标签:channel rtc += filter log int start sign res cpu
2015年龚博士的曲率滤波算法刚出来的时候,在图像处理界也曾引起不小的轰动,特别是其所说的算法的简洁性,以及算法的效果、执行效率等方面较其他算法均有一定的优势,我在该算法刚出来时也曾经有关注,不过那个时候看到是迭代的算法,而且迭代的次数还蛮多了,就觉得算法应该不会太快,所以就放弃了对其进一步优化。最近,又偶尔一次碰触到该文章和代码,感觉还是有蛮大的优化空间的,所以抽空简单的实现他的算法。
该算法作者已经完全开源,项目地址见:https://github.com/YuanhaoGong/CurvatureFilter , 里面有matlab\c++\python等语言的代码,其中matlab的代码比较简洁,C++的是基于opencv的,而且里面包含了很多其他方面的代码,整体看起来我感觉有点乱。我只是稍微浏览了下。
通读matlab的代码,其和论文里提供的伪代码好像除了TV算法外,其他的都基本对应不上,我不知道是怎么回事,因此,本文仅以TV算法的优化作为例子,而且TV算法在GC\MC\TV算法中属于实现最为复杂和耗时的一个,也是最能反映优化极限的例子, 因此处理好了这个算法,另外两个的优化就是水道渠成的事情了。
算法的原理我不介绍,我也不在行,论文中给出的伪代码如下所示:


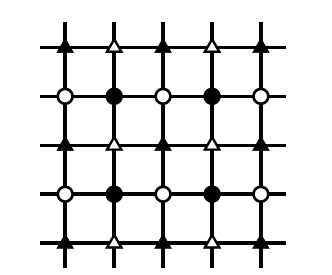
简单的说,对于每个像素,我们以其为中心,领域3*3的点,做算法15的操作,新的像素值就是原始像素值加上dm。但是我们做的时候是把整副图像分成四块,如上图右侧图所示,分为白色圆、黑色圆、白色三教乡、黑色三角形,这四块独立更新,更新完后的心像素值可以为尚未更新的像素所使用,一副图全部更新后,再次迭代该过程,直到达到指定迭代次数为止。
在国内网站上搜索,我发现网友CeleryChen在他的博文中曲率滤波的简单实现只有源码提到了该算法的实现代码,我看了下,和我的书写习惯还是很类似的(比原作者的代码看起来舒服多了),不过他写的不是TV算法, 我修改为TV算法后,核心代码如下所示:
void TV_Curvature_Filter(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride, int StartRow, int StartCol)
{
for (int Y = StartRow; Y < Height - 1; Y += 2)
{
unsigned char *LinePC = Src + Y * Stride;
unsigned char *LinePL = Src + (Y - 1) * Stride;
unsigned char *LinePN = Src + (Y + 1) * Stride;
unsigned char *LinePD = Dest + Y * Stride;
for (int X = StartCol; X < Width - 1; X += 2)
{
short Dist[8] = { 0 };
int C5 = 5 * LinePC[X];
Dist[0] = (LinePL[X - 1] + LinePL[X] + LinePC[X - 1] + LinePN[X - 1] + LinePN[X]) - C5;
Dist[1] = (LinePL[X] + LinePL[X + 1] + LinePC[X + 1] + LinePN[X] + LinePN[X + 1]) - C5;
Dist[2] = (LinePL[X - 1] + LinePL[X] + LinePL[X + 1] + LinePC[X - 1] + LinePC[X + 1]) - C5;
Dist[3] = (LinePN[X - 1] + LinePN[X] + LinePN[X + 1] + LinePC[X - 1] + LinePC[X + 1]) - C5;
Dist[4] = (LinePL[X - 1] + LinePL[X] + LinePL[X + 1] + LinePC[X - 1] + LinePN[X - 1]) - C5;
Dist[5] = (LinePL[X - 1] + LinePL[X + 1] + LinePL[X + 1] + LinePC[X + 1] + LinePN[X + 1]) - C5;
Dist[6] = (LinePN[X - 1] + LinePN[X] + LinePN[X + 1] + LinePL[X - 1] + LinePC[X - 1]) - C5;
Dist[7] = (LinePN[X - 1] + LinePN[X] + LinePN[X + 1] + LinePL[X + 1] + LinePC[X + 1]) - C5;
__m128i Dist128 = _mm_loadu_si128((const __m128i*)Dist);
__m128i AbsDist128 = _mm_abs_epi16(Dist128);
__m128i MinPos128 = _mm_minpos_epu16(AbsDist128);
LinePD[X] = IM_ClampToByte(LinePC[X] + Dist[_mm_extract_epi16(MinPos128, 1)] / 5) ;
}
}
}
void IM_CurvatureFilter(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride, int Iteration)
{
unsigned char* Temp = (unsigned char *)malloc(Height * Stride * sizeof(unsigned char));
memcpy(Temp, Src, Height * Stride * sizeof(unsigned char));
memcpy(Dest, Src, Height * Stride * sizeof(unsigned char));
for (int Y = 0; Y < Iteration; Y++)
{
TV_Curvature_Filter(Temp, Dest, Width, Height, Stride, 1, 1);
memcpy(Temp, Dest, Height * Stride * sizeof(unsigned char));
TV_Curvature_Filter(Temp, Dest, Width, Height, Stride, 2, 2);
memcpy(Temp, Dest, Height * Stride * sizeof(unsigned char));
TV_Curvature_Filter(Temp, Dest, Width, Height, Stride, 1, 2);
memcpy(Temp, Dest, Height * Stride * sizeof(unsigned char));
TV_Curvature_Filter(Temp, Dest, Width, Height, Stride, 2, 1);
memcpy(Temp, Dest, Height * Stride * sizeof(unsigned char));
}
free(Temp);
}
代码非常简单和简短,确实不超过100行,我们将迭代次数设置为50次,对比对应的matlab效果如下:



原图 C++代码的效果(迭代50次) matlab代码的效果
仔细观察,发现C++代码的效果在头发,帽子部位明显和matlab的不同,所以难怪CeleryChen在代码注释里有这样一段话:打算自己实现一个更快更好的曲率滤波的算法将其开源, 但发现按照作者的博士论文的算法出来的效果,达不到作者文献中的效果。
其实不是CeleryChen的代码逻辑问题,而是他可能没有注意到数据范围,在上述代码中,他使用unsigned char作为中间数据,而在更新的累加过程中使用了类似这样的语句:
LinePD[X] = IM_ClampToByte(LinePC[X] + Dist[_mm_extract_epi16(MinPos128, 1)]);
Clamp函数把数据再次抑制到0和255之间,这个在单次处理时问题不大,但是在迭代过程中就会出现较大的问题,总体来说同样的迭代次数效果要明显弱于matlab的代码,所以只要这个数据类型进行扩展,就可以,比如更改为浮点类型,代码如下所示:
void TV_Curvature_Filter(float *Src, float *Dest, int Width, int Height, int Stride, int StartRow, int StartCol)
{
for (int Y = StartRow; Y < Height - 1; Y += 2)
{
float *LinePC = Src + Y * Stride;
float *LinePL = Src + (Y - 1) * Stride;
float *LinePN = Src + (Y + 1) * Stride;
float *LinePD = Dest + Y * Stride;
for (int X = StartCol; X < Width - 1; X += 2)
{
float Dist[8] = { 0 };
float C5 = 5 * LinePC[X];
Dist[0] = (LinePL[X - 1] + LinePL[X] + LinePC[X - 1] + LinePN[X - 1] + LinePN[X]) - C5;
Dist[1] = (LinePL[X] + LinePL[X + 1] + LinePC[X + 1] + LinePN[X] + LinePN[X + 1]) - C5;
Dist[2] = (LinePL[X - 1] + LinePL[X] + LinePL[X + 1] + LinePC[X - 1] + LinePC[X + 1]) - C5;
Dist[3] = (LinePN[X - 1] + LinePN[X] + LinePN[X + 1] + LinePC[X - 1] + LinePC[X + 1]) - C5;
Dist[4] = (LinePL[X - 1] + LinePL[X] + LinePL[X + 1] + LinePC[X - 1] + LinePN[X - 1]) - C5;
Dist[5] = (LinePL[X - 1] + LinePL[X + 1] + LinePL[X + 1] + LinePC[X + 1] + LinePN[X + 1]) - C5;
