标签:tom art .com new 文件打印 === targe 名称 现在
说明:
spark --version : 2.2.0
我有两个json文件,分别是emp和dept:
emp内容如下:
{"name": "zhangsan", "age": 26, "depId": 1, "gender": "male", "salary": 20000}
{"name": "lisi", "age": 36, "depId": 2, "gender": "female", "salary": 8500}
{"name": "wangwu", "age": 23, "depId": 1, "gender": "male", "salary": 5000}
{"name": "zhaoliu", "age": 25, "depId": 3, "gender": "male", "salary": 7000}
{"name": "marry", "age": 19, "depId": 2, "gender": "female", "salary": 6600}
{"name": "Tom", "age": 36, "depId": 1, "gender": "female", "salary": 5000}
{"name": "kitty", "age": 43, "depId": 2, "gender": "female", "salary": 6000}
{"name": "Tony","age": 36,"depId": 4,"gender":"female","salary": 4030}
dept内容如下:
{"id": 1, "name": "Tech Department"}
{"id": 2, "name": "Fina Department"}
{"id": 3, "name": "HR Department"}
现在我需要通过sparksql将两个文件加载进来并做join,最后将结果保存到本地
下面是操作步骤:
1、初始化配置
val conf = new SparkConf().setMaster("local[2]").setAppName("Load_Data")
val sc = new SparkContext(conf)
val ssc = new sql.SparkSession.Builder()
.appName("Load_Data_01")
.master("local[2]")
.getOrCreate()
sc.setLogLevel("error") //测试环境为了少打印点日志,我将日志级别设置为error
2、将两个json文件加载进来
val df_emp = ssc.read.json("file:///E:\\javaBD\\BD\\json_file\\employee.json")
val df_dept = ssc.read.format("json").load("file:///E:\\javaBD\\BD\\json_file\\department.json")
3、分别将加载进来的两个json文件打印出来,看看是否成功载入
df_emp.show() df_dept.show()
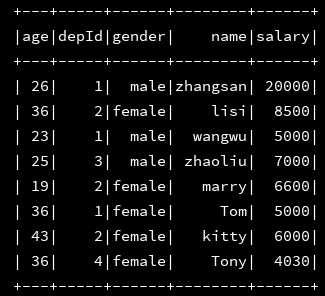
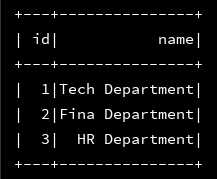
4、数据加载都没有问题,接下来二者进行join操作:
df_emp.join(df_dept,df_emp("depId") === df_dept("id"),"left").show()
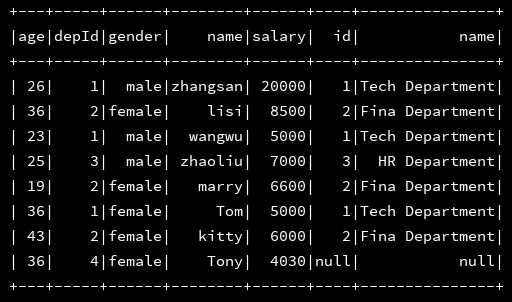
5、这样结果也可以正常打印出来了,貌似是没有什么问题了,接下来直接就save就可以了呗,但是进行save的时候就报错了:
df_emp.join(df_dept,df_emp("depId") === df_dept("id"),"left").write.mode(SaveMode.Append).csv("file:///E:\\javaBD\\BD\\json_file\\rs")
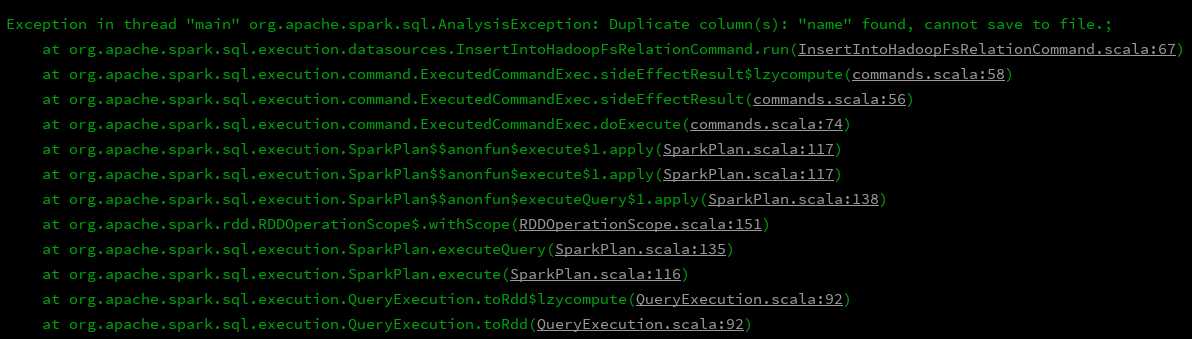
于是开始百度,找到了原因,论坛链接,大致的意思就是说,要保存的表中有相同的name字段,这样是不行的,那么解决方案就很明显了,让两个那么字段名称不相同么,那就分别给他们其别名呗,接下来开始修改代码:
1、初始化配置不变
2、读文件不变
3、跟别获取到两个DF(json文件加载加载进来之后就是两个DF)的列明,并进行分别设置别名
//分别拿出两张表的列名
val c_emp = df_emp.columns
val c_dept = df_dept.columns
//分别对两张表的别名进行设置
val emp = df_emp.select(c_emp.map(n => df_emp(n).as("emp_" + n)): _*)
val dept = df_dept.select(c_dept.map(n => df_dept(n).as("dept_" + n)): _*)
4、接着在进行保存,程序报错消失:
emp.join(dept,emp("emp_depId") === dept("dept_id"),"left").write.mode(SaveMode.Append).csv("file:///E:\\javaBD\\BD\\json_file\\rs")
这里的这个保存的路径说名一下:我是保存在windows本地,因为我配置了hadoop的环境变量,所以如果写本地需要这样写,如果去掉"file:///"的话,idea会认为是hdfs的路径,所有会报错路径找不到错误,如果要写入到hdfs的话,最好将地址写全:hdfs://namenode_ip:9000/file
程序没有报错,然后到指定目录下查看,文件是否写入:
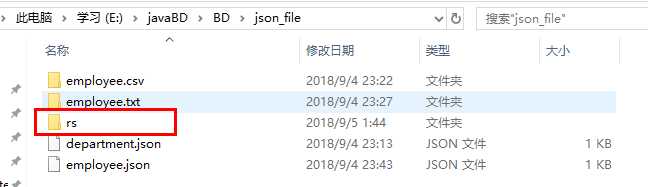
文件已经成功写入,over
标签:tom art .com new 文件打印 === targe 名称 现在
原文地址:https://www.cnblogs.com/Gxiaobai/p/9589622.html