标签:-- ntb 元素对象 smart 注意 好处 联合 size child
跟你说,你总是靠那个firebug,chrome的F12啥的右击复制xpath绝对总有一天踩着地雷炸的你死活定位不到,这个时候就需要自己学会动手写xpath,人脑总比电脑聪明,开始把xpath语法给我学起来!
第1种方法:通过绝对路径做定位(相信大家不会使用这种方式)
By.xpath("html/body/div/form/input")
By.xpath("//input")
第2种方法:通过元素索引定位
By.xpath("//input[4]")
第3种方法:使用xpath属性定位
By.xpath("//input[@id=‘kw1‘]")
By.xpath("//input[@type=‘name‘ and @name=‘kw1‘]")
第4种方法:使用部分属性值匹配(最强大的方法)
By.xpath("//input[starts-with(@id,‘nice‘)
By.xpath("//input[ends-with(@id,‘很漂亮‘)
By.xpath("//input[contains(@id,‘那么美‘)]")
【说明】
starts-with 顾名思义,匹配一个属性开始位置的关键字。
contains 匹配一个属性值中包含的字符串。
text() 匹配的是显示文本信息,此处也可以用来做定位用。
【举例】
//input[starts-with(@name,‘name1‘)] 查找name属性中开始位置包含‘name1‘关键字的页面元素
//input[contains(@name,‘na‘)] 查找name属性中包含na关键字的页面元素
<a href="http://www.baidu.com">百度搜索</a>,那么xpath写法为 //a[text()=‘百度搜索‘] 或者 //a[contains(text(),"百度搜索")]
【第二部分】我一位同事在使用selenium定位的时候踩到的坑
上次我有一个同事,定位元素的时候,用火狐浏览器firebug工具,定位到这个HTML代码:
<span onlick="88_da_33_699999_x64_3.01.3730.spkg" name="delete" /> 大约是这样,死活定位不到,然后用到了xpath属性的并列关系,and关键字,才定位的到。
