标签:表的操作 种类型 种类 alt 插入 文件 数据 完整 redo log
最近去听了公司DBA对MySQL InnoDB引擎分享,作为一枚程序员要深入理解InnoDB引擎的原理还是需要很多经验才能掌握的,但起码我们需要对开发需要用到的内容能做到掌握,并且在原理方面的理解需要有一个大体轮廓,以备不时之需。下面是我对分享听下来存在的二个疑惑,回来之后查阅相关知识,便有了这篇随笔。
我们知道Innodb高并发特色就是支持行级锁这个东西,相对于表锁,行级锁通过把锁范围减少,从而提高了访问数据库的并发性能,这其实和我们写java局部代码加锁性能比加方法锁性能高是一样的道理。当数据库引擎同时支持行锁和表锁的时候,会存在冲突,所以就有了意向锁这个东西。
举个例子:事务1对表A对某行记录加了个排它锁(行锁),进行写操作,这个时候事务2也需要对表A加个表级的排它锁。这个时候能给事务2加锁成功吗?答案当然是不能,如果事务2加锁成功意味着它能修改事务1加了行锁的记录,这明显就是违背了行级锁的意义了。
那需要解决的问题就是事务2要加表锁的时候,如何知道该不该给它加锁成功?总不能一行行遍历,如果发现有冲突的行级锁的就阻塞此次加锁行为吧?于是意向锁就被想出来了,它是InnoDB自动帮我们加的,不需要我们维护。意向锁也是个表锁,也分为共享锁和排他锁,有个意向锁之后就可以解决上面提到的问题了。
还是这个例子,我们看下InnoDB怎么帮我们自动加意向锁的。当事务1对需要对表A某行加个排它锁时候,InnoDB首先会为事务1给表A加个意向排它锁,获取意向排他锁成功,才能对行加排它锁。这里我们假设下事务1成功获取到了意向排它锁,从而成功对表A某行加了排它锁,进行写操作,这个时候事务2来了,它要对表A加个排它锁,这个时候它发现表A已经加上了意向排它锁了,于是事务2对表A进行加表锁请求会失败的,阻塞直到事务1完成为止。这就解决了我们上面说的问题了,并且行锁和表锁可以有序共存。
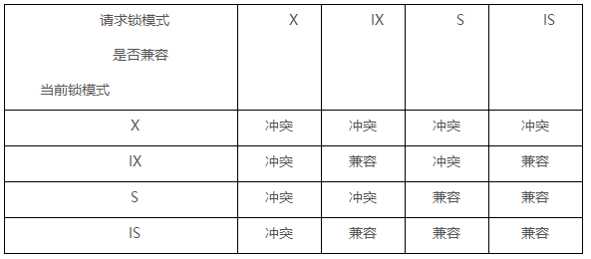
通过上面的例子,我们再结合下面这张图去理解下共享锁、排它锁、意向共享锁和意向排他锁的关系就清晰了。需要说明的事意向锁都是表锁,而共享锁和排它锁在行锁或者表锁都存在这2种类型。有个这张图再来解释上面例子里事务2想要获取表锁X,当前锁模式是IX,是不兼容了,所以就获取失败了,一目了然。
第二个疑惑是为何InnoDB需要有double write这个东西?开始我事这么想的,数据库恢复流程我们先不深究啊,这里假设事务提交了,redo log也写回到磁盘,那么当数据写回磁盘数据库page时,发生突然宕机重启后对数据库page进行一致性检查,如果发现有问题,那么通过redo log不就能解决修复page数据了吗?