Dist[6] = (LinePN[X - 1] + LinePN[X] + LinePN[X + 1] + LinePL[X - 1] + LinePC[X - 1]) - C5;
Dist[7] = (LinePN[X - 1] + LinePN[X] + LinePN[X + 1] + LinePL[X + 1] + LinePC[X + 1]) - C5;
float Min = abs(Dist[0]);
int Index = 0;
for (int Z = 1; Z < 8; Z++)
{
if (abs(Dist[Z]) < Min)
{
Min = abs(Dist[Z]);
Index = Z;
}
}
LinePD[X] = LinePC[X] + Dist[Index] * 0.2f;
}
}
}
void IM_CurvatureFilter(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride, int Iteration)
{
float *Temp1 = (float *)malloc(Height * Stride * sizeof(float));
float *Temp2 = (float *)malloc(Height * Stride * sizeof(float));
for (int Y = 0; Y < Height * Stride; Y++) Temp1[Y] = Src[Y];
memcpy(Temp2, Temp1, Height * Stride * sizeof(float));
for (int Y = 0; Y < Iteration; Y++)
{
TV_Curvature_Filter(Temp1, Temp2, Width, Height, Stride, 1, 1);
memcpy(Temp1, Temp2, Height * Stride * sizeof(float));
TV_Curvature_Filter(Temp1, Temp2, Width, Height, Stride, 2, 2);
memcpy(Temp1, Temp2, Height * Stride * sizeof(float));
TV_Curvature_Filter(Temp1, Temp2, Width, Height, Stride, 1, 2);
memcpy(Temp1, Temp2, Height * Stride * sizeof(float));
TV_Curvature_Filter(Temp1, Temp2, Width, Height, Stride, 2, 1);
memcpy(Temp1, Temp2, Height * Stride * sizeof(float));
}
for (int Y = 0; Y < Height * Stride; Y++) Dest[Y] = IM_ClampToByte((int)(Temp2[Y] + 0.4999999f));
free(Temp1);
free(Temp2);
}
结果如下:


 C++代码效果 matlab代码效果 差异图
C++代码效果 matlab代码效果 差异图
差异图不是全黑,这个和m代码里局部细节和C++有点不同有关。
到此,我们彻底消除CeleryChen所说的的算法效果问题。
论文中说到了讲图像分成四个块,如上述的代码所示,分四个部分更新,那其实这里就有个问题,四个块的更新顺序是什么,或者说如果你指定一个顺序,那你的理论依据是啥,因为一个块更新后,后面一个块的更新会依赖于前面已经更新的块的数据,所以这个顺序对结果可定是有影响的,我在论文里没有找到相关说法,那么好,我就实践,我把不同可能的更新顺序的结果都做出来, 结果发现,大家确实有区别,但是区别都是在一两个像素之间,因此,这个顺序就显得不是很重要了。
但是,我们不分块,又会存在什么问题呢,理论上有没有问题,我不知道,但是我们就实测下,不分块,代码如下所示:
void TV_Curvature_Filter(float *Src, float *Dest, int Width, int Height, int Stride)
{
for (int Y = 1; Y < Height - 1; Y++)
{
float *LinePC = Src + Y * Stride;
float *LinePL = Src + (Y - 1) * Stride;
float *LinePN = Src + (Y + 1) * Stride;
float *LinePD = Dest + Y * Stride;
for (int X = 1; X < Width - 1; X++)
{
float Dist[8] = { 0 };
float C5 = 5 * LinePC[X];
Dist[0] = (LinePL[X - 1] + LinePL[X] + LinePC[X - 1] + LinePN[X - 1] + LinePN[X]) - C5;
Dist[1] = (LinePL[X] + LinePL[X + 1] + LinePC[X + 1] + LinePN[X] + LinePN[X + 1]) - C5;
Dist[2] = (LinePL[X - 1] + LinePL[X] + LinePL[X + 1] + LinePC[X - 1] + LinePC[X + 1]) - C5;
Dist[3] = (LinePN[X - 1] + LinePN[X] + LinePN[X + 1] + LinePC[X - 1] + LinePC[X + 1]) - C5;
Dist[4] = (LinePL[X - 1] + LinePL[X] + LinePL[X + 1] + LinePC[X - 1] + LinePN[X - 1]) - C5;
Dist[5] = (LinePL[X - 1] + LinePL[X + 1] + LinePL[X + 1] + LinePC[X + 1] + LinePN[X + 1]) - C5;
Dist[6] = (LinePN[X - 1] + LinePN[X] + LinePN[X + 1] + LinePL[X - 1] + LinePC[X - 1]) - C5;
Dist[7] = (LinePN[X - 1] + LinePN[X] + LinePN[X + 1] + LinePL[X + 1] + LinePC[X + 1]) - C5;
float Min = abs(Dist[0]);
int Index = 0;
for (int Z = 1; Z < 8; Z++)
{
if (abs(Dist[Z]) < Min)
{
Min = abs(Dist[Z]);
Index = Z;
}
}
LinePD[X] = LinePC[X] + Dist[Index] * 0.2f;
}
}
}
void IM_CurvatureFilter_01(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride, int Iteration)
{
float *Temp1 = (float *)malloc(Height * Stride * sizeof(float));
float *Temp2 = (float *)malloc(Height * Stride * sizeof(float));
for (int Y = 0; Y < Height * Stride; Y++) Temp1[Y] = Src[Y];
memcpy(Temp2, Temp1, Height * Stride * sizeof(float));
for (int Y = 0; Y < Iteration; Y++)
{
TV_Curvature_Filter(Temp1, Temp2, Width, Height, Stride);
memcpy(Temp1, Temp2, Height * Stride * sizeof(float));
}
for (int Y = 0; Y < Height * Stride; Y++) Dest[Y] = IM_ClampToByte((int)(Temp2[Y] + 0.4999999f));
free(Temp1);
free(Temp2);
}
注意到在TV_Curvature_Filter函数中的两重for循环里每次循环变量自增值已经修改了,如果分块则一次增加2个像素,同时看到在前面未分块的代码汇中循环结束的标记是宽度和高度都减一,这个其实只是为了编码方便,放置访问越位内存,在matlab代码中,作者是做了扩边处理的,这些都不重要。
我们来看看处理结果的比较:



不分块结果图 分块结果图 差异图
确实有些差异,并且差异的比各分块之间的差异要大, 但是我觉得没有到那种已经有质的区别的档次。因此后续的优化我是基于不分块的来描述了,但是这种优化也是可以稍作修改就应用于分块的优化(代码会显得稍微繁琐一点,速度也会稍有下降)。
我们首先记录下目前的速度,不分块50次迭代512*512的标准lena灰度图耗时约 390ms(VS2013编译器,默认启用了SSE优化)。
第一个小优化:每次迭代里有个memcpy函数,目的是把中间的临时目的数据拷贝到临时源数据中,这里其实可以不用这个拷贝,直接使用个指针交换就可以了,如下所示:
void IM_CurvatureFilter_01(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride, int Iteration)
{
float *Temp1 = (float *)malloc(Height * Stride * sizeof(float));
float *Temp2 = (float *)malloc(Height * Stride * sizeof(float));
float *Temp = NULL;
for (int Y = 0; Y < Height * Stride; Y++) Temp1[Y] = Src[Y];
memcpy(Temp2, Temp1, Height * Stride * sizeof(float));
for (int Y = 0; Y < Iteration; Y++)
{
TV_Curvature_Filter(Temp1, Temp2, Width, Height, Stride);
Temp = Temp1, Temp1 = Temp2, Temp2 = Temp;
//memcpy(Temp1, Temp2, Height * Stride * sizeof(float));
