标签:网站 传输速率 分享 框架 就是 www mysq mongod 硬盘
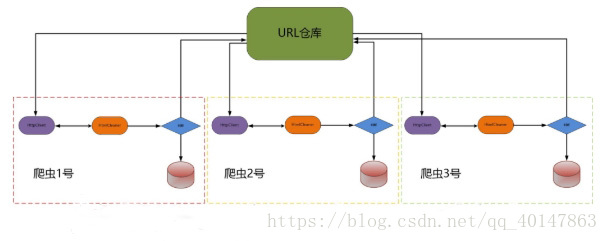
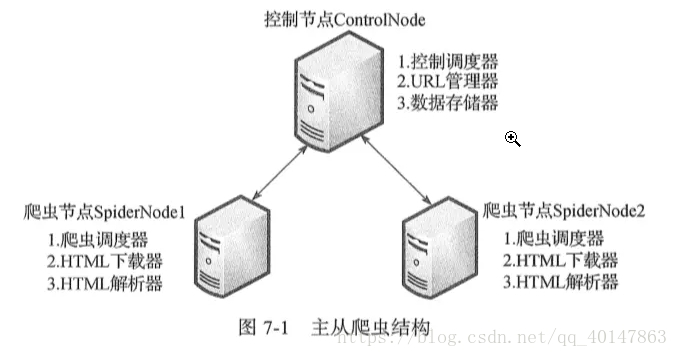
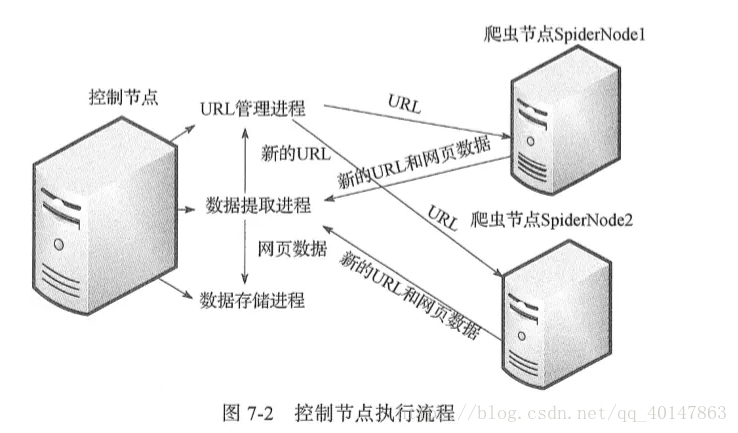
分布式爬虫在实际应用中还算是多的,本篇简单介绍一下分布式爬虫
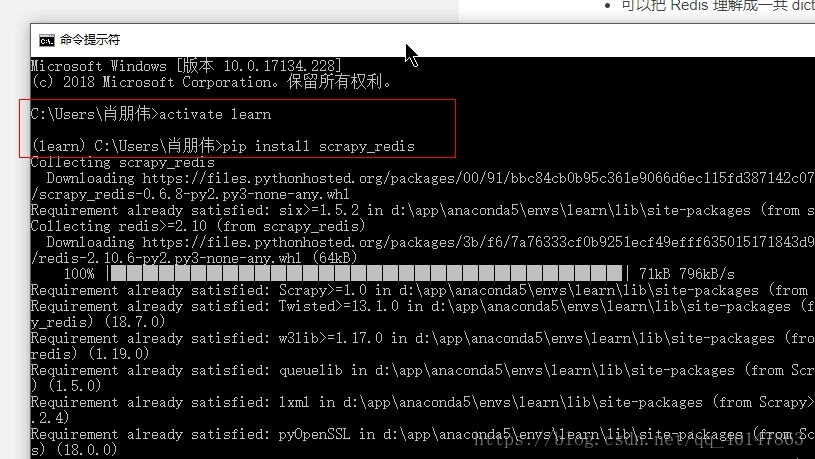
4.操作截图
Python爬虫教程-34-分布式爬虫介绍
原文地址:https://www.cnblogs.com/xpwi/p/9601064.html