标签:并且 diff out 存在 wss span cloud 消费者 except
上文我们分析到 loadBalancer 根据具体的算法选择相应的server。
protected Server getServer(ILoadBalancer loadBalancer) { if (loadBalancer == null) { return null; } return loadBalancer.chooseServer("default"); // TODO: better handling of key }
loadBalancer是定义软件负载均衡器操作的接口,共有以下几个实现类
本文便从loadBalancer开始分析ribbon具体的负载均衡策略
首先看AbstractLoadBalancer 定义了几个基础的方法
public abstract class AbstractLoadBalancer implements ILoadBalancer { public enum ServerGroup{ //所有服务实例 ALL, //正常服务的实例 STATUS_UP, //停止服务的实例 STATUS_NOT_UP } /** * 选择具体的服务实例,key为null,忽略key的条件判断 */ public Server chooseServer() { return chooseServer(null); } /** * 定义了根据分组类型来获取不同的服务实例的列表。 */ public abstract List<Server> getServerList(ServerGroup serverGroup); /** * 定义了获取LoadBalancerStats对象的方法,LoadBalancerStats对象被用来存储负载均衡器中 * 各个服务实例当前的属性和统计信息。这些信息非常有用,我们可以利用这些信息来观察负载均衡 * 的运行情况,同时这些信息也是用来制定负载均衡策略的重要依据。 */ public abstract LoadBalancerStats getLoadBalancerStats(); }
再看BaseLoadBalancer
BaseLoadBalancer定义了两个数组分别用来缓存所有服务实例和正常服务实例
@Monitor(name = PREFIX + "AllServerList", type = DataSourceType.INFORMATIONAL) protected volatile List<Server> allServerList = Collections .synchronizedList(new ArrayList<Server>()); @Monitor(name = PREFIX + "UpServerList", type = DataSourceType.INFORMATIONAL) protected volatile List<Server> upServerList = Collections .synchronizedList(new ArrayList<Server>());
我们再看BaseLoadBalancer的构造方法
public BaseLoadBalancer() { this.name = DEFAULT_NAME; this.ping = null; setRule(DEFAULT_RULE); setupPingTask(); lbStats = new LoadBalancerStats(DEFAULT_NAME); }
设置默认的路由规则为 RoundRobinRule
private final static IRule DEFAULT_RULE = new RoundRobinRule();
启动定时任务,每隔10秒钟执行一次,检查检查服务实例是否正常服务。默认ping的策略是SerialPingStrategy,采用线性的遍历各个服务实例
private final static SerialPingStrategy DEFAULT_PING_STRATEGY = new SerialPingStrategy();
注意下面的提示,之所以采用SerialPingStrategy这种策略是因为下面的中ping是基于内存的变量获取,那么在真实环境多节点部署时,假如你有100个节点,你就要线性ping100次,采用这种ping策略耗时很长,所以建议生产环境实现IPingStrategy重写这个策略
private static class SerialPingStrategy implements IPingStrategy { @Override public boolean[] pingServers(IPing ping, Server[] servers) { int numCandidates = servers.length; boolean[] results = new boolean[numCandidates]; if (logger.isDebugEnabled()) { logger.debug("LoadBalancer: PingTask executing [" + numCandidates + "] servers configured"); } for (int i = 0; i < numCandidates; i++) { results[i] = false; /* Default answer is DEAD. */ try { // NOTE: IFF we were doing a real ping // assuming we had a large set of servers (say 15) // the logic below will run them serially // hence taking 15 times the amount of time it takes // to ping each server // A better method would be to put this in an executor // pool // But, at the time of this writing, we dont REALLY // use a Real Ping (its mostly in memory eureka call) // hence we can afford to simplify this design and run // this // serially if (ping != null) { results[i] = ping.isAlive(servers[i]); } } catch (Throwable t) { logger.error("Exception while pinging Server:" + servers[i], t); } } return results; } }