}
for (int Y = 0; Y < Height * Stride; Y++) Dest[Y] = IM_ClampToByte((int)(Temp2[Y] + 0.4999999f));
free(Temp1);
free(Temp2);
}
执行速度变为约385ms,这只是个小菜,没啥意思。
第二步尝试,改变下算法的逻辑,我们注意到在Dist的8个元素计算中,其实是有很多重复计算的,我们如果不管Dist计算的顺序,其实是可以总结出其运算规律:

如果我们计算出第一个Dist中五个元素的和,后续就只要加一个进入的元素并且减去一个离开的元素就可以了,而且每次的减C5也可以只在第一个里做,这样TV_Curvature_Filter变为如下形式:
void TV_Curvature_Filter(float *Src, float *Dest, int Width, int Height, int Stride)
{
for (int Y = 1; Y < Height - 1; Y++)
{
float *LinePC = Src + Y * Stride;
float *LinePL = Src + (Y - 1) * Stride;
float *LinePN = Src + (Y + 1) * Stride;
float *LinePD = Dest + Y * Stride;
for (int X = 1; X < Width - 1; X++)
{
float Dist[8] = { 0 };
Dist[0] = (LinePL[X - 1] + LinePL[X] + LinePL[X + 1] + LinePC[X + 1] + LinePN[X + 1]) - 5 * LinePC[X];
Dist[1] = Dist[0] - LinePL[X - 1] + LinePN[X];
Dist[2] = Dist[1] - LinePL[X] + LinePN[X - 1];
Dist[3] = Dist[2] - LinePL[X + 1] + LinePC[X - 1];
Dist[4] = Dist[3] - LinePC[X + 1] + LinePL[X - 1];
Dist[5] = Dist[4] - LinePN[X + 1] + LinePL[X];
Dist[6] = Dist[5] - LinePN[X] + LinePL[X + 1];
Dist[7] = Dist[6] - LinePN[X - 1] + LinePC[X + 1];
float Min = abs(Dist[0]);
int Index = 0;
for (int Z = 1; Z < 8; Z++)
{
if (abs(Dist[Z]) < Min)
{
Min = abs(Dist[Z]);
Index = Z;
}
}
LinePD[X] = LinePC[X] + Dist[Index] * 0.2f;
}
}
}
核心的计算由原先的32次加法及8次减法变化为11次加法及8次减法,计算大为减少,这应该能加速不少吧。
按下F5,我靠运行时间变为了420ms,真是大失所望,为什么计算量少了但运行时间却多了呢,反汇编看编译器生成的代码,确实是修改的指令多很多,修改后少了不少。我自己想了想,觉得主要还是因为修改后的算法的计算是前后依赖的,在没算法前面的指令后续的指令是无法执行的,而编译器的在指令级别也是可以实现指令级并行,修改后的方案就无法重复利用这个特性了。
因此,这条路实际上是个失败的方案,龚博士在matlab代码里也有类似的优化方式,我把他修改为C代码后,得到的结论也是一样的。但是他 并不是一无是处,后面还是说到。
还有一些常规的优化,比如内部的8次循环展开,不用数组,直接用变量代替中间的距离变量等等,实践都表面没有啥效果。因此,我们不浪费时间,直接进行SSE优化了。
针对上述代码进行SSE自行优化应该说不是很困难的事情,可以看到,各个点的计算是独立的,和前后像素之间的计算是毫无干扰的,这种情况非常适合并行化(不管是SSE还是GPU都是一样的道理),基本上只要把对应的普通C运算符转换对一个的SIMD指令就OK了,那我们稍微关注下几个SIMD没有的运算符。
第一个是abs, SSE提供了大量的求绝对值的指令,但唯独对浮点数没有,看不懂这个世界,不过也没关系,浮点数普通C语言我们有个常用的方式实现绝对值计算如下所示:
inline float IM_AbsF(float V)
{
int I = ((*(int *)&V) & 0x7fffffff);
return (*(float *)&I);
}
有这个,对应的__m128数据类型计算也很简单:
// 浮点数据的绝对值计算
inline __m128 _mm_abs_ps(__m128 v)
{
static const int i = 0x7fffffff;
float mask = *(float*)&i;
return _mm_and_ps(v, _mm_set_ps1(mask));
}
注意这些简短的函数一定要inline,有的时候我们甚至可以使用__forceinline(仅限VS编译器)。
接下来我们主要关注下求最小值的索引问题,求最小值可以直接使用_mm_min_ps这个宏,但是我们最终的目的不是求最小值,而是求最小值对应的索引项目,然后在获得对应的值,因此,需要另寻出路。
我们知道SSE里有一系列的比较函数,对于浮点类型的也有不少,他们比较后会获得一个MASK值,符合条件的对应的MASK设置为OxFFFFFFFF,我们可以先获得最小值,然后通过判断这个比较对象其中的一个是否等于最小值来获得一个Mask,正好SSE还有一个_mm_blendv_ps宏来使用Mask来决定取何值为结果值,这样就可以获得需要的值了。
Min = _mm_min_ps(AbsDist0, AbsDist1);
Value = _mm_blendv_ps(Dist0, Dist1, _mm_cmpeq_ps(Min, AbsDist1));
Min = _mm_min_ps(Min, AbsDist2);
Value = _mm_blendv_ps(Value, Dist2, _mm_cmpeq_ps(Min, AbsDist2));
当然还有另外一种方式可以获得同样的效果:
Cmp = _mm_cmpgt_ps(AbsDist0, AbsDist1);
Min = _mm_blendv_ps(AbsDist0, AbsDist1, Cmp);
Value = _mm_blendv_ps(Dist0, Dist1, Cmp);
Cmp = _mm_cmpgt_ps(Min, AbsDist2);
Min = _mm_blendv_ps(Min, AbsDist2, Cmp);
Value = _mm_blendv_ps(Value, Dist2, Cmp);
两者的执行效率应该没有多大的区别。
贴出主要的SSE优化后的代码:
void TV_Curvature_Filter(float *Src, float *Dest, int Width, int Height, int Stride)
{
int BlockSize = 4, Block = (Width - 2) / BlockSize;
for (int Y = 1; Y < Height - 1; Y++)
{
float *LinePC = Src + Y * Stride;
float *LinePL = Src + (Y - 1) * Stride;
float *LinePN = Src + (Y + 1) * Stride;
float *LinePD = Dest + Y * Stride;
for (int X = 1; X < Block * BlockSize + 1; X += BlockSize)
{
__m128 FirstP0 = _mm_loadu_ps(LinePL + X - 1);
__m128 FirstP1 = _mm_loadu_ps(LinePL + X);
__m128 FirstP2 = _mm_loadu_ps(LinePL + X + 1);
__m128 SecondP0 = _mm_loadu_ps(LinePC + X - 1);
__m128 SecondP1 = _mm_loadu_ps(LinePC + X);
__m128 SecondP2 = _mm_loadu_ps(LinePC + X + 1);
__m128 ThirdP0 = _mm_loadu_ps(LinePN + X - 1);
__m128 ThirdP1 = _mm_loadu_ps(LinePN + X);
__m128 ThirdP2 = _mm_loadu_ps(LinePN + X + 1);
__m128 C5 = _mm_mul_ps(SecondP1, _mm_set1_ps(5));
__m128 Dist0 = _mm_sub_ps(_mm_add_ps(_mm_add_ps(_mm_add_ps(FirstP0, FirstP1), _mm_add_ps(FirstP2, SecondP2)), ThirdP2), C5);
__m128 Dist1 = _mm_sub_ps(_mm_add_ps(_mm_add_ps(_mm_add_ps(FirstP1, FirstP2), _mm_add_ps(SecondP2, ThirdP2)), ThirdP1), C5);
__m128 Dist2 = _mm_sub_ps(_mm_add_ps(_mm_add_ps(_mm_add_ps(FirstP2, SecondP2), _mm_add_ps(ThirdP2, ThirdP1)), ThirdP0), C5);
__m128 Dist3 = _mm_sub_ps(_mm_add_ps(_mm_add_ps(_mm_add_ps(SecondP2, ThirdP2), _mm_add_ps(ThirdP1, ThirdP0)), SecondP0), C5);
__m128 Dist4 = _mm_sub_ps(_mm_add_ps(_mm_add_ps(_mm_add_ps(ThirdP2, ThirdP1), _mm_add_ps(ThirdP0, SecondP0)), FirstP0), C5);
__m128 Dist5 = _mm_sub_ps(_mm_add_ps(_mm_add_ps(_mm_add_ps(ThirdP1, ThirdP0), _mm_add_ps(SecondP0, FirstP0)), FirstP1), C5);
__m128 Dist6 = _mm_sub_ps(_mm_add_ps(_mm_add_ps(_mm_add_ps(ThirdP0, SecondP0), _mm_add_ps(FirstP0, FirstP1)), FirstP2), C5);
__m128 Dist7 = _mm_sub_ps(_mm_add_ps(_mm_add_ps(_mm_add_ps(SecondP0, FirstP0), _mm_add_ps(FirstP1, FirstP2)), FirstP1), C5);
__m128 AbsDist0 = _mm_abs_ps(Dist0);
__m128 AbsDist1 = _mm_abs_ps(Dist1);
__m128 AbsDist2 = _mm_abs_ps(Dist2);
__m128 AbsDist3 = _mm_abs_ps(Dist3);
__m128 AbsDist4 = _mm_abs_ps(Dist4);
__m128 AbsDist5 = _mm_abs_ps(Dist5);
__m128 AbsDist6 = _mm_abs_ps(Dist6);
__m128 AbsDist7 = _mm_abs_ps(Dist7);
__m128 Min = _mm_min_ps(AbsDist0, AbsDist1);
__m128 Value = _mm_blendv_ps(Dist0, Dist1, _mm_cmpeq_ps(Min, AbsDist1));
Min = _mm_min_ps(Min, AbsDist2);
