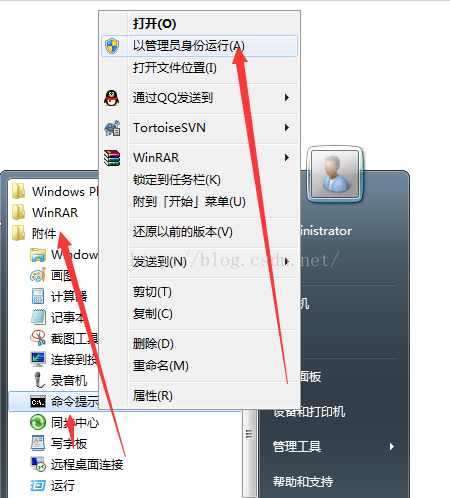
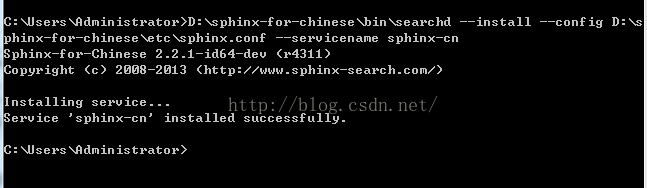
1.打开Windows的CMD窗体,即命令行提示符窗体(位置:开始菜单 -》 所有程序 -》附件),记得要用管理员身份运行。(在图片上点右键就可以用管理员身份运行)。
在CMD窗口中输入以下字符串,记得你安装的目录和我这不一样是要变的。
D:\sphinx-for-chinese\bin\searchd --install --config D:\sphinx-for-chinese\etc\sphinx.conf --servicename sphinx-cn
--servicenamesphinx-cn 这一段大家看好,--servicename后面可以是你自己想要的英文名称。
删除服务的命令是:D:\sphinx-for-chinese\bin\searchd --delete --servicename sphinx-cn
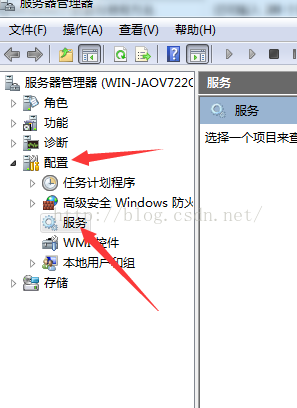
2. 现在,来看看刚才的服务有没有安装成功。桌面上 找到 “我的电脑” 或 “计算机” 这个图标,然后在上面右键会弹出一个菜单。点”管理“菜单后就会出现“服务器管理器”界面。
“服务器管理器”界面中,找到并展开“配置”就能看到有一个“服务” 呢,然后点这个服务,在右边就会出现一个大列表。
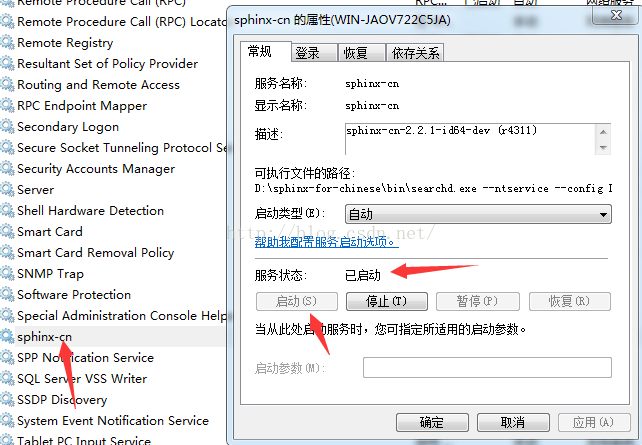
在右边列表中,看看有没有一个叫 sphinx-cn 名称的服务,如果有,就说明安装是成功的,但不一定代表这个服务在运行。
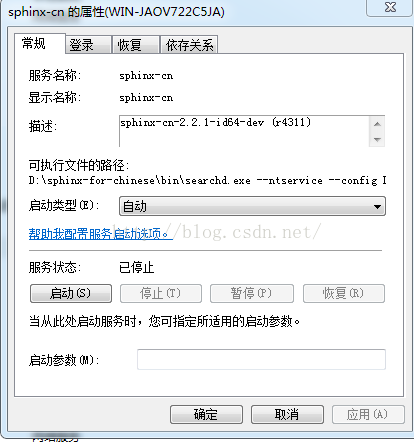
大家看,没有运行,估计是运行不起来,双击,打开看看,如下图。
我们看到,启动类型是“自动”,但操作状态是:已停止。大家可以点击 “启动“ 按钮,看能不能启动,如果能启动,那就恭喜你,当目前为止我这是不能启动的。需要一些配置才能启动。
先在 sphinx-for-chinese 目录下新建data文件夹和一个log文件夹,一会要用到,名称可以任意(用英文或拼音命名),但后面填写必须和这一样。