我们再看最为重要的 chooseServer,可以看到服务实例的选择由rule来实现。关于rule的分析,我们下面再谈
public Server chooseServer(Object key) { if (counter == null) { counter = createCounter(); } counter.increment(); if (rule == null) { return null; } else { try { return rule.choose(key); } catch (Throwable t) { return null; } } }
再看DynamicServerListLoadBalancer
DynamicServerListLoadBalancer实现了服务实例清单在运行期的动态更新能力;同时,它还具备了对服务实例清单的过滤功能
这里先介绍一个成员变变量 ServerList<T> serverListImpl, serverListImpl 是一个服务实例清单,初始化的时候回去所有服务,然后没个30秒定时的检查服务状态
ServerList有多个实现类,具体该使用那个主要由EurekaRibbonClientConfiguration配置类决定
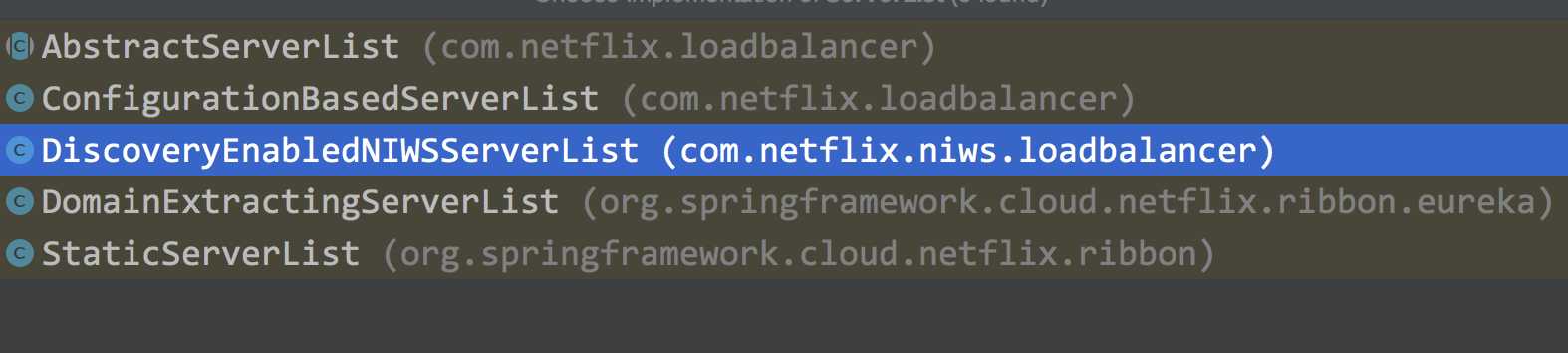
由配置类我们可以看出ServerList默认的实习类是DomainExtractingServerList
@Bean @ConditionalOnMissingBean public ServerList<?> ribbonServerList(IClientConfig config, Provider<EurekaClient> eurekaClientProvider) { if (this.propertiesFactory.isSet(ServerList.class, serviceId)) { return this.propertiesFactory.get(ServerList.class, config, serviceId); } DiscoveryEnabledNIWSServerList discoveryServerList = new DiscoveryEnabledNIWSServerList( config, eurekaClientProvider); DomainExtractingServerList serverList = new DomainExtractingServerList( discoveryServerList, config, this.approximateZoneFromHostname); return serverList; }
现在来看 ServerList是如何实现服务的获取和更新的。这里看 DomainExtractingServerList类两个方法。注意这里的 this.list 是由DiscoveryEnabledNIWSServerList 传进去,所以真正的代码在DiscoveryEnabledNIWSServerList中
@Override public List<DiscoveryEnabledServer> getInitialListOfServers() { List<DiscoveryEnabledServer> servers = setZones(this.list .getInitialListOfServers()); return servers; } @Override public List<DiscoveryEnabledServer> getUpdatedListOfServers() { List<DiscoveryEnabledServer> servers = setZones(this.list .getUpdatedListOfServers()); return servers; }
所以我们看下DiscoveryEnabledNIWSServerList

两个方法都调用 obtainServersViaDiscovery
private List<DiscoveryEnabledServer> obtainServersViaDiscovery() { List<DiscoveryEnabledServer> serverList = new ArrayList<DiscoveryEnabledServer>(); if (eurekaClientProvider == null || eurekaClientProvider.get() == null) { logger.warn("EurekaClient has not been initialized yet, returning an empty list"); return new ArrayList<DiscoveryEnabledServer>(); } EurekaClient eurekaClient = eurekaClientProvider.get(); if (vipAddresses!=null){ for (String vipAddress : vipAddresses.split(",")) { // if targetRegion is null, it will be interpreted as the same region of client List<InstanceInfo> listOfInstanceInfo = eurekaClient.getInstancesByVipAddress(vipAddress, isSecure, targetRegion); for (InstanceInfo ii : listOfInstanceInfo) { if (ii.getStatus().equals(InstanceStatus.UP)) { ....省略部分代码 DiscoveryEnabledServer des = new DiscoveryEnabledServer(ii, isSecure, shouldUseIpAddr); des.setZone(DiscoveryClient.getZone(ii)); serverList.add(des); } } if (serverList.size()>0 && prioritizeVipAddressBasedServers){ break; // if the current vipAddress has servers, we dont use subsequent vipAddress based servers } } } return serverList; }