Value = _mm_blendv_ps(Value, Dist2, _mm_cmpeq_ps(Min, AbsDist2));
Min = _mm_min_ps(Min, AbsDist3);
Value = _mm_blendv_ps(Value, Dist3, _mm_cmpeq_ps(Min, AbsDist3));
Min = _mm_min_ps(Min, AbsDist4);
Value = _mm_blendv_ps(Value, Dist4, _mm_cmpeq_ps(Min, AbsDist4));
Min = _mm_min_ps(Min, AbsDist5);
Value = _mm_blendv_ps(Value, Dist5, _mm_cmpeq_ps(Min, AbsDist5));
Min = _mm_min_ps(Min, AbsDist6);
Value = _mm_blendv_ps(Value, Dist6, _mm_cmpeq_ps(Min, AbsDist6));
Min = _mm_min_ps(Min, AbsDist7);
Value = _mm_blendv_ps(Value, Dist7, _mm_cmpeq_ps(Min, AbsDist7));
_mm_storeu_ps(LinePD + X, _mm_add_ps(_mm_mul_ps(Value, _mm_set1_ps(0.20f)), SecondP1));
for (int X = Block * BlockSize + 1; X < Width - 1; X++)
{
// 请自行添加
}
}
}
}
编译后测试执行速度大约在85-90ms之间,和之前的385ms相比有4倍多的提高。
如果我们把上面的Dist0至于Dist7的计算方式更改为前面所说的前后依赖的那种方式,你会发现SSE的表现和C的表现是一致的,也是速度变慢了。
至此,我们的优化基本告一段落了,那是否就意味着这个算法的优化就已经到头了呢,非也非也,我们来继续挖掘。
前面说过,网友CeleryChen的算法得不到理想的结果是因为,其使用字节数据作为中间结果的缓存空间,这样会导致很多中间值被不合理的裁剪掉,因此,我们后面换成浮点数就解决了问题,但是,有没有可能使用其他的数据类型呢,比如使用signed short类型,是否可行,我们来分析下。
我么知道,short类型能表达的有效范围是[-32768,32767]之间,远比byte范围广,而且可以表达负数,而负数在中间结果里肯定会出现一些的。第二,如果我们把原始的图像数据扩大若干倍数,比如8倍,那么其动态范围将扩大8倍,这时在计算dm时的精度也将相应的扩大(既然采用整形,那么计算过程中的Dist值我们肯定会选择整形),我们需要的是合理确定这个放大倍数,使得结算过程中的任何中间结果都在short所能表达的范围内,注意到在TV算法中,最多时有5个像素值相加,这个时候我们如果选择放大16倍,最大像素值由255变为4080,如果这个5个像素都为255,相加后的值为20400,小于32768,如果取放大32倍,则有可能出现溢出了,因此,最大选择16倍是合理的。
当然,随着迭代的进行,中间值可能会出现超过4080的情况,但是要知道要出现多个4080以上的值才有可能出现溢出,同时这个迭代是于周边像素有关的,要出现这种情况的可能行还是非常小的,也许理论上根本不会出现。
好的,不在做更多的分析,我们先写个代码测试下:
void TV_Curvature_Filter(short *Src, short *Dest, int Width, int Height, int Stride)
{
short Dist[8] = { 0 };
for (int Y = 1; Y < Height - 1; Y++)
{
short *LinePC = Src + Y * Stride;
short *LinePL = Src + (Y - 1) * Stride;
short *LinePN = Src + (Y + 1) * Stride;
short *LinePD = Dest + Y * Stride;
for (int X = 1; X < Width - 1; X++)
{
short C5 = 5 * LinePC[X];
Dist[0] = (LinePL[X - 1] + LinePL[X] + LinePC[X - 1] + LinePN[X - 1] + LinePN[X]) - C5;
Dist[1] = (LinePL[X] + LinePL[X + 1] + LinePC[X + 1] + LinePN[X] + LinePN[X + 1]) - C5;
Dist[2] = (LinePL[X - 1] + LinePL[X] + LinePL[X + 1] + LinePC[X - 1] + LinePC[X + 1]) - C5;
Dist[3] = (LinePN[X - 1] + LinePN[X] + LinePN[X + 1] + LinePC[X - 1] + LinePC[X + 1]) - C5;
Dist[4] = (LinePL[X - 1] + LinePL[X] + LinePL[X + 1] + LinePC[X - 1] + LinePN[X - 1]) - C5;
Dist[5] = (LinePL[X - 1] + LinePL[X + 1] + LinePL[X + 1] + LinePC[X + 1] + LinePN[X + 1]) - C5;
Dist[6] = (LinePN[X - 1] + LinePN[X] + LinePN[X + 1] + LinePL[X - 1] + LinePC[X - 1]) - C5;
Dist[7] = (LinePN[X - 1] + LinePN[X] + LinePN[X + 1] + LinePL[X + 1] + LinePC[X + 1]) - C5;
short Min = abs(Dist[0]);
int Index = 0;
for (int Z = 1; Z < 8; Z++)
{
if (abs(Dist[Z]) < Min)
{
Min = abs(Dist[Z]);
Index = Z;
}
}
LinePD[X] = LinePC[X] + ((Dist[Index] + 2)/ 5);
}
}
}
void IM_CurvatureFilter(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride, int Iteration)
{
short *Temp1 = (short *)malloc(Height * Stride * sizeof(short));
short *Temp2 = (short *)malloc(Height * Stride * sizeof(short));
short *Temp = NULL;
for (int Y = 0; Y < Height * Stride; Y++) Temp1[Y] = Src[Y] * 16;
memcpy(Temp2, Temp1, Height * Stride * sizeof(unsigned short));
for (int Y = 0; Y < Iteration; Y++)
{
TV_Curvature_Filter(Temp1, Temp2, Width, Height, Stride);
Temp = Temp1, Temp1 = Temp2, Temp2 = Temp;
}
for (int Y = 0; Y < Height * Stride; Y++) Dest[Y] = IM_ClampToByte((Temp2[Y] + 8) / 16);
free(Temp1);
free(Temp2);
}
算法效果比较:



short类型简化版 float类型精确版 差异图
确实有些差别,特别是在边缘处,但是肉眼似乎无法感受到这种区别,个人认为如果要获取更好的速度,这个优化方式是可取的。
那么上述未做优化的short版本执行时间也大概是390ms,说明现代CPU的浮点计算能力也是很强的。
在CeleryChen提供给的版本中,我们注意到了一个他没有任何的进行比较的代码,而是使用一个叫做_mm_minpos_epu16的函数,我们来看下这个函数的MSDN说明:
__m128i _mm_minpos_epu16(__m128i a );
Parameters
[in] a
A 128-bit parameter that contains eight 16-bit unsigned integers.
Result value
A 128-bit value. The lowest order 16 bits are the minimum value found in parameter a. The second-lowest order 16 bits are the index of the minimum value found in parameter a.
