标签:建立 频率 clean 包括 github 存储引擎 偏移量 子节点 攻击
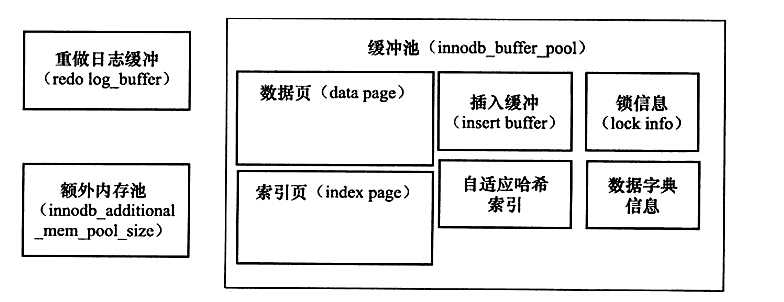
之所以叫LRU List 是因为他采用LRU 最近最少使用算法,把clean buffer 缓存页管理起来,这样一来热点数据就在列表头部,不热点的页就在列表尾部。
如果遇到Free List没有能使用的 free buffer时,那么就把LRU List 末尾的数据释放,变为free buffer 以供新的page读入。之所以这样是因为这些页是不是热点数据,对这些数据的修改写入概率小,即使释放之后读取概率也不大,可以减少IO。
这三个列表结构是双向链表,他们是逻辑上的,并不是物理上存在的。所以出现脏页并不是从LRU List 复制到 Flush List,内存弥足珍贵。所以LRU 和 Flush List都有脏页。
标签:建立 频率 clean 包括 github 存储引擎 偏移量 子节点 攻击
原文地址:https://www.cnblogs.com/mibloom/p/9622960.html