标签:指定表 limit 聚集 amp 数据 协议 cut 大写 sch
1mysql登录
mysql客户端程序: 交互式模式和命令模式两种
mysql命令
常用选项:
--host=host_name, -h host_name:服务端地址;
--user=user_name, -u user_name:用户名;
--password[=password], -p[password]:用户密码;
--port=port_num, -P port_num:服务端端口;
--protocol={TCP|SOCKET|PIPE|MEMORY} 协议
本地通信:
--socket=path, -S path
--database=db_name, -D db_name: 设默认库的
--compress, -C:数据压缩传输
--execute=statement, -e statement:非交互模式执行SQL语句;

登入mysql后进行查询

参数有两种,一种是全局GLOBAL 一种会话session
session会话是临时的,只对当前会话有效 且是立即生效的
GLOBAL 是全局的对以后新建了的会话生效 值得修改要求用户有管理权限
用set进行修改参数:
SER [SESSION|GLOBAL] system_var_name = expr
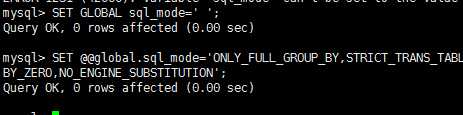
mysql的状态变量:
show [GLOBAL|SESSION] status [LIKE | WHERE]
mysql的数据类型:
字符型:
char(#) , binary(#):定长型 ; CHAR不区分字符大小写,而BINARY区分;
VARCHAR(#), VARBINARY(#):变长型
TEXT:TINYTEXT,TEXT,MEDIUMTEXT,LONGTEXT
BLOB:TINYBLOB,BLOB,MEDIUMBLOB, LONGBLOB
数值型:
浮点型:近似
float , double , real , bit
整型:精确
日期时间型:
日期:DATE
时间:TIME
日期j时间:DATETIME
时间戳:TIMESTAMP
年份:YEAR(2), YEAR(4)
内建类型:
ENUM:枚举
SET:集合
类型修饰符:
SHOW CHARACTER SET; 查看字符集
字符型:NOT NULL,NULL,DEFALUT ‘STRING’,CHARACET SET ‘CHARSET’,COLLATION ‘collocation‘
整型:NOT NULL, NULL, DEFALUT value, AUTO_INCREMENT, UNSIGNED
日期时间型:NOT NULL, NULL, DEFAULT
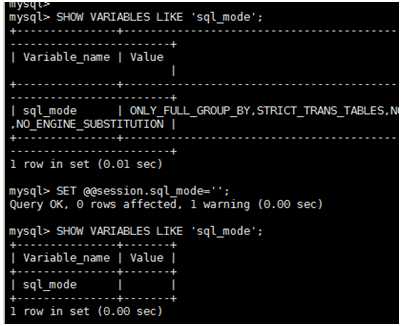
SQL MODE:定义mysqld对约束等违反时的响应行为等设定;
常用的MODE: (可以来管控mysql行为的)当发生错误行为时这么办
TRADITIONAL
STRICT_TRANS_TABLES
STRICT_ALL_TABLES
SHOW VARIABLES LIKE ‘sql_mode’ 查看sql模型
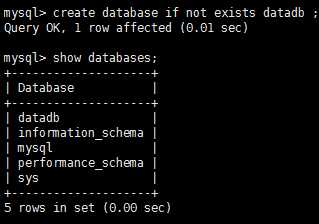
数据库:创建,修改,删除
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name CHARACTER SET [=] charset_name COLLATE [=] collation_name
查看当前使用的数据库
mysql> select database();
查看数据库使用端口
mysql> show variables like ‘port‘;
查看数据库编码
mysql> show variables like ‘character%‘;
更改:
ALTER {DATABASE | SCHEMA} [db_name] CHARACTER SET [=] charset_name COLLATE [=] collation_name
删除:
DROP {DATABASE | SCHEMA} [IF EXISTS] db_name
表的创建,
CREATE TABLE [IF NOT EXISTS] tble_name (col_name data_typ|INDEX|CONSTRAINT);
mysql> create table mydata (id int not null,name char(5) );
mysql> show tablese; 查看数据库下表
mysql> desc mydata; 查看表结构
查看支持的所有存储引擎:
mysql> SHOW ENGINES;
查看指定表的状态信息
mysql> show table status like ‘mydata‘\G;
删除:
DROP [TEMPORARY] TABLE [IF EXISTS] tbl_name [, tbl_name];
修改:
ALTER TABLE tbl_name[alter_specification [, alter_specification] ...]
可修改内容:
修改表:
索引:
创建
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name [index_type] ON tbl_name (index_col_name,...)
查看 可以同时查多个表
SHOW {INDEX | INDEXES | KEYS} {FROM | IN} tbl_name [{FROM | IN} db_name] [WHERE expr]
mysql> show index from mydata\G;
删除:
mysql> drop index mydex on mydata;
索引类型:
聚集索引、非聚集索引:索引是否与数据存在一起;
主键索引、辅助索引
稠密索引、稀疏索引:是否索引了每一个数据项;
视图:VIEW
虚表:存储下来的SELECT语句;
创建:
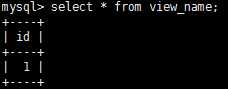
CREATE VIEW view_name [(column_list)] AS select_statement
mysql> create view view_name as select id from mydata;
修改
ALTER VIEW view_name [(column_list)] AS select_statement
删除:
DROP VIEW [IF EXISTS] view_name [, view_name] ...
select查询:查询执行路径:
请求-->查询缓存-->解析器-->预处理器-->优化器-->查询执行引擎-->存储引擎-->缓存-->响应
FROM --> WHERE --> Group By --> Having --> Order BY --> SELECT --> Limit
单表查询:
SELECT col1, col2, ... FROM tble_name; 极其危险,慎用;
SELECT col1, col2, ... FROM tble_name WHERE clause; 条件查询
SELECT col1, col2, ... FROM tble_name [WHERE clause] GROUP BY col_name [HAVING clause]; 分组
DISTINCT:数据去重;
SQL_CACHE:显式指定缓存查询语句的结果;
SQL_NO_CACHE:显式指定不缓存查询语句的结果;
query_cache_type服务器变量有三个值:
ON:启用;
SQL_NO_CACHE:不缓存;默认符合缓存条件都缓存;
OFF:关闭;
DEMAND:按需缓存;
SQL_CACHE:缓存;默认不缓存
字段可以使用别名 :
col1 AS alias1, col2 AS alias2, ...
WHERE子句:指明过滤条件以实现“选择”功能;
过滤条件:布尔型表达式;
算术操作符:+, -, *, /, %
比较操作符:=, <>, !=, <=>, >, >=, <, <=
IS NULL, IS NOT NULL
区间:BETWEEN min AND max
IN:列表;
LIKE:模糊比较,%和_;
RLIKE或REGEXP
逻辑操作符:
AND, OR, NOT
GROUP BY:根据指定的字段把查询的结果进行“分组”以用于“聚合”运算;
avg(), max(), min(), sum(), count()
HAVING:对分组聚合后的结果进行条件过滤;
ORDER BY:根据指定的字段把查询的结果进行排序;
升序:ASC
降序:DESC
LIMIT:对输出结果进行数量限制
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
第三节多表查询与子查询
多表查询:
连接操作:
交叉连接:笛卡尔乘积;
内连接:
等值连接:让表之间的字段以等值的方式建立连接;
不等值连接:
自然连接
自连接:自己跟自己连接
外连接:
左外连接:
FROM tb1 LEFT JOIN tb2 ON tb1.col = tb2.col
右外连接:
FROM tb1 RIGHT JOIN tb2 ON tb1.col = tb2.col
如多表等值查询