就是说这个函数比较8个无符号的短整形数,返回的数据中第一个表示8个中最小的值,第二个数表示最小值对应的索引,这个和我们这个应用场景真的说是非常的靠谱,可以说是非常生动的案例。
我们按照CeleryChen的方式重写上上述的代码,修改如下:
void TV_Curvature_Filter(short *Src, short *Dest, int Width, int Height, int Stride) { short Dist[8] = { 0 }; for (int Y = 1; Y < Height - 1; Y++) { short *LinePC = Src + Y * Stride; short *LinePL = Src + (Y - 1) * Stride; short *LinePN = Src + (Y + 1) * Stride; short *LinePD = Dest + Y * Stride; for (int X = 1; X < Width - 1; X++) { short C5 = 5 * LinePC[X]; Dist[0] = (LinePL[X - 1] + LinePL[X] + LinePC[X - 1] + LinePN[X - 1] + LinePN[X]) - C5; Dist[1] = (LinePL[X] + LinePL[X + 1] + LinePC[X + 1] + LinePN[X] + LinePN[X + 1]) - C5; Dist[2] = (LinePL[X - 1] + LinePL[X] + LinePL[X + 1] + LinePC[X - 1] + LinePC[X + 1]) - C5; Dist[3] = (LinePN[X - 1] + LinePN[X] + LinePN[X + 1] + LinePC[X - 1] + LinePC[X + 1]) - C5; Dist[4] = (LinePL[X - 1] + LinePL[X] + LinePL[X + 1] + LinePC[X - 1] + LinePN[X - 1]) - C5; Dist[5] = (LinePL[X - 1] + LinePL[X + 1] + LinePL[X + 1] + LinePC[X + 1] + LinePN[X + 1]) - C5; Dist[6] = (LinePN[X - 1] + LinePN[X] + LinePN[X + 1] + LinePL[X - 1] + LinePC[X - 1]) - C5; Dist[7] = (LinePN[X - 1] + LinePN[X] + LinePN[X + 1] + LinePL[X + 1] + LinePC[X + 1]) - C5; __m128i Dist128 = _mm_loadu_si128((const __m128i*)Dist); __m128i AbsDist128 = _mm_abs_epi16(Dist128); __m128i MinPos128 = _mm_minpos_epu16(AbsDist128); LinePD[X] = LinePC[X] + Dist[_mm_extract_epi16(MinPos128, 1)] / 5 ; } } }
速度一下子提升到了260ms。
同样的道理,对于上面Dist中8个值的计算,我们一样可以用SIMD优化,但是注意到,此时继续使用_mm_minpos_epu16这个函数进行优化就有一定的代价了,因为这个时候我们需要进行排序的元素不是正好在一个XMM寄存里,而是在8个XMM寄存器或内存的列方向排列,这个时候如果需要继续使用_mm_minpos_epu16,就必须对计算出的8个Dist值进行转置。而转置的也是需要进行多次操作的,不知道这个耗时是否很大,我们编码进行测试:
static void TV_Curvature_Filter(short *Src, short *Dest, int Width, int Height, int Stride) { int BlockSize = 8, Block = (Width - 2) / BlockSize; for (int Y = 1; Y < Height - 1; Y++) { short *LinePC = Src + Y * Stride; short *LinePL = Src + (Y - 1) * Stride; short *LinePN = Src + (Y + 1) * Stride; short *LinePD = Dest + Y * Stride; for (int X = 1; X < Block * BlockSize + 1; X += BlockSize) { __m128i FirstP0 = _mm_loadu_si128((__m128i *)(LinePL + X - 1)); __m128i FirstP1 = _mm_loadu_si128((__m128i *)(LinePL + X)); __m128i FirstP2 = _mm_loadu_si128((__m128i *)(LinePL + X + 1)); __m128i SecondP0 = _mm_loadu_si128((__m128i *)(LinePC + X - 1)); __m128i SecondP1 = _mm_loadu_si128((__m128i *)(LinePC + X)); __m128i SecondP2 = _mm_loadu_si128((__m128i *)(LinePC + X + 1)); __m128i ThirdP0 = _mm_loadu_si128((__m128i *)(LinePN + X - 1)); __m128i ThirdP1 = _mm_loadu_si128((__m128i *)(LinePN + X)); __m128i ThirdP2 = _mm_loadu_si128((__m128i *)(LinePN + X + 1)); __m128i C5 = _mm_mullo_epi16(SecondP1, _mm_set1_epi16(5)); __m128i Dist0 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(FirstP0, FirstP1), _mm_add_epi16(FirstP2, SecondP2)), ThirdP2), C5); __m128i Dist1 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(FirstP1, FirstP2), _mm_add_epi16(SecondP2, ThirdP2)), ThirdP1), C5); __m128i Dist2 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(FirstP2, SecondP2), _mm_add_epi16(ThirdP2, ThirdP1)), ThirdP0), C5); __m128i Dist3 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(SecondP2, ThirdP2), _mm_add_epi16(ThirdP1, ThirdP0)), SecondP0), C5); __m128i Dist4 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(ThirdP2, ThirdP1), _mm_add_epi16(ThirdP0, SecondP0)), FirstP0), C5); __m128i Dist5 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(ThirdP1, ThirdP0), _mm_add_epi16(SecondP0, FirstP0)), FirstP1), C5); __m128i Dist6 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(ThirdP0, SecondP0), _mm_add_epi16(FirstP0, FirstP1)), FirstP2), C5); __m128i Dist7 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(SecondP0, FirstP0), _mm_add_epi16(FirstP1, FirstP2)), FirstP1), C5); __m128i S01L = _mm_unpacklo_epi16(Dist0, Dist1); // B3 A3 B2 A2 B1 A1 B0 A0 __m128i S23L = _mm_unpacklo_epi16(Dist2, Dist3); // D3 C3 D2 C2 D1 C1 D0 C0 __m128i S01H = _mm_unpackhi_epi16(Dist0, Dist1); // B7 A7 B6 A6 B5 A5 B4 A4 __m128i S23H = _mm_unpackhi_epi16(Dist2, Dist3); // D7 C7 D6 C6 D5 C5 D4 C4 __m128i S0123LL = _mm_unpacklo_epi32(S01L, S23L); // D1 C1 B1 A1 D0 C0 B0 A0 __m128i S0123LH = _mm_unpackhi_epi32(S01L, S23L); // D3 C3 B3 A3 D2 C2 B2 A2 __m128i S0123HL = _mm_unpacklo_epi32(S01H, S23H); // D5 C5 B5 A5 D4 C4 B4 A4 __m128i S0123HH = _mm_unpackhi_epi32(S01H, S23H); // D7 C7 B7 A7 D6 C6 B6 A6 __m128i S45L = _mm_unpacklo_epi16(Dist4, Dist5); // F3 E3 F2 E2 F1 E1 F0 E0 __m128i S67L = _mm_unpacklo_epi16(Dist6, Dist7); // H3 G3 H2 G2 H1 G1 H0 G0 __m128i S45H = _mm_unpackhi_epi16(Dist4, Dist5); // F7 E7 F6 E6 F5 E5 F4 E4 __m128i S67H = _mm_unpackhi_epi16(Dist6, Dist7); // H7 G7 H6 G6 H5 G5 H4 G4 __m128i S4567LL = _mm_unpacklo_epi32(S45L, S67L); // H1 G1 F1 E1 H0 G0 F0 E0 __m128i S4567LH = _mm_unpackhi_epi32(S45L, S67L); // H3 G3 F3 E3 H2 G2 F2 E2 __m128i S4567HL = _mm_unpacklo_epi32(S45H, S67H); // H5 G5 F5 E5 H4 G4 F4 E4 __m128i S4567HH = _mm_unpackhi_epi32(S45H, S67H); // H7 G7 F7 E7 H6 G6 F6 E6 Dist0 = _mm_unpacklo_epi64(S0123LL, S4567LL); // H0 G0 F0 E0 D0 C0 B0 A0 Dist1 = _mm_unpackhi_epi64(S0123LL, S4567LL); // H1 G1 F1 E1 D1 C1 B1 A1 Dist2 = _mm_unpacklo_epi64(S0123LH, S4567LH); // H2 G2 F2 E2 D2 C2 B2 A2 Dist3 = _mm_unpackhi_epi64(S0123LH, S4567LH); // H3 G3 F3 E3 D3 C3 B3 A3 Dist4 = _mm_unpacklo_epi64(S0123HL, S4567HL); // H4 G4 F4 E4 D4 C4 B4 A4 Dist5 = _mm_unpackhi_epi64(S0123HL, S4567HL); // H5 G5 F5 E5 D5 C5 B5 A5 Dist6 = _mm_unpacklo_epi64(S0123HH, S4567HH); // H6 G6 F6 E6 D6 C6 B6 A6 Dist7 = _mm_unpackhi_epi64(S0123HH, S4567HH); // H6 G7 F7 E7 D7 C7 B7 A7 LinePD[X + 0] = LinePC[X + 0] + (Dist0.m128i_i16[_mm_extract_epi16(_mm_minpos_epu16(_mm_abs_epi16(Dist0)), 1)] + 2) / 5; LinePD[X + 