//*[contains(@onclick, ‘x64_3.01.3730.spkg‘) and @name=‘delete‘]
【第三部分】切换iframe时遇到的几个鬼
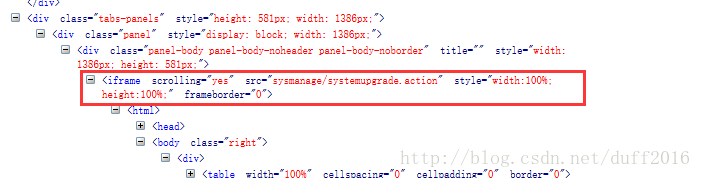
(1)在切换ifame的时候,有时iframe是含有id的,就可以直接定位使用,但是当iframe没有id信息的时候,如下图,
当然实际情况中会遇到没有id属性和name属性为空的情况,这时候就需要先定位iframe元素对象,这里可以通过tag先定位到,也能达到同样效果。
如下代码:
iframe = driver.find_element_by_tag_name("iframe")
driver.switch_to_frame(iframe)
切换完了之后,就可以去正常定位iframe里面的元素,driver.find_element_by_tagname(table) 之类的,同时也可以用xpath的方式:例如 Xpath=//*[contains(@src, ‘sysmanage/systemupgrade.action‘)] 之类的。
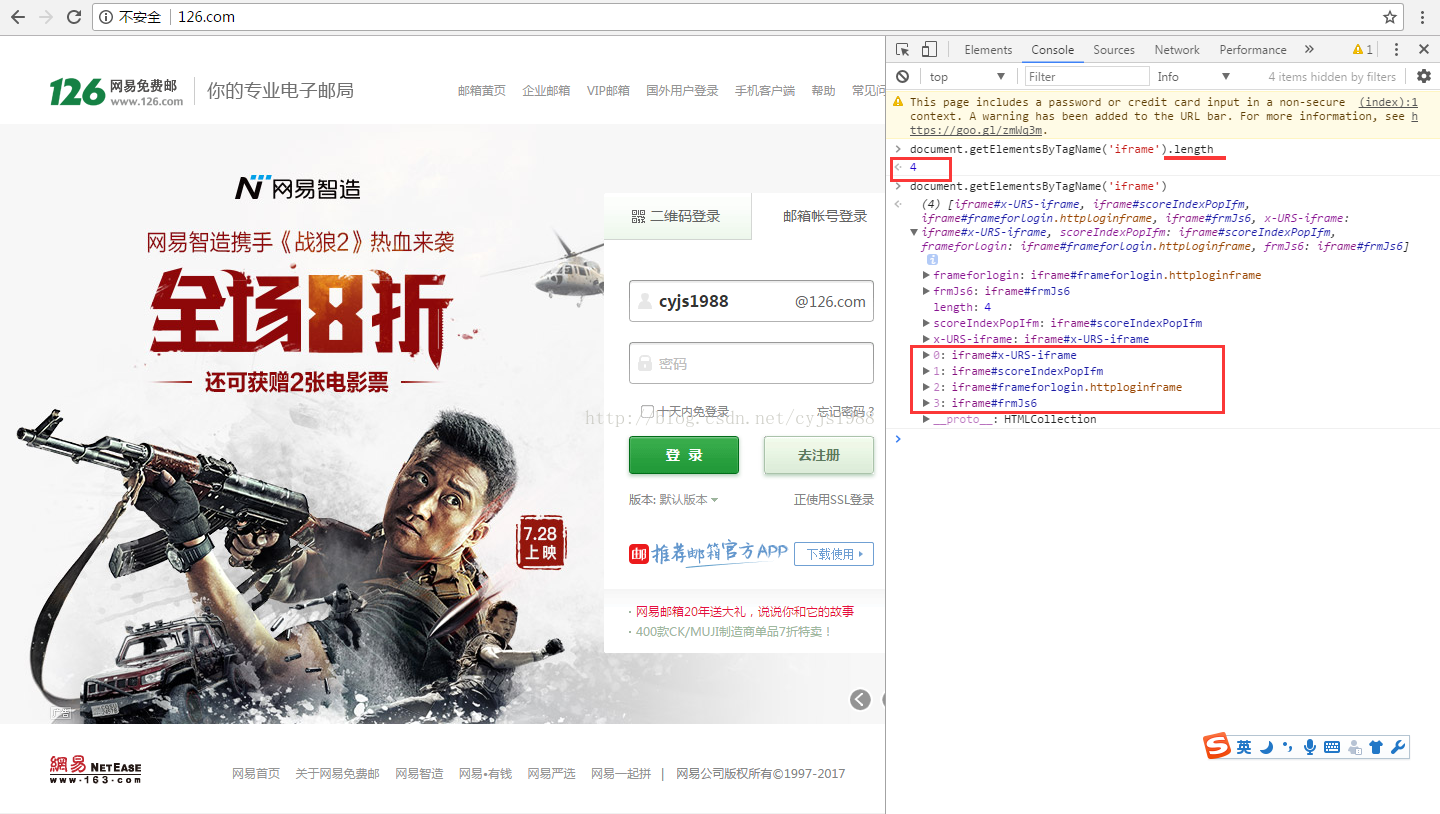
(2)如果有多个(层级)iframe标签,那你就要看看总共有iframe标签了,看看你所定位的iframe是数组中的第几个iframe元素(从0开始数起,基于JavaScript的),可以用chrome浏览器的F12的控制台(Console)就可以输入document.getElementsByTagName(‘iframe‘).length这句代码,即可打印出iframe的长度(也就是个数),然后按照从0开始数起。
【下面这张图片可能有点大,看不到最右边的Console,右击图片->新窗口打开】
(3)当iframe上的操作完后,想重新回到主页面上操作元素,这时候,就可以用switch_to_default_content()方法返回到主页面。
如下代码:
iframe = driver.find_element_by_tag_name("iframe")
driver.switch_to_frame(iframe)
switch_to_default_content()
(4)如何判断元素是否在iframe上?