这里的vipAddresses服务名,对这些服务名进行遍历,将状态为UP(正常服务)的实例转换成DiscoveryEnabledServer对象
![]()
现在我们已经知道了服务是怎么获取的了。但是 服务的定时更新策略我们还没提及。
这里我们看到 DynamicServerListLoadBalancer里的 ServerListUpdater
protected final ServerListUpdater.UpdateAction updateAction = new ServerListUpdater.UpdateAction() { @Override public void doUpdate() { updateListOfServers(); } };
这个ServerListUpdater同样是个接口,看下它的注释就知道这个接口定义不同的策略去定时的更新ServerList
/** * strategy for {@link com.netflix.loadbalancer.DynamicServerListLoadBalancer} to use for different ways * of doing dynamic server list updates. * * @author David Liu */
他有两个实现类

默认的的是PollingServerListUpdater

很容易就能发现他的定时策略
public synchronized void start(final UpdateAction updateAction) { if (isActive.compareAndSet(false, true)) { final Runnable wrapperRunnable = new Runnable() { @Override public void run() { try { updateAction.doUpdate(); lastUpdated = System.currentTimeMillis(); } catch (Exception e) { logger.warn("Failed one update cycle", e); } } }; scheduledFuture = getRefreshExecutor().scheduleWithFixedDelay( wrapperRunnable, initialDelayMs,//延迟1000ms触发 refreshIntervalMs,//每隔30 * 1000ms触发 TimeUnit.MILLISECONDS ); } else { logger.info("Already active, no-op"); } }
之前我们提到过DynamicServerListLoadBalancer具有动态过滤的功能,我们在DynamicServerListLoadBalancer找到了ServerListFilter 接口,该接口允许用配置或动态获取的具有所需特性的候选服务器列表进行过滤。
public interface ServerListFilter<T extends Server> { public List<T> getFilteredListOfServers(List<T> servers); }
com.netflix.loadbalancer.ZoneAffinityServerListFilter:该过滤器基于"区域感知(Zone Affinity)"的方式实现服务实例的过滤,也就说,它会根据提供服务的实例所处于的区域(Zone)与消费者自身所处区域(Zone)进行比较,过滤掉那些不是同处一个区域的实例public List<T> getFilteredListOfServers(List<T> servers) { if (zone != null && (zoneAffinity || zoneExclusive) && servers !=null && servers.size() > 0){ List<T> filteredServers = Lists.newArrayList(Iterables.filter( servers, this.zoneAffinityPredicate.getServerOnlyPredicate())); if (shouldEnableZoneAffinity(filteredServers)) { return filteredServers; } else if (zoneAffinity) { overrideCounter.increment(); } } return servers; }
这里的zoneAffinityPredicate是guava的函数式接口,真正的判断封装如下
private final String zone = ConfigurationManager.getDeploymentContext().getValue(ContextKey.zone);
public boolean apply(PredicateKey input) { Server s = input.getServer(); String az = s.getZone(); if (az != null && zone != null && az.toLowerCase().equals(zone.toLowerCase())) { return true; } else { return false; } }
com.netflix.niws.loadbalancer.DefaultNIWSServerListFilter:该过滤器完全继承自ZoneAffinityServerListFilter,是默认的NIWS(Netfilx Internal Web Service)过滤器。
com.netflix.loadbalancer.ServerListSubsetFilter:该过滤器也继承自ZoneAffinityServerListFilter,它非常适用于拥有大规模服务器集群(上百或者更多)的系统。因为它可以产生一个“区域感知”