1] = LinePC[X + 1] + (Dist1.m128i_i16[_mm_extract_epi16(_mm_minpos_epu16(_mm_abs_epi16(Dist1)), 1)] + 2) / 5; LinePD[X + 2] = LinePC[X + 2] + (Dist2.m128i_i16[_mm_extract_epi16(_mm_minpos_epu16(_mm_abs_epi16(Dist2)), 1)] + 2) / 5; LinePD[X + 3] = LinePC[X + 3] + (Dist3.m128i_i16[_mm_extract_epi16(_mm_minpos_epu16(_mm_abs_epi16(Dist3)), 1)] + 2) / 5; LinePD[X + 4] = LinePC[X + 4] + (Dist4.m128i_i16[_mm_extract_epi16(_mm_minpos_epu16(_mm_abs_epi16(Dist4)), 1)] + 2) / 5; LinePD[X + 5] = LinePC[X + 5] + (Dist5.m128i_i16[_mm_extract_epi16(_mm_minpos_epu16(_mm_abs_epi16(Dist5)), 1)] + 2) / 5; LinePD[X + 6] = LinePC[X + 6] + (Dist6.m128i_i16[_mm_extract_epi16(_mm_minpos_epu16(_mm_abs_epi16(Dist6)), 1)] + 2) / 5; LinePD[X + 7] = LinePC[X + 7] + (Dist7.m128i_i16[_mm_extract_epi16(_mm_minpos_epu16(_mm_abs_epi16(Dist7)), 1)] + 2) / 5; } for (int X = Block * BlockSize + 1; X < Width - 1; X++) { // 请自行添加 } } }
注意到上面有大幅的代码是用来进行数据转置的,这部分代码如果展开解释,估计又是半天时间,我在代码后面都描述了每行执行后的状态,可自行理解,或者参考SSE图像算法优化系列四:图像转置的SSE优化(支持8位、24位、32位),提速4-6倍我这篇文章的说法也行。
我们知道__m128i变量在系统内部是个union结构,他是一个内存变量,我在程序直接访问他变量的成员,可能就会导致系统无法将这个变量直接编译为一个实际的寄存器变量,这在一定程度上会减缓速度(因此执行相关操作时可能需要把变量先复制到寄存器后在进行处理),但是由于代码中用到比较多的__m128i变量,估计这种损失会减少不少。
注意代码中我们的最后有个+2然后在整除,这个主要时为了四舍五入,对于这种迭代计算,这个可能比较重要,不然所得到的结果图像可能越来越暗。
算法的执行时间现在定格在50ms左右。
注意到上述代码最后还有相当一部分的计算是普通的C语言操作(+2, /5之类的),这部分为什么没有用SSE做呢,主要是那个除法,不太明白SIMD指令里为什么不提供整数除法的相关指令,也许他是觉得没有必要吧。但是如果我把他们转换到浮点数,在调用浮点的除法,然后再次转换回来,这个耗时可能还不如直接使用C的代码。
但是我们知道,除以一个常数通常编译器都会优化为移位和乘法,如果这样,既然硬件没带这个函数,我们就自己写个整形除法,那么早就有人做好了这份工作,在Github上有一个很强大的SIMD库,里面有一段关于整形除法(含16位及32位的)的代码,详见:https://www.agner.org/optimize/,唯一的问题就是除数必须是定值,而不能想_mm_div_ps那样四个除数可以不同。这里就不贴出代码了(详见本文附件代码)。
有个整数的除法,我们就可以继续优化上述代码,我们把从Dist0到Dist7中提取的8个数据保存到临时的8个short类型的数据中,然后后续的加法和除法直接使用SSE进行处理,如下所示:
static void TV_Curvature_Filter(short *Src, short *Dest, int Width, int Height, int Stride) { int BlockSize = 8, Block = (Width - 2) / BlockSize; short Multiplier5 = 0; int Shift5 = 0, Sign5 = 0; GetMSS_S(5, Multiplier5, Shift5, Sign5); short Dist[8]; for (int Y = 1; Y < Height - 1; Y++) { short *LinePC = Src + Y * Stride; short *LinePL = Src + (Y - 1) * Stride; short *LinePN = Src + (Y + 1) * Stride; short *LinePD = Dest + Y * Stride; for (int X = 1; X < Block * BlockSize + 1; X += BlockSize) { __m128i FirstP0 = _mm_loadu_si128((__m128i *)(LinePL + X - 1)); __m128i FirstP1 = _mm_loadu_si128((__m128i *)(LinePL + X)); __m128i FirstP2 = _mm_loadu_si128((__m128i *)(LinePL + X + 1)); __m128i SecondP0 = _mm_loadu_si128((__m128i *)(LinePC + X - 1)); __m128i SecondP1 = _mm_loadu_si128((__m128i *)(LinePC + X)); __m128i SecondP2 = _mm_loadu_si128((__m128i *)(LinePC + X + 1)); __m128i ThirdP0 = _mm_loadu_si128((__m128i *)(LinePN + X - 1)); __m128i ThirdP1 = _mm_loadu_si128((__m128i *)(LinePN + X)); __m128i ThirdP2 = _mm_loadu_si128((__m128i *)(LinePN + X + 1)); __m128i C5 = _mm_mullo_epi16(SecondP1, _mm_set1_epi16(5)); __m128i Dist0 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(FirstP0, FirstP1), _mm_add_epi16(FirstP2, SecondP2)), ThirdP2), C5); __m128i Dist1 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(FirstP1, FirstP2), _mm_add_epi16(SecondP2, ThirdP2)), ThirdP1), C5); __m128i Dist2 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(FirstP2, SecondP2), _mm_add_epi16(ThirdP2, ThirdP1)), ThirdP0), C5); __m128i Dist3 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(SecondP2, ThirdP2), _mm_add_epi16(ThirdP1, ThirdP0)), SecondP0), C5); __m128i Dist4 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(ThirdP2, ThirdP1), _mm_add_epi16(ThirdP0, SecondP0)), FirstP0), C5); __m128i Dist5 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(ThirdP1, ThirdP0), _mm_add_epi16(SecondP0, FirstP0)), FirstP1), C5); __m128i Dist6 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(ThirdP0, SecondP0), _mm_add_epi16(FirstP0, FirstP1)), FirstP2), C5); __m128i Dist7 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(SecondP0, FirstP0), _mm_add_epi16(FirstP1, FirstP2)), FirstP1), C5); __m128i S01L = _mm_unpacklo_epi16(Dist0, Dist1); // B3 A3 B2 A2 B1 A1 B0 A0 __m128i S23L = _mm_unpacklo_epi16(Dist2, Dist3); // D3 C3 D2 C2 D1 C1 D0 C0 __m128i S01H = _mm_unpackhi_epi16(Dist0, Dist1); // B7 A7 B6 A6 B5 A5 B4 A4 __m128i S23H = _mm_unpackhi_epi16(Dist2, Dist3); // D7 C7 D6 C6 D5 C5 D4 C4 __m128i S0123LL = _mm_unpacklo_epi32(S01L, S23L); // D1 C1 B1 A1 D0 C0 B0 A0 __m128i S0123LH = _mm_unpackhi_epi32(S01L, S23L); // D3 C3 B3 A3 D2 C2 B2 A2 __m128i S0123HL = _mm_unpacklo_epi32(S01H, S23H); // D5 C5 B5 A5 D4 C4 B4 A4 __m128i S0123HH = _mm_unpackhi_epi32(S01H, S23H); // D7 C7 B7 A7 D6 C6 B6 A6 __m128i S45L = _mm_unpacklo_epi16(Dist4, Dist5); // F3 E3 F2 E2 F1 E1 F0 E0 __m128i S67L = _mm_unpacklo_epi16(Dist6, Dist7); // H3 G3 H2 G2 H1 G1 H0 G0 __m128i S45H = _mm_unpackhi_epi16(Dist4, Dist5); // F7 E7 F6 E6 F5 E5 F4 E4 __m128i S67H = _mm_unpackhi_epi16(Dist6, Dist7); // H7 G7 H6 G6 H5 G5 H4 G4 __m128i S4567LL = _mm_unpacklo_epi32(S45L, S67L); // H1 G1 F1 E1 H0 G0 F0 E0 __m128i S4567LH = _mm_unpackhi_epi32(S45L, S67L); // H3 G3 F3 E3 H2 G2 F2 E2 __m128i S4567HL = _mm_unpacklo_epi32(S45H, S67H); // H5 G5 F5 E5 H4 G4 F4 E4 __m128i S4567HH = _mm_unpackhi_epi32(S45H, S67H); // H7 G7 F7 E7 H6 G6 F6 E6 Dist0 = _mm_unpacklo_epi64(S0123LL, S4567LL); // H0 G0 F0 E0 D0 C0 B0 A0 Dist1 = _mm_unpackhi_epi64(S0123LL, S4567LL); // H1 G1 F1 E1 D1 C1 B1 A1 Dist2 = _mm_unpacklo_epi64(S0123LH, S4567LH); // H2 G2 F2 E2 D2 C2 B2 A2 Dist3 = _mm_unpackhi_epi64(S0123LH, S4567LH); // H3 G3 F3 E3 D3 C3 B3 A3 Dist4 = _mm_unpacklo_epi64(S0123HL, S4567HL); // H4 G4 F4 E4 D4 C4 B4 A4 Dist5 = _mm_unpackhi_epi64(S0123HL, S4567HL); // H5 G5 F5 E5 D5 C5 B5 A5 Dist6 = _mm_unpacklo_epi64(S0123HH, S4567HH); // H6 G6 F6 E6 D6 C6 B6 A6 Dist7 = _mm_unpackhi_epi64(S0123HH, S4567HH); // H6 