通过查阅资料发现其实redo log不能修复数据是因为有2个原因,第一个原因是InnoDB对redo log设计问题导致,第二个原因数据库默认page大小与文件系统page大小存在差异,MySQL默认数据页大小是16K,而我们通常文件系统数据页大小是4K。正是由于这二个原因导致了仅仅依靠redo log在某些情况下是不能把有问题的page修复的。
我们先做第一个假设,一步步说明问题。假设数据库page size和文件系统一致,都是4K。那么数据库从内存中写回1个page到磁盘时,发生宕机,这1个page要么写回成功,要么写回不成功,如果不成功,重启的时候通过redo log,重写一次就可以了。当现在的问题是数据库page size是16K,也就是说我写1个page到磁盘,需要4次IO操作,假如我前2次IO操作成功,而后2次IO操作突然宕机,那么这个page在磁盘里就出现数据不一致了,如下图所示。
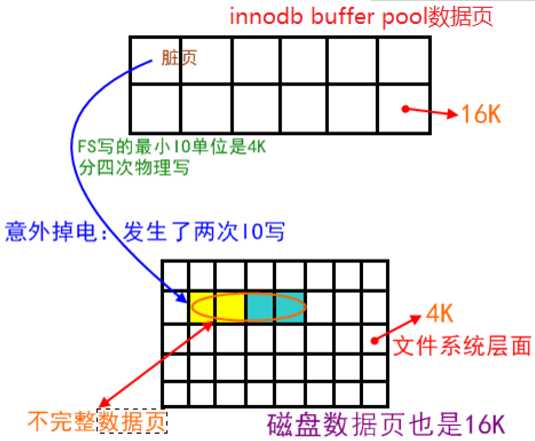
这里又引出了由于redo log设计上造成不能对损害数据page进行修复的原因了。理想情况当机器重启的时候回对数据库page进行检查,当检查到这1块page是损害的,如果redo log记录的是该page完完整整的数据,那直接对该page重做即可,尴尬的是redo log记录的并不是完整数据日志,而是逻辑日志,也就是说它记录的是该page的操作记录,例如插入了一行记录A,更新了一行记录B,现在这个数据page又是损害的,那么它就无能为力了!至于redo log为什么要设计成这个样子,当然是有他的原因的,其中一个原因就是为了节省空间。
关于日志格式类型简单做个摘抄,有兴趣的同学移步到后面我们补充的参考链接或者自行了解,它分为三种。
第一种,物理的日志(Physical Log),这种会完整记录page数据,优点就是在数据恢复的时候能完全恢复,缺点就是占用空间。
第二种,逻辑的日志(Logical Log),这种大家也是很好理解的,它记录的表的操作记录,优点可读性强、占用空间小,缺点显然易见,在数据恢复能力上比较弱。
第三组,物理和逻辑结合的日志(Physiological Log)。前2种的优点结合,它记录的是page的操作记录,而不是表的操作记录,这样的话可读性强和占用空间小的优点还是有的,同时在数据恢复的时候,只要page没有被损害的情况下都能恢复,redo log就是采用这种设计方式,所以在page损害情况下由于不是记录完整数据,也是无能为力的。
于是乎InnoDB就设计了double write这一招出来了。明白前后因果关系后,理解double write就比较简单了。对于一个已经提交的事务,它的redo log是OK的,那么当需要把数据从内存写回到数据库磁盘的时候,我先把这部分page写到一个地方(共享表空间),然后再把这部分page写到数据库磁盘,如果期间宕机了,没关系。重启的时候数据库依旧对每个page进行检查,如果page是完整的,对比redo log,看下谁的数据是最新的,假如是redo log是最新的,直接用重做redo log就好了,如果page是损害的,共享表空间肯定有该page完整数据page,因为数据库是先往共享表空间写完数据后,才对数据库磁盘里面表空间写数据的,直接用共享表空间数据覆盖即可。
至此,随笔完成了。实际上数据的一些加锁和恢复机制肯定是非常复杂的,坦诚没有过多深入的了解,随笔只是按照个人理解和相关资料整理而来,旨在能用文字记录下一些东西,如有不严谨的地方望指教。
四、参考资料
http://www.uml.org.cn/sjjm/201205222.asp MySQL数据库InnoDB存储引擎Log漫游
https://blog.csdn.net/renfengjun/article/details/41541809 我理解的MySQL Double Write
标签:表的操作 种类型 种类 alt 插入 文件 数据 完整 redo log
原文地址:https://www.cnblogs.com/yipaihushuo/p/9612278.html