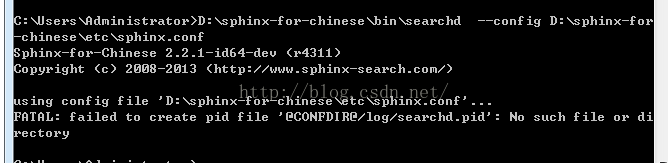
在cmd窗体中,输入以下命令,看出现什么信息,从而排除为什么上面的服务启动不了。
D:\sphinx-for-chinese\bin\searchd --config D:\sphinx-for-chinese\etc\sphinx.conf
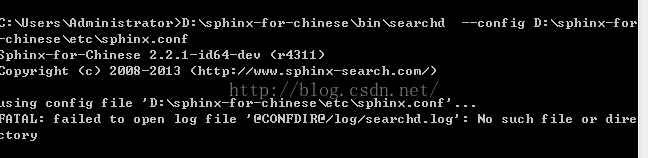
上面显示 创建pid文件时找不到文件或目录。接下来要做的是在sphinx.conf文件中查找 @CONFDIR@/log/searchd.pid 找到后修改成
pid_file = D:/sphinx-for-chinese/log/searchd.pid
接着再执行刚才的cmd命令,在CMD窗体上按一下键盘向上键,就会自动出现,之前输入的命令。
D:\sphinx-for-chinese\bin\searchd --config D:\sphinx-for-chinese\etc\sphinx.conf
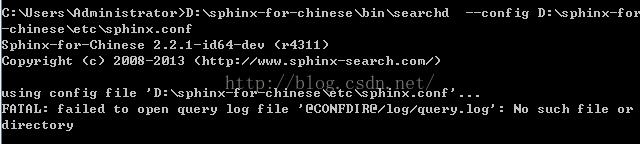
出现如下提示,和刚才一样,搜索字符串 @CONFDIR@/log/searchd.log ,然后修改。
l修改前:log =@CONFDIR@/log/searchd.log
修改后:log = D:/sphinx-for-chinese/log/searchd.log
修改后保存,然后继续运行刚才的cmd命令,这个过程会很长,直到正常为止。以后直接贴图了,不在说了。
l修改前:query_log = @CONFDIR@/log/query.log
修改后:query_log = D:/sphinx-for-chinese/log/query.log
我们接下来再试一下刚才的cmd命令,会发现提示和以前不一样了,看下面的图。
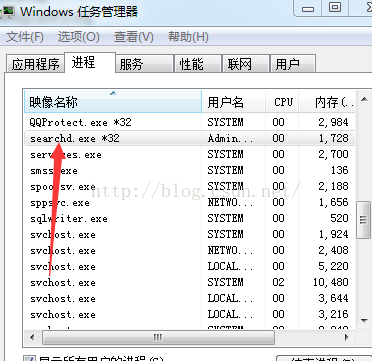
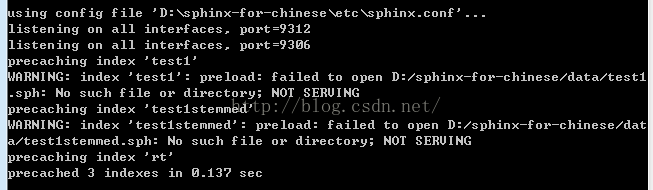
看起来正常了,但没有索引,这个一会再说,先打开windows 进程管理器,看看searchd.exe进程在不在.