自连接:
外链接:
左外连接:FROM tb1 LEFT JOIN tb2 ON tb1.col = tb2.col
右外连接:FROM tb1 RIGHT JOIN tb2 ON tb1.col = tb2.col
子查询:在查询中嵌套查询;
在查询中且套查询:
SELECT * FROM (SELECT * FROM students where age > 20) AS S WHERE S.Gender=’M’;
用于WHERE子句中的子查询;
(1) 用于比较表达式中的子查询:子查询仅能返回单个值;
(2) 用于IN中的子查询:子查询可以返回一个列表值;
SELECT * FROM STUDENTS WHERE ClassID IN (SELECT DISTINCT ClassID FROM students WHERE Gender = ‘F’) AND Gender=‘M’;
(3) 用于EXISTS中的子查询
用于FROM子句中的子查询;
SELECT tb_alias.col1, ... FROM (SELECT clause) AS tb_alias WHERE clause;
联合查询:将多个查询语句的执行结果相合并;
UNION:
SELECT clause UNION SELECT cluase;
SELECT Name,Age FROM teacher UNION SELECT Name,Age FROM students;
练习:导入hellodb.sql生成数据库
(1) 在students表中,查询年龄大于25岁,且为男性的同学的名字和年龄;
SELECT Name,Age FROM students WHERE Age > 25 AND Gender=‘M‘;
(2) 以ClassID为分组依据,显示每组的平均年龄;
SELECT ClassID,avg(age) FROM students GROUP BY ClassID;
(3) 显示第2题中平均年龄大于30的分组及平均年龄;
SELECT ClassID,avg(age) AS Aging FROM students GROUP BY ClassID HAVING Aging>30;
(4) 显示以L开头的名字的同学的信息;
SELECT * FROM students WHERE Name LIKE ‘L%‘;
(5) 显示TeacherID非空的同学的相关信息;
SELECT * FROM students WHERE TeacherID IS NOT NULL;
(6) 以年龄排序后,显示年龄最大的前10位同学的信息;
SELECT * FROM students ORDER BY Age DESC LIMIT 10;
1、以ClassID分组,显示每班的同学的人数;
SELECT ClassID,count(StuID) FROM students GROUP BY ClassID;
2、以Gender分组,显示其年龄之和;
SELECT Gender,SUM(Age) FROM students GROUP BY Gender;
3、以ClassID分组,显示其平均年龄大于25的班级;
SELECT ClassID,avg(age) FROM students GROUP BY ClassID HAVING avg(Age) > 25;
标签:指定表 limit 聚集 amp 数据 协议 cut 大写 sch
原文地址:https://www.cnblogs.com/huxl1/p/9612899.html