标签:最大的 knn k近邻 label div 返回 src att 个数
KNN算法是机器学习最简单的算法,可以认为是没有模型的算法,也可以认为数据集就是它的模型。
它的原理非常简单:首先计算预测的点与所有的点的距离,然后从小到大排序取前K个最小的距离对应的点,统计前K个点对应的label的个数,取个数最大的labekl作为预测值
代码样例如下:
首先导入需要的numpy库和matplotlib库
1 import numpy as np 2 import matplotlib.pyplot as plt
创建自己的数据集
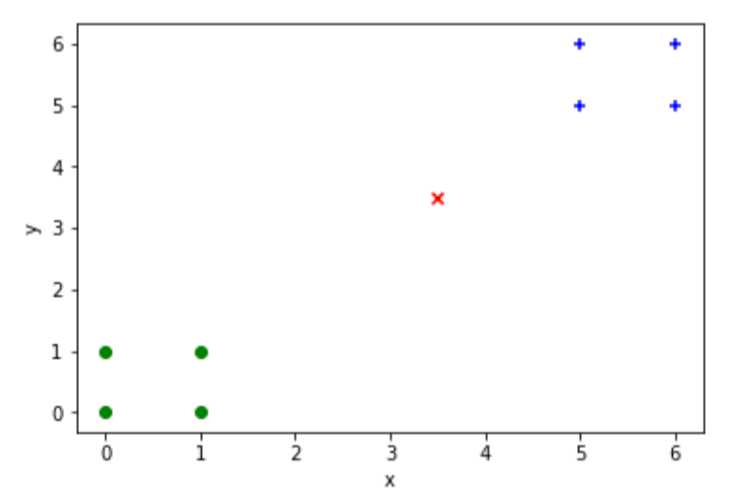
1 data_X = [[0,0],[0,1],[1,0],[1,1],[5,5],[5,6],[6,5],[6,6]] 2 data_y = [0,0,0,0,1,1,1,1]
将数据集转换成numpy.array格式便于处理
1 X_train = np.array(data_x) 2 y_train = np.array(data_y)
创建预测的点
1 x_test = np.array([3.5,3.5])
画出数据散点图
plt.scatter(x_train[y_train==0,0],X_train[y_train==0,1],color=‘g‘,marker=‘o‘) plt.scatter(x_train[y_train==1,0],X_train[y_train==1,1],color=‘b‘,marker=‘+‘) plt.scatter(x_test[0],x_test[1],color=‘r‘,marker=‘x‘) plt.xlabel(‘x‘) plt.ylabel(‘y‘) plt.show()
计算欧式距离
1 distances = [np.sqrt(np.sum((x_test-x_train)**2)) for x_train in X_train ]
把距离从小到大排序,并返回索引值
1 nearest = np.argsort(distances)
返回前k(k=4)个距离最近的点对应的类别
1 k = 4 2 topK_y = [y_train[i] for i in nearest[:k]]
计算k个距离最近的点对应的label的个数
1 from collections import Counter 2 votes = Counter(topK_y)
返回数量最多的label作为预测值
1 predict_y = votes.most_common(1)[0][0]
k-Nearest Neighbors(KNN) k近邻算法
标签:最大的 knn k近邻 label div 返回 src att 个数
原文地址:https://www.cnblogs.com/wf-ml/p/9614199.html