看图中显示,searchd.exe已经运行了,我们强行结束这个进程吧(结束进程就不用我说了吧),改用服务启动试试。
在服务器管理器界面中,找到sphinx-cn并双击这个服务,会弹出一个小窗体,上面有个启动按钮,点击“启动”按钮即可,最终效果如下。
好了,当目前为止,初步安装成功,接下来要打开sphinx.conf并进行一些配置.
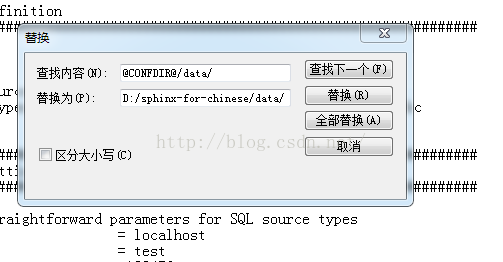
打开sphinx.conf 并替换所有 @CONFDIR@/data/ 字符串为 D:/sphinx-for-chinese/data/ 然后保存。
然后,停止刚才 sphinx-cn 服务,再用cmd运行一下
D:\sphinx-for-chinese\bin\searchd --config D:\sphinx-for-chinese\etc\sphinx.conf
看有没有错误信息。
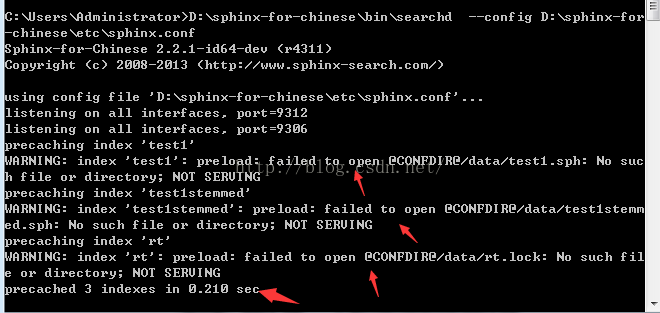
从图中可以看出,只差没有索引了,在任务管理器中,结束searchd.exe进程,然后对
sphinx.conf进行设置,这里将使用我的数据库表为例,大家可以修改成自己的。
source src1 这里src1可以改名,改名后其它地方用到src1是就得和这个一样
配置数据库信息
type = mysql
sql_host = localhost
sql_user = test
sql_pass =123456
sql_db = www.panshy.com
sql_port = 3306 # optional, default is 3306
以下信息,配置文件中没有,就自己加上
找到 sql_query_pre = SET NAMES utf8 去掉前面的 #号
sql_query_info_pre = SET NAMES utf8
sql_query_info = SELECT * FROM www_panshy_com_ecms_pansharticle WHERE id=$id
sql_query = SELECT id, newstime AS date_added, title, newstext, titleurl, id as msgid, classid, userid,username,username as softtype,username as filesize, 1983 as dbtype FROM www_panshy_com_ecms_pansharticle
#sql_query第一列id需为整数
修改完后,保存,然后在cmd窗体中运行,以下命令进行索引。
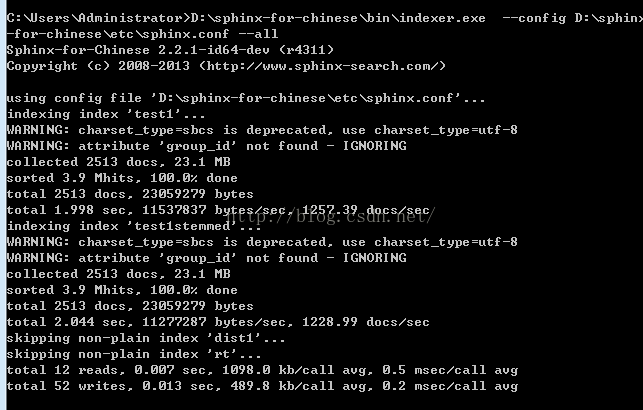
D:\sphinx-for-chinese\bin\indexer.exe --config D:\sphinx-for-chinese\etc\sphinx.conf --all
正常的话是下面这样子
data目录下生成了一些文件,如下图
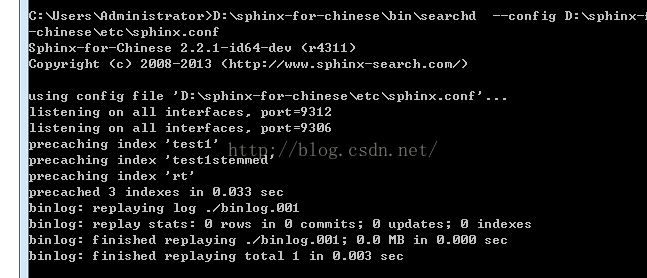
最后在cmd中运行D:\sphinx-for-chinese\bin\searchd --config D:\sphinx-for-chinese\etc\sphinx.conf 再次查看效果,正常的图:
到目前为止,sphinx-for-chinese基本安装配置完成。接下来就是集成中文分词啦.
