标签:private nat comm arraylist rem eve this length 功能实现
本文项目Github地址:https://github.com/MeiJinpen/wc
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 60 |
| Development | 开发 | 855 | 1110 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 60 |
| · Design Spec | · 生成设计文档 | 30 | 60 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 45 | 30 |
| · Coding | · 具体编码 | 360 | 480 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 240 | 360 |
| Reporting | 报告 | 90 | 150 |
| · Test Report | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 60 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 975 | 1320 |
刚刚拿到这个项目时,想到的是先分析该项目的需求,了解清楚具体需求后,再思考项目的架构该如何规划,才能使得项目可读性可维护性强。比如这个项目,就可以按照功能模块分开,如每一个参数代表着一个功能,可以把每个功能解耦,使得后面修改代码时更加清晰易懂。然后架构分析完成后,再进一步分析每个功能的具体需求实现,如果碰到一些需求暂时无法想出解决方案时,可以善于利用搜索引擎,找到合适的解决方案,明白如何去实现某个功能,这些都可以记录下来,做成流程图。对于一些功能,可能会接触到新的技术,比如此项目中的正则表达式,可以先去学习一下使用方法,熟悉使用后在运用在项目中,此时就可以动手开发了。开发过程中,可能会遇到各种问题,有些问题如果思考一段时间后还不能解决,可以上网查找解决方案,因为大部分我们遇到的问题,网上都会有人遇到并解决后记录下来。
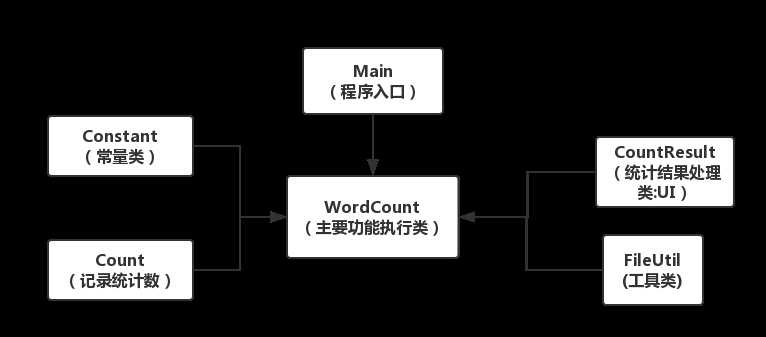
本项目可以简单的分为两个模块:1.对参数指令的解析操作;2.对指定文件或匹配到的文件内容进行统计操作
第一个模块:对参数指令的解析操作。由于本项目用到的指令其实不多,所以我统一使用了一个Constant的常量类存放指令操作符,并在Main函数执行后对输入的参数进行处理,转换为常量表示,这样更利于对每个操作的判断。根据使用到的参数会统一记录到WordCount的成员变量中存储,以便后续对文件统计操作时使用。
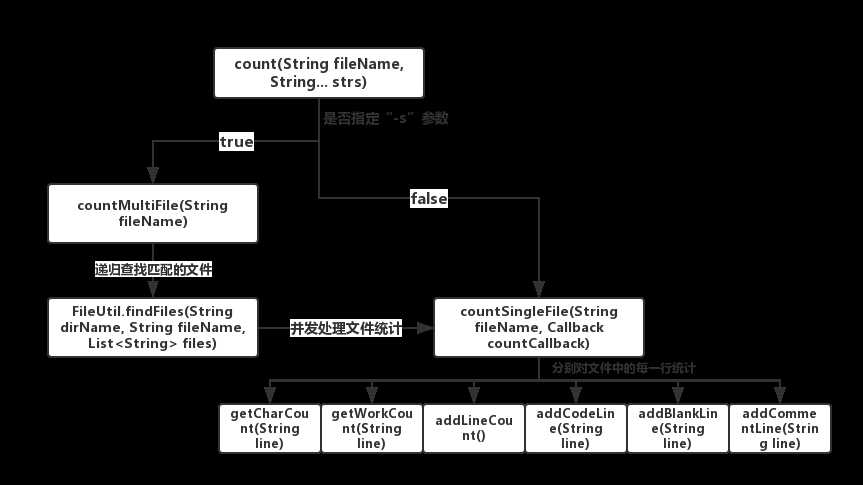
第二个模块:对指定文件或匹配到的文件内容进行统计操作。由于可以通过指令“-s”去指定通配符文件查询,这里我分开处理。当不指定“-s”参数时,也就是对指定文件进行统计处理,就直接使用了IO去操作文件读取并统计;当指定“-s”参数时,由于可能是匹配到多文件操作,使用到了线程池去优化IO操作,并发处理不同文件的统计。然后IO读取文件时,通过参数的指定,去判断需要执行哪些统计,比如制定了“-w -a”,则会去统计单词数和代码行、空行和注释行。这样就可以避免未指定参数却全部统计导致效率变慢的问题。对于统计功能的实现,分功能实现在不同方法中,使用了正则表达式处理字符串。
类关系图如下:
主要流程图:
程序启动Main.java:
public class Main {
/**
* 程序入口
* @param args 第一参数:{-c, -w, -l, -s, -a};第二参数:[fileName]
*/
public static void main(String[] args) {
WordCount wordCount = new WordCount();
if (args == null || args.length == 0) {
System.out.println("需要参数{-c, -w, -l, -s, -a} [fileName],请重新输入");
} else {
wordCount.count(args[args.length - 1], args);
}
}
}WordCount.java
/**
* 统计文件的字符数、单词数和行数等
* @param fileName 文件名
* @param strs 参数数组
*/
public void count(String fileName, String... strs) {
checkParams(strs);
if(isFuzzyQuery) {
//递归处理文件
countMultiFile(fileName);
} else {
//处理单文件
countSingleFile(fileName, new CountResult(this));
}
}统计文件的总入口,通过“-s”去调用不同的功能。
/**
* 统计单文件
* @param fileName
* @param countCallback
*/
