标签:resid 编码 test 不同的 高斯 line name blog tps
本文对前面的几篇文章进行个总结,实现一个小型的图像检索应用。
一个小型的图像检索应用可以分为两部分:
构建图像数据库的过程如下:
得到图像集的查询数据后,对任一图像查找其在数据库中的最相似图像的流程如下:
构建图像集的特征数据库的流程通常是offline的,查询的过程则需要是实时的,基本流程参见下图:
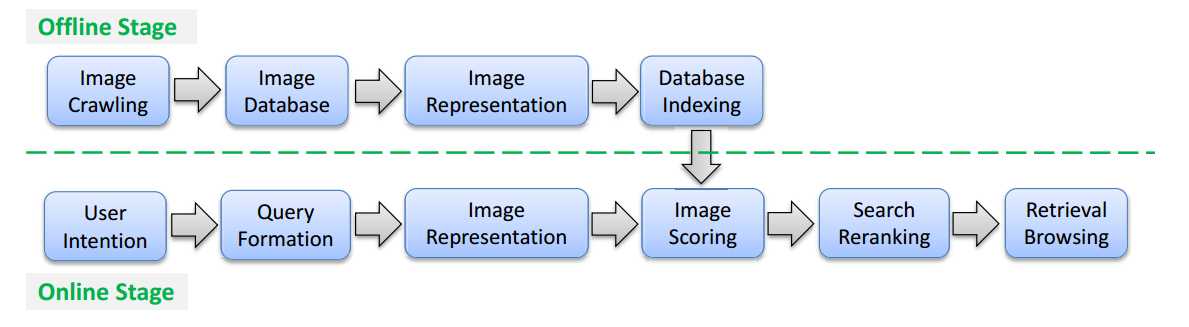
由两部分构成:offline的训练过程以及online的检索查找
下面就使用VLAD表示图像,实现一个小型的图像数据库的检索程序。下面实现需要的功能模块
不管是BoW还是VLAD,都是基于图像的局部特征的,本文选择的局部特征是SIFT,使用其扩展RootSift。提取到稳定的特征点尤为的重要,本文使用OpenCV体哦那个的SiftDetecotr,实例化如下:
auto fdetector = xfeatures2d::SIFT::create(0,3,0.2,10);create的声明如下:
static Ptr<SIFT> cv::xfeatures2d::SIFT::create ( int nfeatures = 0,
int nOctaveLayers = 3,
double contrastThreshold = 0.04,
double edgeThreshold = 10,
double sigma = 1.6
)个人的一些见解。
设置参数时,主要是设置contrastThreshold和edgeThreshold。contrastThreshold是过滤掉平滑区域的一些不稳定的特征点,edgeThreshold是过虑类似边缘的不稳定关键点。设置参数时,应尽量保证提取的特征点个数适中,不易过多,也不要过少。另外,contrastThreshold和edgeThreshold的平衡,应根据要提取的目标是比较平滑的区域还是纹理较多的区域,来平衡这两个参数的设置。
对于有些图像,可能设置的提取特征点的参数叫严格,提取特征点的个数过少,这时候可改变宽松一些的参数。
auto fdetector = xfeatures2d::SIFT::create(0,3,0.2,10);
fdetector->detectAndCompute(img,noArray(),kpts,feature);
if(kpts.size() < 10){
fdetector = xfeatures2d::SIFT::create();
fdetector->detectAndCompute(img,noArray(),kpts,feature);
}阈值10,可根据具体的情况进行调节。
更多关于sift的内容可以参看文章:
关于RootSift和VLAD可以参考前面的文章图像检索(4):IF-IDF,RootSift,VLAD。
Vocabulary的构建过程,实际就是对提取到的图像特征点的聚类。首先提取图像库图像sift特征,并将其扩展为RootSift,然后对提取到的RootSift进行聚类得到Vocabulary。
这里创建class Vocabulary,主要以下方法:
create 从提取到的特征点构建聚类得到视觉词汇表Vocabularyvoid Vocabulary::create(const std::vector<cv::Mat> &features,int k)
{
Mat f;
vconcat(features,f);
vector<int> labels;
kmeans(f,k,labels,TermCriteria(TermCriteria::COUNT + TermCriteria::EPS,100,0.01),3,cv::KMEANS_PP_CENTERS,m_voc);
m_k = k;
}load和save,为了使用方便,需要能够将生成的视觉词汇表Vocabulary保存问文件(.yml)tranform_vlad,将输入的图像进行转换为vlad表示void Vocabulary::transform_vlad(const cv::Mat &f,cv::Mat &vlad)