下载xdict_1.1.tar.gz (原文链接中有下载)
解压到 D:\sphinx-for-chinese\etc目录得到一个xdict_1.1.txt文件。
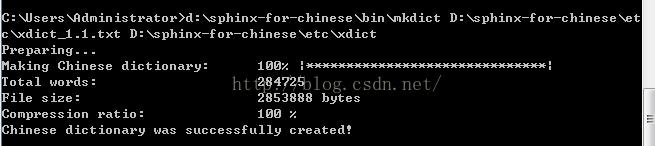
在cmd窗体中,运行以下命令进行转换。
d:\sphinx-for-chinese\bin\mkdict D:\sphinx-for-chinese\etc\xdict_1.1.txt D:\sphinx-for-chinese\etc\xdict
得到一个xdict文件
修改sphinx.conf索引配置文件
查找 charset_type = sbcs 然后删除掉或注释掉这行
添加以下两项
charset_type = utf-8
chinese_dictionary = D:/sphinx-for-chinese/etc/xdict
至此,完成中文支持配置。
以上如果出现index rt错误,请将配置文件中index rt项删除即可。
具体sphinx-for-chinese使用方法与sphinx英文版一样,可以参考sphinx官方网站的用户手册。
原文链接:http://www.panshsoft.net/thread-3-1-1.html
http://www.panshy.com/articles/201608/dev-2752.html
以下引用sphinx-for-chinese官方原文
http://sphinxsearchcn.github.io/
3.一些注意事项sphinx-for-chinese只支持UTF-8编码,数据源输出数据时请做转换,使用MySQL时一般需要添加"SET NMAES utf8"语句。使用xmlpipe时,需要注意两点:一个是XML中尽可能使用CDATA标签,以避免特殊字符影响xml解析;另一个是sphinx配置中启用xmlpipe_fixup_utf8=1选项,以尽可能的避免因非法UTF-8字符串引起解析错误。
若需要检查中文分词支持是否启用,请使用search命令,例子如下:
./search -c ../etc/sphinx.conf 分享身边的精彩
sphinx-for-chinese 2.1.0-dev (r3006)
Copyright (c) 2008-2011, sphinx-search.com
using config file ‘../etc/sphinx.conf‘...