1.定位到元素后,切换到firepath界面。
2.看firebug工具左上角,如果显示Top Window说明没有iframe。
3.如果显示iframe#xxx这样的,说明在iframe上,#后面就是它的id。
【第四部分】selenium用javascript定位
因为selenium的内核引擎就是用JavaScript来驱动的,所以只要selenium自带的那些原始辣鸡方法出现定位不了的、点击不了的并发症一旦发作,就可以使用JavaScript大绝招,除了JavaScript,还有jQuery大绝招,一个个来,你阵亡了,他来替补,滔滔江水永不休。
一、以下总结了5种js定位的方法
除了id是定位到的是单个element元素对象,其它的都是elements返回的是list对象
1.通过id获取
document.getElementById(“id”)
2.通过name获取
document.getElementsByName(“Name”)
返回的是list
3.通过标签名选取元素
document.getElementsByTagName(“tag”)
4.通过CLASS类选取元素
document.getElementsByClassName(“class”)
兼容性:IE8及其以下版本的浏览器未实现getElementsByClassName方法
5.通过CSS选择器选取元素
document.querySelectorAll(“css selector")
兼容性:IE8及其以下版本的浏览器只支持CSS2标准的选择器语法
【举例代码】
js = ‘document.getElementById("helloId").click();‘
driver.execute_script(js)
js1 = ‘document.getElementsByClassName("helloName")[0].value = "王大明";‘ //整个HTML文档里第一个使用CSS样式类的class="helloName"属性,它的value属性的值设置为“王大明”
driver.execute_script(js1)
【第五部分】selenium用jquery定位【简直逆天,老天爷都惊呆了,眼睛瞪的滚圆】
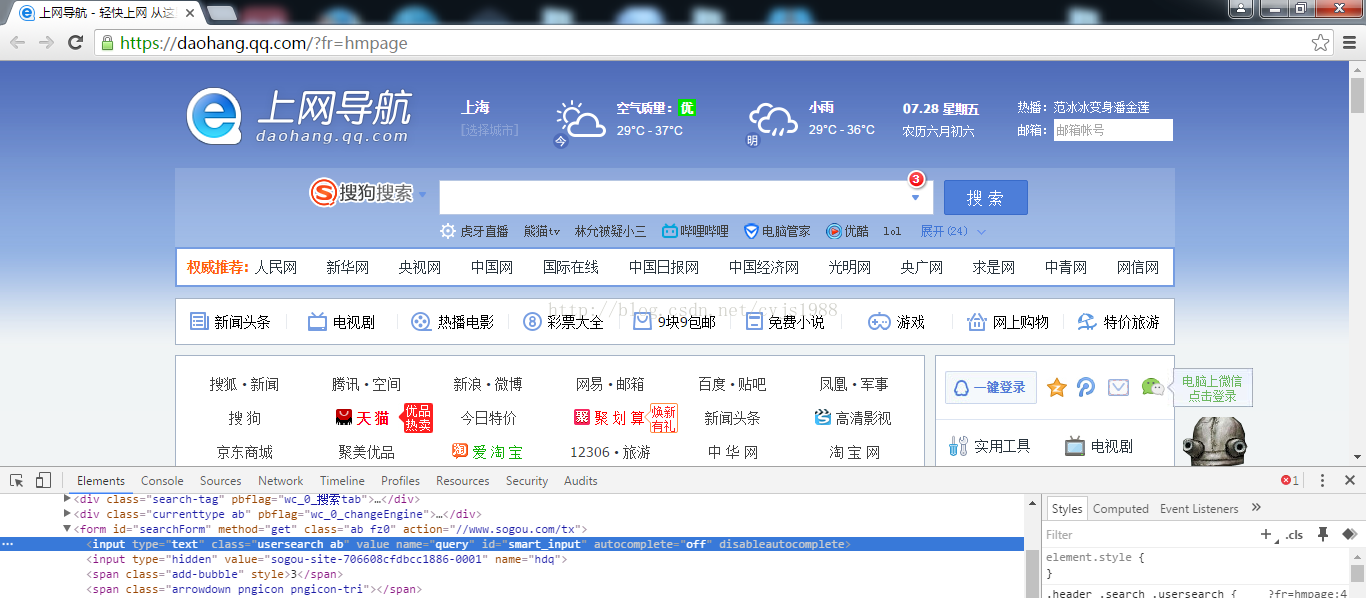
JQuery是2006年1月诞生的一个基于封装JavaScript的框架,你经常看到的美元符号带上一个圆括号$(‘XXX‘),其实就是document.getElementBy什么什么的这个js方法,至于XXX前面带.的话,就是document.getElementByClass,带#的话,就是document.getElementById。
【看不清图,右键新窗口打开图片】
1.Id
inputTest="$(‘#smart_input‘).val(‘帅气的我还能再削‘)"
driver.execute_script(inputTest)
2.Class
inputTest="$(‘.usersearch‘).val(‘帅气的我还能再削‘)"
3. Type
inputTest="$(‘:text‘).val(‘帅气的我还能再削‘)"
4. 层级
inputTest="$(‘#searchForm>#smart_input‘).val(‘帅气的我还能再削‘)"
inputTest="$(‘#searchForm #smart_input ‘).val(‘帅气的我还能再削‘)" 【注意两个id选择器“#searchForm #smart_input”中间是一个空格】