{
// Find the nearest center
Ptr<FlannBasedMatcher> matcher = FlannBasedMatcher::create();
vector<DMatch> matches;
matcher->match(f,m_voc,matches);
// Compute vlad
Mat responseHist(m_voc.rows,f.cols,CV_32FC1,Scalar::all(0));
for( size_t i = 0; i < matches.size(); i++ ){
auto queryIdx = matches[i].queryIdx;
int trainIdx = matches[i].trainIdx; // cluster index
Mat residual;
subtract(f.row(queryIdx),m_voc.row(trainIdx),residual,noArray());
add(responseHist.row(trainIdx),residual,responseHist.row(trainIdx),noArray(),responseHist.type());
}
// l2-norm
auto l2 = norm(responseHist,NORM_L2);
responseHist /= l2;
//normalize(responseHist,responseHist,1,0,NORM_L2);
//Mat vec(1,m_voc.rows * f.cols,CV_32FC1,Scalar::all(0));
vlad = responseHist.reshape(0,1); // Reshape the matrix to 1 x (k*d) vector
}class Vocabulary有以下方法:
VocabularyVocabulary保存到本地,并提供了load方法图像数据库也就是将图像VLAD表示的集合,在该数据库检索时,返回与query图像相似的VLAD所对应的图像。
本文使用OpenCV提供的Mat构建一个简单的数据库,Mat保存所有图像的vlad向量组成的矩阵,在检索时,实际就是对该Mat的检索。
声明类class Database,其具有以下功能:
add 添加图像到数据库save和load 将数据库保存为文件(.yml)retrieval 检索,对保存的vald向量的Mat创建索引,返回最相似的结果。在上面实现了特征点的提取,构建视觉词汇表,构建图像表示为VLAD的数据库,这里将其组合到一起,创建Trainer类,方便训练使用。
class Trainer{
public:
Trainer();
~Trainer();
Trainer(int k,int pcaDim,const std::string &imageFolder,
const std::string &path,const std::string &identifiery,std::shared_ptr<RootSiftDetector> detector);
void createVocabulary();
void createDb();
void save();
private:
int m_k; // The size of vocabulary
int m_pcaDimension; // The retrain dimensions after pca
Vocabulary* m_voc;
Database* m_db;
private:
/*
Image folder
*/
std::string m_imageFolder;
/*
training result identifier,the name suffix of vocabulary and database
voc-identifier.yml,db-identifier.yml
*/
std::string m_identifier;
/*
The location of training result
*/
std::string m_resultPath;