0,配置参数为:<clientName>.<nameSpace>.ServerListSubsetFilter.eliminationConnectionThresold0,配置参数为:<clientName>.<nameSpace>.ServerListSubsetFilter.eliminationFailureThresold0.1(10%),配置参数为:<clientName>.<nameSpace>.ServerListSubsetFilter.forceEliminatePercent。那么就先对剩下的实例列表进行健康排序,再开始从最不健康实例进行剔除,直到达到配置的剔除百分比。20,其配置参数为:<clientName>.<nameSpace>.ServerListSubsetFilter.size。org.springframework.cloud.netflix.ribbon.ZonePreferenceServerListFilter: spring cloud整合时新增的过滤器,若使用Spring Cloud整合Eureka和Ribbon时会默认使用该过滤器,它实现了通过配置或者Eureka实例元数据的所属区域(Zone)来过滤同区域的服务实例,它的实现非常简单,首先通过ZoneAffinityServerListFilter的过滤器来获得"区域感知"的服务实例列表,然后遍历这个结果,取出根据消费者配置预设的区域Zone来进行过滤,如果过滤的结果是空就直接返回父类的结果,如果不为空就返回通过消费者的Zone过滤后的结果。@Override public List<Server> getFilteredListOfServers(List<Server> servers) { List<Server> output = super.getFilteredListOfServers(servers); if (this.zone != null && output.size() == servers.size()) { List<Server> local = new ArrayList<Server>(); for (Server server : output) { if (this.zone.equalsIgnoreCase(server.getZone())) { local.add(server); } } if (!local.isEmpty()) { return local; } } return output; }
ZoneAwareLoadBalancer
ZoneAwareLoadBalancer负载均衡器是对DynamicServerListLoadBalancer的扩展。在DynamicServerListLoadBalancer中,我们可以看到它并没有重写选择具体服务实例的chooseServer函数,所以它依然会采用在BaseLoadBalancer中实现的算法,使用RoundRobinRule规则,以线性轮询的方式来选择调用的服务实例,该算法实现简单并没有区域(Zone)的概念,所以它会把所有实例视为一个Zone下的节点来看待,这样就会周期性的产生跨区域(Zone)访问的情况,由于跨区域会产生更高的延迟,这些实例主要以防止区域性故障实现高可用为目的而不能作为常规访问的实例,所以在多区域部署的情况下会有一定的性能问题,而该负载均衡器则可以避免这样的问题。
我们先看ZoneAwareLoadBalancer是如何选择server实录的
public Server chooseServer(Object key) { if (!ENABLED.get() || getLoadBalancerStats().getAvailableZones().size() <= 1) { logger.debug("Zone aware logic disabled or there is only one zone"); return super.chooseServer(key); } Server server = null; //只有当负载均衡器中维护的实例所属的Zone区域的个数大于1的时候才会执行这里的策略 try { LoadBalancerStats lbStats = getLoadBalancerStats(); //调用ZoneAvoidanceRule.createSnapshot方法,当前的负载均衡器中所有的Zone区域分布创建快照,保存在Map zoneSnapshot中 Map<String, ZoneSnapshot> zoneSnapshot = ZoneAvoidanceRule.createSnapshot(lbStats); logger.debug("Zone snapshots: {}", zoneSnapshot); if (triggeringLoad == null) { triggeringLoad = DynamicPropertyFactory.getInstance().getDoubleProperty( "ZoneAwareNIWSDiscoveryLoadBalancer." + this.getName() + ".triggeringLoadPerServerThreshold", 0.2d); } if (triggeringBlackoutPercentage == null) { triggeringBlackoutPercentage = DynamicPropertyFactory.getInstance().getDoubleProperty( "ZoneAwareNIWSDiscoveryLoadBalancer." + this.getName() + ".avoidZoneWithBlackoutPercetage", 0.99999d); } //调用ZoneAvoidanceRule.getAvailableZones方法,来获取可用Zone区域集合,在该函数中会通过Zone区域快照的统计数据实现可用区的挑选。 Set<String> availableZones = ZoneAvoidanceRule.getAvailableZones(zoneSnapshot, triggeringLoad.get(), triggeringBlackoutPercentage.get()); logger.debug("Available zones: {}", availableZones); //当获得的可用Zone区域集合不为空,并且个数小于Zone区域总数,就随机选择一个Zone区域 if (availableZones != null && availableZones.size() < zoneSnapshot.keySet().size()) { String zone = ZoneAvoidanceRule.randomChooseZone(zoneSnapshot, availableZones); logger.debug("Zone chosen: {}", zone); if (zone != null) { //在确定了某个Zone区域后,则获取了对应Zone区域服务均衡器,并调用zoneLoadBalancer.chooseServer来选择具体的服务实例,而在 //zoneLoadBalancer.chooseServer中将使用IRule接口的choose函数来选择具体的服务实例,在这里,IRule接口的实现会使用ZoneAvoidanceRule来挑选具体的服务实例。 