inputTest="$(‘#searchForm>input:first‘).val(‘帅气的我还能再削‘)"
选择最后一个input元素:
clickbutton="$(‘#searchForm>input:last‘).click()"
选择第几个input元素
inputTest="$(‘#searchForm>input:eq(0)‘).val(‘帅气的我还能再削‘)" 从0开始算第一个
inputTest="$(‘#searchForm>input:nth-child(1)‘).val(‘帅气的我还能再削‘)" 当然也可以这样,nth-child从1开始算第一个
知识链接:
1、nth-child(N):下标从1开始;eq(N):下标从0开始;
2、nth-child(N):选择多个元素;eq(N):选择一个元素。
5. 其他
#inputTest="$(‘input[name=query]‘).val(‘帅气的我还能再削‘)"
inputTest="$(‘input[id=smart_input]‘).val(‘帅气的我还能再削‘)"
-------------------------------------------------------------------------------------------------------------------------------
【附录1】xpath的语法使用基础
Xpath的使用方法:
例子 1:html/body/div[1]/div[2] (如果不熟悉html的朋友们,需要自行百度html。)
该xpath 表示 : 在 html标签下 -> body标签下 -> 第一个div标签下 -> 第二个div标签
很好理解,继续
例子 2:.//*[@id=‘content‘]/div[2]/ul
这样会有人不理解了 .//*[@id=‘content‘] 到底是什么意思呢?
. 代表当前路径
a//b 表示:在a标签下的子孙辈b标签
* 可以是任何标签
[@id=‘content‘] 表示是 id 为 content
所以:这个例子的意思是: id 为 content 的任何子标签下面 -> 第二个 div标签下 -> ul 标签
Xpath基础学习完毕,接下来开始进阶学习
//p[text()=‘a‘] :文本为 a 的p标签
//p[text()=‘a‘] : 文本包含 a 的p标签
//a[@class=‘abc‘] :class 为 a的 p标签 (当然咯。既然可以为 @class 就一定能用 @id ,为什么不联想下 @src 和@href呢?)
//p[not(@class=‘a‘)] :class 不为 a的 p标签
好了,进阶完毕,如果要使用更高阶的Xpath要先属性以上内容,然后联合 Selenium使用
Xpath和其他定位方式的比较:(主要是和CSS定位的对比)
Xpath的最大好处是能向上查找,不过缺点是速度过慢。
【附录2】CSS定位语法基础
selenium使用Xpath+CSS+JavaScript+jQuery的定位方法(治疗selenium各种定位不到,点击不了的并发症)
标签:-- ntb 元素对象 smart 注意 好处 联合 size child
原文地址:https://www.cnblogs.com/xuzhongtao/p/9614068.html