G7 F7 E7 D7 C7 B7 A7 Dist[0] = Dist0.m128i_i16[_mm_extract_epi16(_mm_minpos_epu16(_mm_abs_epi16(Dist0)), 1)]; Dist[1] = Dist1.m128i_i16[_mm_extract_epi16(_mm_minpos_epu16(_mm_abs_epi16(Dist1)), 1)]; Dist[2] = Dist2.m128i_i16[_mm_extract_epi16(_mm_minpos_epu16(_mm_abs_epi16(Dist2)), 1)]; Dist[3] = Dist3.m128i_i16[_mm_extract_epi16(_mm_minpos_epu16(_mm_abs_epi16(Dist3)), 1)]; Dist[4] = Dist4.m128i_i16[_mm_extract_epi16(_mm_minpos_epu16(_mm_abs_epi16(Dist4)), 1)]; Dist[5] = Dist5.m128i_i16[_mm_extract_epi16(_mm_minpos_epu16(_mm_abs_epi16(Dist5)), 1)]; Dist[6] = Dist6.m128i_i16[_mm_extract_epi16(_mm_minpos_epu16(_mm_abs_epi16(Dist6)), 1)]; Dist[7] = Dist7.m128i_i16[_mm_extract_epi16(_mm_minpos_epu16(_mm_abs_epi16(Dist7)), 1)]; __m128i DivY = _mm_divp_epi16(_mm_add_epi16(_mm_set1_epi16(2), _mm_loadu_si128((__m128i *)Dist)), Multiplier5, Shift5); _mm_storeu_si128((__m128i *)(LinePD + X), _mm_add_epi16(DivY, SecondP1)); } for (int X = Block * BlockSize + 1; X < Width - 1; X++) { // 请自行添加 } } }
速度提升到了45ms,相对于浮点类型的SSE优化,又有了进一倍的提速。
我们再次回到浮点的SSE优化代码,在浮点版本的优化里,因为浮点里是没有_mm_minpos_epu16这样的函数的,因此我们就使用了比较传统的比较函数方式,那么同样的道理,使用short类型的为什么不可以用那些函数呢,应该一样可以,浮点的和short类型的基本都有对应的函数,除了没有_mm_blendv_epi16函数(注意不是_mm_blend_epi16函数,他们对参数的要求是不一样的),但是有_mm_blendv_epi8可以代替,而且功能是一样的,我们再把刚刚讲到的除法运算的优化结合在一起,形成了如下的优化代码:
static void TV_Curvature_Filter_03(short *Src, short *Dest, int Width, int Height, int Stride) { int BlockSize = 8, Block = (Width - 2) / BlockSize; short Multiplier5 = 0; int Shift5 = 0, Sign5 = 0; GetMSS_S(5, Multiplier5, Shift5, Sign5); short Dist[8]; for (int Y = 1; Y < Height - 1; Y++) { short *LinePC = Src + Y * Stride; short *LinePL = Src + (Y - 1) * Stride; short *LinePN = Src + (Y + 1) * Stride; short *LinePD = Dest + Y * Stride; for (int X = 1; X < Block * BlockSize + 1; X += BlockSize) { __m128i FirstP0 = _mm_loadu_si128((__m128i *)(LinePL + X - 1)); __m128i FirstP1 = _mm_loadu_si128((__m128i *)(LinePL + X)); __m128i FirstP2 = _mm_loadu_si128((__m128i *)(LinePL + X + 1)); __m128i SecondP0 = _mm_loadu_si128((__m128i *)(LinePC + X - 1)); __m128i SecondP1 = _mm_loadu_si128((__m128i *)(LinePC + X)); __m128i SecondP2 = _mm_loadu_si128((__m128i *)(LinePC + X + 1)); __m128i ThirdP0 = _mm_loadu_si128((__m128i *)(LinePN + X - 1)); __m128i ThirdP1 = _mm_loadu_si128((__m128i *)(LinePN + X)); __m128i ThirdP2 = _mm_loadu_si128((__m128i *)(LinePN + X + 1)); __m128i C5 = _mm_mullo_epi16(SecondP1, _mm_set1_epi16(5)); __m128i Dist0 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(FirstP0, FirstP1), _mm_add_epi16(FirstP2, SecondP2)), ThirdP2), C5); __m128i Dist1 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(FirstP1, FirstP2), _mm_add_epi16(SecondP2, ThirdP2)), ThirdP1), C5); __m128i Dist2 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(FirstP2, SecondP2), _mm_add_epi16(ThirdP2, ThirdP1)), ThirdP0), C5); __m128i Dist3 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(SecondP2, ThirdP2), _mm_add_epi16(ThirdP1, ThirdP0)), SecondP0), C5); __m128i Dist4 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(ThirdP2, ThirdP1), _mm_add_epi16(ThirdP0, SecondP0)), FirstP0), C5); __m128i Dist5 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(ThirdP1, ThirdP0), _mm_add_epi16(SecondP0, FirstP0)), FirstP1), C5); __m128i Dist6 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(ThirdP0, SecondP0), _mm_add_epi16(FirstP0, FirstP1)), FirstP2), C5); __m128i Dist7 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(SecondP0, FirstP0), _mm_add_epi16(FirstP1, FirstP2)), FirstP1), C5); __m128i AbsDist0 = _mm_abs_epi16(Dist0); __m128i AbsDist1 = _mm_abs_epi16(Dist1); __m128i AbsDist2 = _mm_abs_epi16(Dist2); __m128i AbsDist3 = _mm_abs_epi16(Dist3); __m128i AbsDist4 = _mm_abs_epi16(Dist4); __m128i AbsDist5 = _mm_abs_epi16(Dist5); __m128i AbsDist6 = _mm_abs_epi16(Dist6); __m128i AbsDist7 = _mm_abs_epi16(Dist7); __m128i Cmp = _mm_cmpgt_epi16(AbsDist0, AbsDist1); __m128i Min = _mm_blendv_epi8(AbsDist0, AbsDist1, Cmp); __m128i Value = _mm_blendv_epi8(Dist0, Dist1, Cmp); Cmp = _mm_cmpgt_epi16(Min, AbsDist2); Min = _mm_blendv_epi8(Min, AbsDist2, Cmp); Value = _mm_blendv_epi8(Value, Dist2, Cmp); Cmp = _mm_cmpgt_epi16(Min, AbsDist3); Min = _mm_blendv_epi8(Min, AbsDist3, Cmp); Value = _mm_blendv_epi8(Value, Dist3, Cmp); Cmp = _mm_cmpgt_epi16(Min, AbsDist4); Min = _mm_blendv_epi8(Min, AbsDist4, Cmp); Value = _mm_blendv_epi8(Value, Dist4, Cmp); Cmp = _mm_cmpgt_epi16(Min, AbsDist5); Min = _mm_blendv_epi8(Min, AbsDist5, Cmp); Value = _mm_blendv_epi8(Value, Dist5, Cmp); Cmp = _mm_cmpgt_epi16(Min, AbsDist6); Min = _mm_blendv_epi8(Min, AbsDist6, Cmp); Value = _mm_blendv_epi8(Value, Dist6, Cmp); Cmp = _mm_cmpgt_epi16(Min, AbsDist7); Min = _mm_blendv_epi8(Min, AbsDist7, Cmp); Value = _mm_blendv_epi8(Value, Dist7, Cmp); __m128i DivY = _mm_divp_epi16(_mm_add_epi16(_mm_set1_epi16(2), Value), Multiplier5, Shift5); _mm_storeu_si128((__m128i *)(LinePD + X), _mm_add_epi16(DivY, SecondP1)); } for (int X = Block * BlockSize + 1; X < Width - 1; X++) { // 请自行添加 } } }
执行速度来到了30ms,比前面的使用_mm_minpos_epu16要更快,这个事情说明我们不能墨守成规,不要被一些先验的东西卡死。
到这里,基本上说已经优化的差不多了,我们再多说点其他的东西,我们注意到,再上述所有代码的处理中,我们都没有处理边缘位置的像素,这是因为边缘像素的的8领域会超出图像边界,一种方式就是扩边,然后执行算法,然后再裁剪,另外一种就是对边缘像素进行独立的算法书写。我想他们都是比较烦人的事情,但是我们这里再次利用我曾经提过的一个技巧,即SSE图像算法优化系列九:灵活运用SIMD指令16倍提升Sobel边缘检测的速度(4000*3000的24位图像时间由480ms降低到30ms)一文所提到的利用三行缓存数据让8领域算法边界完美处理,而且还支持In-Place操作的方式,这里具有的优点还有就是不需要两份中间内存,特别对于浮点版本的数据,内存占用量大幅减少,也是一个重要的突破。