BaseLoadBalancer zoneLoadBalancer = getLoadBalancer(zone); server = zoneLoadBalancer.chooseServer(key); } } } catch (Throwable e) { logger.error("Unexpected exception when choosing server using zone aware logic", e); } if (server != null) { return server; } else { logger.debug("Zone avoidance logic is not invoked."); //否则实现父类的策略 return super.chooseServer(key); } }
以上我们便把几种loadbalnce介绍完毕,但是,在实际的选择server中,loadbalnce会交由rule实现
public Server chooseServer(Object key) { if (counter == null) { counter = createCounter(); } counter.increment(); if (rule == null) { return null; } else { try { return rule.choose(key); } catch (Throwable t) { return null; } } }
接下来,介绍下Rule
IRule是loadbalance选择服务的策略接口,IRule有多种实现,默认的rule采用轮训策略
private final static IRule DEFAULT_RULE = new RoundRobinRule();
| 策略名 | 策略声明 | 策略描述 | 实现说明 |
| BestAvailableRule | public class BestAvailableRule extends ClientConfigEnabledRoundRobinRule | 选择一个最小的并发请求的server | 逐个考察Server,如果Server被tripped了,则忽略,在选择其中ActiveRequestsCount最小的server |
| AvailabilityFilteringRule | public class AvailabilityFilteringRule extends PredicateBasedRule | 过滤掉那些因为一直连接失败的被标记为circuit tripped的后端server,并过滤掉那些高并发的的后端server(active connections 超过配置的阈值) | 使用一个AvailabilityPredicate来包含过滤server的逻辑,其实就就是检查status里记录的各个server的运行状态 |
| WeightedResponseTimeRule | public class WeightedResponseTimeRule extends RoundRobinRule | 根据响应时间分配一个weight,响应时间越长,weight越小,被选中的可能性越低。 | 一个后台线程定期的从status里面读取评价响应时间,为每个server计算一个weight。Weight的计算也比较简单responsetime 减去每个server自己平均的responsetime是server的权重。当刚开始运行,没有形成status时,使用roubine策略选择server。 |
| RetryRule | public class RetryRule extends AbstractLoadBalancerRule | 对选定的负载均衡策略机上重试机制。 | 在一个配置时间段内当选择server不成功,则一直尝试使用subRule的方式选择一个可用的server |
| RoundRobinRule | public class RoundRobinRule extends AbstractLoadBalancerRule | roundRobin方式轮询选择server | 轮询index,选择index对应位置的server |
| RandomRule | public class RandomRule extends AbstractLoadBalancerRule | 随机选择一个server | 在index上随机,选择index对应位置的server |
| ZoneAvoidanceRule | public class ZoneAvoidanceRule extends PredicateBasedRule | 复合判断server所在区域的性能和server的可用性选择server | 使用ZoneAvoidancePredicate和AvailabilityPredicate来判断是否选择某个server,前一个判断判定一个zone的运行性能是否可用,剔除不可用的zone(的所有server),AvailabilityPredicate用于过滤掉连接数过多的Server。 |
以上是系统提供的rule,如果你觉得这些还不能满足的的需求。我们可以自定义Rule,步骤如下
serviceName.ribbon.NFLoadBalancerRuleClassName=com.netflix.loadbalancer.MyRule
将rule交给容器管理
@Bean public IRule ribbonRule() { return new MyRule();//这里配置策略,和配置文件对应 }
https://www.jianshu.com/p/1c02c1f8c0ff 【Spring Cloud源码分析(二)Ribbon】
标签:并且 diff out 存在 wss span cloud 消费者 except
原文地址:https://www.cnblogs.com/xmzJava/p/9590727.html