private void countSingleFile(String fileName, Callback countCallback) {
Count count = new Count();
File file = new File(fileName);
if(!file.exists()) {
countCallback.onError("文件不存在,请重试");
return;
}
BufferedReader reader = null;
FileReader fileReader = null;
try {
fileReader = new FileReader(file);
reader = new BufferedReader(fileReader);
String line;
while ( null != (line = reader.readLine())){
if(isCountLine)
count.lineCount = count.lineCount + addLineCount();
if(isCountWord)
count.wordCount = count.wordCount + getWorkCount(line);
if(isCountChar)
count.charCount = count.charCount + getCharCount(line);
if(isCountComplexLine) {
count.codeLineCount = count.codeLineCount + addCodeLine(line);
count.blankLineCount = count.blankLineCount + addBlankLine(line);
count.commentLineCount = count.commentLineCount + addCommentLine(line);
}
}
countCallback.onSuccess(count, fileName);
} catch (IOException e) {
countCallback.onError("文件读取出错,请重试");
} finally {
FileUtil.closeIOs(fileReader, reader);
}
}单文件统计,IO打开文件并逐行读取并统计数据。
/**
* 并发统计多文件
* @param fileName
*/
private void countMultiFile(String fileName) {
File directory = new File(""); //设定为当前文件夹
List<String> files = new ArrayList<>();
FileUtil.findFiles(directory.getAbsolutePath(), fileName, files);
//得到文件集合后,并发处理,提高效率
if(files.size() == 0) {
System.out.println("无法匹配到适合的文件");
return;
}
for (String name: files) {
executor.execute(() -> countSingleFile(name, new CountResult(this)));
}
//开启线程池执行任务后,关闭线程池释放资源
executor.shutdown();
try {
boolean loop = true;
while (loop) {
loop = !executor.awaitTermination(2, TimeUnit.SECONDS); //超时等待阻塞,直到线程池里所有任务结束
} //等待所有任务完成
} catch (InterruptedException e) {
e.printStackTrace();
}
}为了提高效率,并发处理多文件统计,把每个文件统计放入线程池的线程中执行,最后等待文件统计结束后Main线程等待防止子线程未完成就结束了。
功能实现:
-c 统计文件字符数
private int getCharCount(String line) {
//空行算一个字符:“\n”
if(line.isEmpty()) {
return 1;
}
return line.length() + System.lineSeparator().length();
}-l 统计文件行数
private int addLineCount() {
return 1;
}-w 统计文件单词数
private int getWorkCount(String line) {
//把所有除了字母以外的字符都去掉
line = line.replaceAll("[^a-zA-Z]", " ");
//把多于两个以上的空格全部转化为一个空格
line = line.replaceAll("\\s+"," ");
//去掉首部和尾随的空格
line = line.trim();
//用空格分隔单词
String[] words = line.split("[\\s+,.]");
//如果为空行,则返回0
if(words[0].equals("")) {
return 0;
}
return words.length;
}-a 统计文件空行,代码行,注释行
/**