void TV_Curvature_Filter_Short(short *Data, int Width, int Height, int Stride) { int Channel = Stride / Width; short Multiplier5 = 0; int Shift5 = 0, Sign5 = 0; GetMSS_S(5, Multiplier5, Shift5, Sign5); int BlockSize = 8, Block = (Width * Channel) / BlockSize; short *RowCopy = (short *)malloc((Width + 2) * 3 * Channel * sizeof(short)); short *First = RowCopy; short *Second = RowCopy + (Width + 2) * Channel; short *Third = RowCopy + (Width + 2) * 2 * Channel; memcpy(Second, Data, Channel * sizeof(short)); memcpy(Second + Channel, Data, Width * Channel * sizeof(short)); // 拷贝数据到中间位置 memcpy(Second + (Width + 1) * Channel, Data + (Width - 1) * Channel, Channel * sizeof(short)); memcpy(First, Second, (Width + 2) * Channel * sizeof(short)); // 第一行和第二行一样 memcpy(Third, Data + Stride, Channel * sizeof(short)); // 拷贝第二行数据 memcpy(Third + Channel, Data + Stride, Width * Channel * sizeof(short)); memcpy(Third + (Width + 1) * Channel, Data + Stride + (Width - 1) * Channel, Channel * sizeof(short)); for (int Y = 0; Y < Height; Y++) { short *LinePD = Data + Y * Stride; if (Y != 0) { short *Temp = First; First = Second; Second = Third; Third = Temp; } if (Y == Height - 1) { memcpy(Third, Second, (Width + 2) * Channel * sizeof(short)); } else { memcpy(Third, Data + (Y + 1) * Stride, Channel* sizeof(short)); memcpy(Third + Channel, Data + (Y + 1) * Stride, Width * Channel* sizeof(short)); // 由于备份了前面一行的数据,这里即使Data和Dest相同也是没有问题的 memcpy(Third + (Width + 1) * Channel, Data + (Y + 1) * Stride + (Width - 1) * Channel, Channel* sizeof(short)); } for (int X = 0; X < Block * BlockSize; X += BlockSize) { __m128i FirstP0 = _mm_loadu_si128((__m128i *)(First + X)); __m128i FirstP1 = _mm_loadu_si128((__m128i *)(First + X + Channel)); __m128i FirstP2 = _mm_loadu_si128((__m128i *)(First + X + Channel + Channel)); __m128i SecondP0 = _mm_loadu_si128((__m128i *)(Second + X)); __m128i SecondP1 = _mm_loadu_si128((__m128i *)(Second + X + Channel)); __m128i SecondP2 = _mm_loadu_si128((__m128i *)(Second + X + Channel + Channel)); __m128i ThirdP0 = _mm_loadu_si128((__m128i *)(Third + X)); __m128i ThirdP1 = _mm_loadu_si128((__m128i *)(Third + X + Channel)); __m128i ThirdP2 = _mm_loadu_si128((__m128i *)(Third + X + Channel + Channel)); __m128i C5 = _mm_mullo_epi16(SecondP1, _mm_set1_epi16(5)); __m128i Dist0 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(FirstP0, FirstP1), _mm_add_epi16(FirstP2, SecondP2)), ThirdP2), C5); __m128i Dist1 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(FirstP1, FirstP2), _mm_add_epi16(SecondP2, ThirdP2)), ThirdP1), C5); __m128i Dist2 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(FirstP2, SecondP2), _mm_add_epi16(ThirdP2, ThirdP1)), ThirdP0), C5); __m128i Dist3 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(SecondP2, ThirdP2), _mm_add_epi16(ThirdP1, ThirdP0)), SecondP0), C5); __m128i Dist4 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(ThirdP2, ThirdP1), _mm_add_epi16(ThirdP0, SecondP0)), FirstP0), C5); __m128i Dist5 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(ThirdP1, ThirdP0), _mm_add_epi16(SecondP0, FirstP0)), FirstP1), C5); __m128i Dist6 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(ThirdP0, SecondP0), _mm_add_epi16(FirstP0, FirstP1)), FirstP2), C5); __m128i Dist7 = _mm_sub_epi16(_mm_add_epi16(_mm_add_epi16(_mm_add_epi16(SecondP0, FirstP0), _mm_add_epi16(FirstP1, FirstP2)), FirstP1), C5); __m128i AbsDist0 = _mm_abs_epi16(Dist0); __m128i AbsDist1 = _mm_abs_epi16(Dist1); __m128i AbsDist2 = _mm_abs_epi16(Dist2); __m128i AbsDist3 = _mm_abs_epi16(Dist3); __m128i AbsDist4 = _mm_abs_epi16(Dist4); __m128i AbsDist5 = _mm_abs_epi16(Dist5); __m128i AbsDist6 = _mm_abs_epi16(Dist6); __m128i AbsDist7 = _mm_abs_epi16(Dist7); __m128i Cmp = _mm_cmpgt_epi16(AbsDist0, AbsDist1); __m128i Min = _mm_blendv_epi8(AbsDist0, AbsDist1, Cmp); __m128i Value = _mm_blendv_epi8(Dist0, Dist1, Cmp); Cmp = _mm_cmpgt_epi16(Min, AbsDist2); Min = _mm_blendv_epi8(Min, AbsDist2, Cmp); Value = _mm_blendv_epi8(Value, Dist2, Cmp); Cmp = _mm_cmpgt_epi16(Min, AbsDist3); Min = _mm_blendv_epi8(Min, AbsDist3, Cmp); Value = _mm_blendv_epi8(Value, Dist3, Cmp); Cmp = _mm_cmpgt_epi16(Min, AbsDist4); Min = _mm_blendv_epi8(Min, AbsDist4, Cmp); Value = _mm_blendv_epi8(Value, Dist4, Cmp); Cmp = _mm_cmpgt_epi16(Min, AbsDist5); Min = _mm_blendv_epi8(Min, AbsDist5, Cmp); Value = _mm_blendv_epi8(Value, Dist5, Cmp); Cmp = _mm_cmpgt_epi16(Min, AbsDist6); Min = _mm_blendv_epi8(Min, AbsDist6, Cmp); Value = _mm_blendv_epi8(Value, Dist6, Cmp); Cmp = _mm_cmpgt_epi16(Min, AbsDist7); Min = _mm_blendv_epi8(Min, AbsDist7, Cmp); Value = _mm_blendv_epi8(Value, Dist7, Cmp); __m128i DivY = _mm_divp_epi16(_mm_add_epi16(_mm_set1_epi16(2), Value), Multiplier5, Shift5); _mm_storeu_si128((__m128i *)(LinePD + X), _mm_add_epi16(DivY, SecondP1)); } for (int X = Block * BlockSize; X < Width; X++) { // 请自行添加 } } free(RowCopy); } void IM_TV_CurvatureFilter_Short(unsigned char *Src, unsigned char *Dest, int Width, int Height, int Stride, int Iteration) { short *Temp = (short *)malloc(Height * Stride * sizeof(short)); for (int Y = 0; Y < Height * Stride; Y++) Temp[Y] = Src[Y] * 16; for (int Y = 0; Y < Iteration; Y++) { TV_Curvature_Filter_Short(Temp, Width, Height, Stride); } for (int Y = 0; Y < Height * Stride; Y++) Dest[Y] = IM_ClampToByte((Temp[Y] + 8) / 16); free(Temp); }
整体代码也很简单,执行效率却没有什么下降。
其实还是有继续优化的空间的,比如8个Dist的计算里还是有些重复的,还有除以5那一块还可以继续挖掘,直接嵌入相应的数据。我这里留给有兴趣的朋友自行处理了。
另外,再测试的过程中,我们发现除了最后的利用三行缓存的代码外,其他的代码都存在一个异常现象,就是512*512的处理时间会比其他非这个尺寸的慢不少(比如宽度改为513后),我记得以前确实在某个地方看到有这个问题,反倒是512这个宽度处理起来慢,不太记得这个是为什么了,好像是个cache的问题。
那么对于GC和MC的优化因为思路差不多,因此,本文未对他们进行分析和处理了,但是要注意作者最原始论文的公式已经不是最新的了,可以从https://xplorebcpaz.ieee.org/document/7835193/里下载,不然你可以看到论文伪代码和matlab的不对应。
当然,如果觉得short的精度不够,我们也可以考虑使用int类型来处理,对于MC这类有除以16之类的算法来说,使用int至少还是会比float来的快。
源代码下载地址:https://files.cnblogs.com/files/Imageshop/CurvatureFilter.rar
真心写的累,有爱心的朋友请看下................

SSE图像算法优化系列二十二:优化龚元浩博士的曲率滤波算法,达到约500 MPixels/Sec的单次迭代速度。
标签:channel rtc += filter log int start sign res cpu
原文地址:https://www.cnblogs.com/Imageshop/p/9617419.html