};使用Trainer 需要配置
yml形式,命名规则是voc-m_identifier.yml和db-m_identifier.yml。 为了方便测试不同参数的数据,这里设置一个后缀参数m_identifier,来区分不同的参数的训练数据。其使用代码如下:
int main(int argc, char *argv[])
{
const string image_200 = "/home/test/images-1";
const string image_6k = "/home/test/images/sync_down_1";
auto detector = make_shared<RootSiftDetector>(5,5,10);
Trainer trainer(64,0,image_200,"/home/test/projects/imageRetrievalService/build","test-200-vl-64",detector);
trainer.createVocabulary();
trainer.createDb();
trainer.save();
return 0;
}偷懒,没有配置为参数,使用时需要设置好图像的路径,以及训练后数据的保存数据。
在Database中,已经实现了retrieval的方法。 这里之所以再封装一层,是为了更好的契合业务上的一些需求。比如,图像的一些预处理,分块,多线程处理,查询结果的过滤等等。关于Searcher和具体的应用耦合比较深,这里只是简单的实现了个retrieval方法和查询参数的配置。
class Searcher{
public:
Searcher();
~Searcher();
void init(int keyPointThreshold);
void setDatabase(std::shared_ptr<Database> db);
void retrieval(cv::Mat &query,const std::string &group,std::string &md5,double &score);
void retrieval(std::vector<char> bins,const std::string &group,std::string &md5,double &score);
private:
int m_keyPointThreshold;
std::shared_ptr<Database> m_db;
};
使用也很简单了,从文件中加载Vaocabulary和Database,设置Searcher的参数。
Vocabulary voc;
stringstream ss;
ss << path << "/voc-" << identifier << ".yml";
cout << "Load vocabulary from " << ss.str() << endl;
voc.load(ss.str());
cout << "Load vocabulary successful." << endl;
auto detector = make_shared<RootSiftDetector>(5,0.2,10);
auto db = make_shared<Database>(detector);
cout << "Load database from " << path << "/db-" << identifier << ".yml" << endl;
db->load1(path,identifier);
db->setVocabulary(voc);
cout << "Load database successful." << endl;
Searcher s;
s.init(10);
s.setDatabase(db);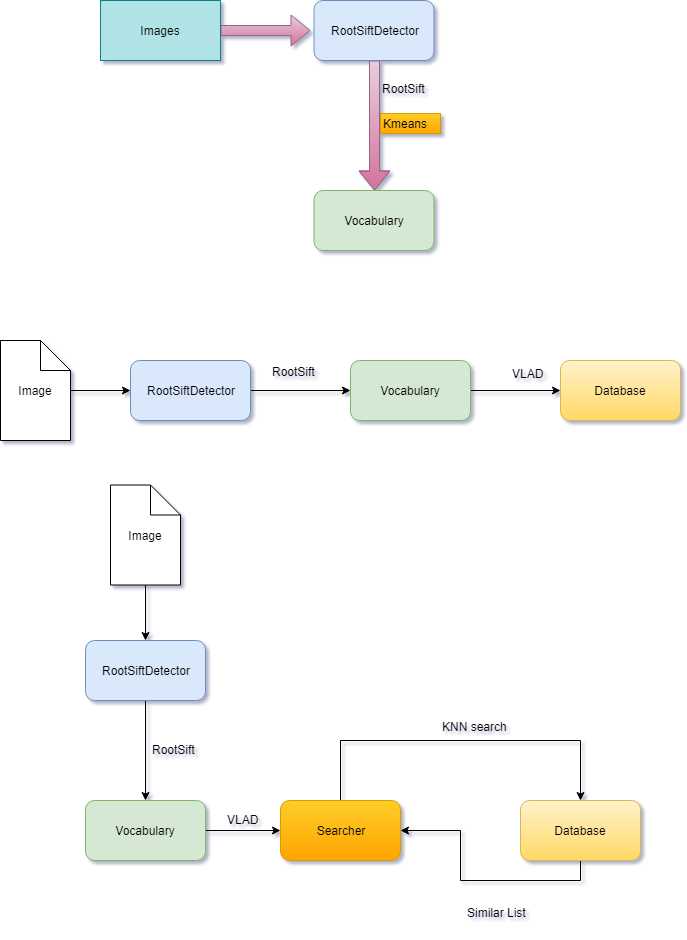
上图来总结下整个流程
VocabularyDatabase标签:resid 编码 test 不同的 高斯 line name blog tps
原文地址:https://www.cnblogs.com/wangguchangqing/p/9590406.html