index ‘test1‘: query ‘分享身边的精彩 ‘: returned 0 matches of 0 total in 0.000 sec
words:
1. ‘分享‘: 6 documents, 7 hits
2. ‘身边‘: 26 documents, 38 hits
3. ‘的‘: 5344 documents, 178743 hits
4. ‘精彩‘: 5 documents, 6 hits
可以看到words中列出了各个中文单词,说明中文分词启用成功。
出现乱码时,请检查数据源的编码是否为UTF-8,程序API中的调用是否为UTF-8,若为命令行测试,请检查终端环境是否为UTF-8。windows的命令行环境为GBK,若在windows的命>令行下进行测试,请注意输入数据的编码。
如果数据源不是MySQL,而是oracle、纯文本或者其他数据源,可以采用xmlpipe的方式进行索引。具体方法是采用容易快速开发的语言,如PHP,Python,Ruby或者Lua(C,C++等当然也可以)等读取数据源,然后按照既定格式输出XML格式的数据,供sphinx读取。99.9%的情况下sphinx是可以索引任何数据的,不需要额外的低层处理。
4.中文搜索优化对中文进行全文检索时,一般需要进行中文分词(segmentation)。中文分词的过程,一般叫做tokenize,也就是将一段文本分成多个token,索引的时候对每个token进行倒排索引(inverted index)。中文与拉丁语系不同,例如英文单词之间用空格做区分,而中文没有明显的单词分隔,这就需要算法对中文字符串进行分词,而分词的精确度就会影响中文搜索的效果。举个例子,“研究生命起源”如果分成“研究生”“命”“起源”,用“研究”一词是搜索不到的,用“生命”也搜索不到;如果分成“研究”“生命”“起源”,则用“研究”和“生命”都可以搜索到。同理,如果“上海市”被分成“上海”“市”,用“上海”是搜索不到的。
为了提高搜索效果,一般可以:
提高分词精度。这个一般与分词算法有关,而现在常用的基于词典的分词算法在分词精度上差别不大(不会有数量级的差别)。另外可以对词典进行调整,比如针对医药类网站,可以在词典中添加医药类词库,针对特殊行业领域进行词典优化,也可以提高分词效果。关于词库,一般可以参考搜狗细胞词库。
采用同义词、近义词处理。这一部分主要是针对“餐厅”“餐馆”或者“上海”“上海市”等同义或者近义处理。现在有些针对索引的分词算法采用多分的处理方法,比如将“上海市”分为“上海市”“上海”“市”,这样“上海市”“上海”都可以搜索到,但这样会增加token数量,增加索引数据,影响搜索效率,并且单纯靠算法对多分的处理粒度很难控制;另外还有将同>义词词库整合到全文检索里的做法,这样会增加搜索程序的复杂度,不利于升级和微调。这里建议的做法是将同义词、近义词的处理放到搜索外围,即对用户输入的搜索语句进行处理和转换,利用sphinx的搜索语法进行处理。具体做法,可以整理一份同义词、近义词的词库,利用内存型数据库保存,作成daemon或者web service的接口,对用户的搜索输>入进行预处理,不仅开发成本低,速度快,而且模块化高,容易调整,利于升级。
5.搜索性能优化以及高可用容错集群搭建当索引数据过大或者访问量过大时,可以:
对索引数据进行分区,这一部分与数据库拆表十分类似。即把数据水平或者垂直分区,并在应用程序里做一些调整,不同的搜索请求,分配到不同的索引。这种做法的思路,还是尽可能的减少单个索引数据块(index data block)的大小,进而减少每一次请求所需扫描数据的大小,提高响应时间。
合理的更新策略。根据更新频率,采用main+delta的两层处理或者main+today+delta的三层处理,也可以减少更新负担,提高索引数据的更新速度。这一部分通常需要具体问题具体分析。
采用分布式处理,即将数据水平分区,分布在多台机器上。这一部分可以参考http://sphinxsearch.com/docs/2.0.2/distributed.html。
高可用和容错处理。一个是采用replication的处理方法,即一台机器作为master负责索引更新,不接受外部请求,另外多台机器运行sphinx实例,作为slave接受外部请求。master通过inotify和rsync更新slave上的索引数据,外部请求根据算法分配到多个slave上,实现负载均衡和容错处理。同时,还可以利用HAProxy和VRRP实现高可用性和容错集群的>搭建。另外一个方法,是采用sphinx自带的分布式处理方法,并结合heartbeat或者VRRP实现容错处理。
sphinx-for-chinese在windows下安装与使用方法
标签:管理员 自带 indexer 不用 使用方法 term 均衡 一段 集成
原文地址:https://www.cnblogs.com/cjymuyang/p/9582430.html