* 判断是否是代码行,是则返回1
*/
private int addCodeLine(String line) {
if(addBlankLine(line) == 0 && addCommentLine(line) == 0) {
return 1;
}
return 0;
}
/**
* 判断是否是空白行,如果包括代码,则只有不超过一个可显示的字符,例如“{”。
*/
private int addBlankLine(String line) {
if(line.isEmpty()) return 1;
if(!line.matches("[a-zA-Z]") && (line.trim().equals("{") || line.trim().equals("}"))) {
return 1;
}
return 0;
}
/**
* 判断是否是注释行,是则返回1
*/
private int addCommentLine(String line) {
line = line.trim();
//匹配“//”单行注释或“} //”情况
if(line.matches("}*\\s+//?.+")) {
return 1;
}
//匹配“/**/”和“/** * */”的情况
if(line.matches("((//?.+)|(/\\*+)|((^\\s)*\\*.+)|((^\\s)*\\*)|((^\\s)*\\*/))+")) {
return 1;
}
return 0;
}递归文件匹配查询(通配符查询)
/**
* 递归查找匹配的文件
* @param dirName 某个目录下
* @param fileName 待匹配的文件(可带通配符)
* @param files 存放匹配成功的文件名
*/
public static void findFiles(String dirName, String fileName, List<String> files) {
String tempName;
//判断目录是否存在
File baseDir = new File(dirName);
if (!baseDir.exists() || !baseDir.isDirectory()){
System.out.println("找不到该目录:" + dirName );
} else {
String[] fileList = baseDir.list();
if(fileList == null) return;
for (String s : fileList) {
File readFile = new File(dirName + "\\" + s);
if (!readFile.isDirectory()) {
tempName = readFile.getName();
if (wildcardMatch(fileName, tempName)) {
//匹配成功,将文件名添加到文件列表中
files.add(readFile.getAbsoluteFile().getAbsolutePath());
}
} else if (readFile.isDirectory()) {
findFiles(dirName + "\\" + s, fileName, files);
}
}
}
}
/**
* 通配符匹配(参考网上)
* @param pattern 通配符模式
* @param str 待匹配的字符串
* @return 匹配成功则返回true,否则返回false
*/
private static boolean wildcardMatch(String pattern, String str) {
int patternLength = pattern.length();
int strLength = str.length();
int strIndex = 0;
char ch;
for (int patternIndex = 0; patternIndex < patternLength; patternIndex++) {
ch = pattern.charAt(patternIndex);
if (ch == ‘*‘) {
//通配符*表示可以匹配任意多个字符
while (strIndex < strLength) {
if (wildcardMatch(pattern.substring(patternIndex + 1),
str.substring(strIndex))) {
return true;
}
strIndex++;
}
} else if (ch == ‘?‘) {
//通配符?表示匹配任意一个字符
strIndex++;
if (strIndex > strLength) {
return false;
}
} else {
if ((strIndex >= strLength) || (ch != str.charAt(strIndex))) {
return false;
}
strIndex++;
}
}
return (strIndex == strLength);
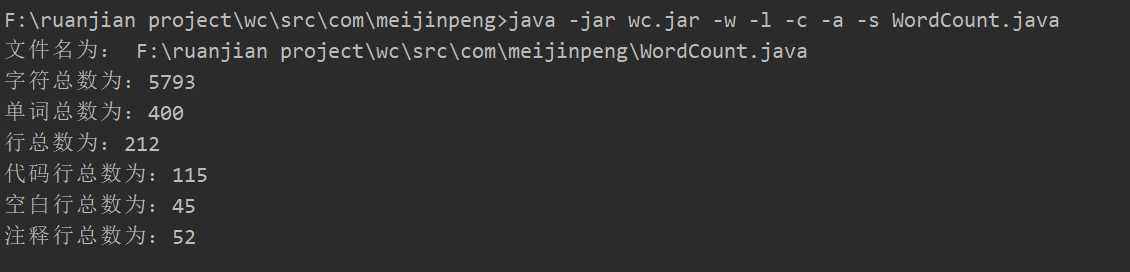
}测试-w , -l -c 功能截图:

测试-a 功能截图:

测试全功能截图:
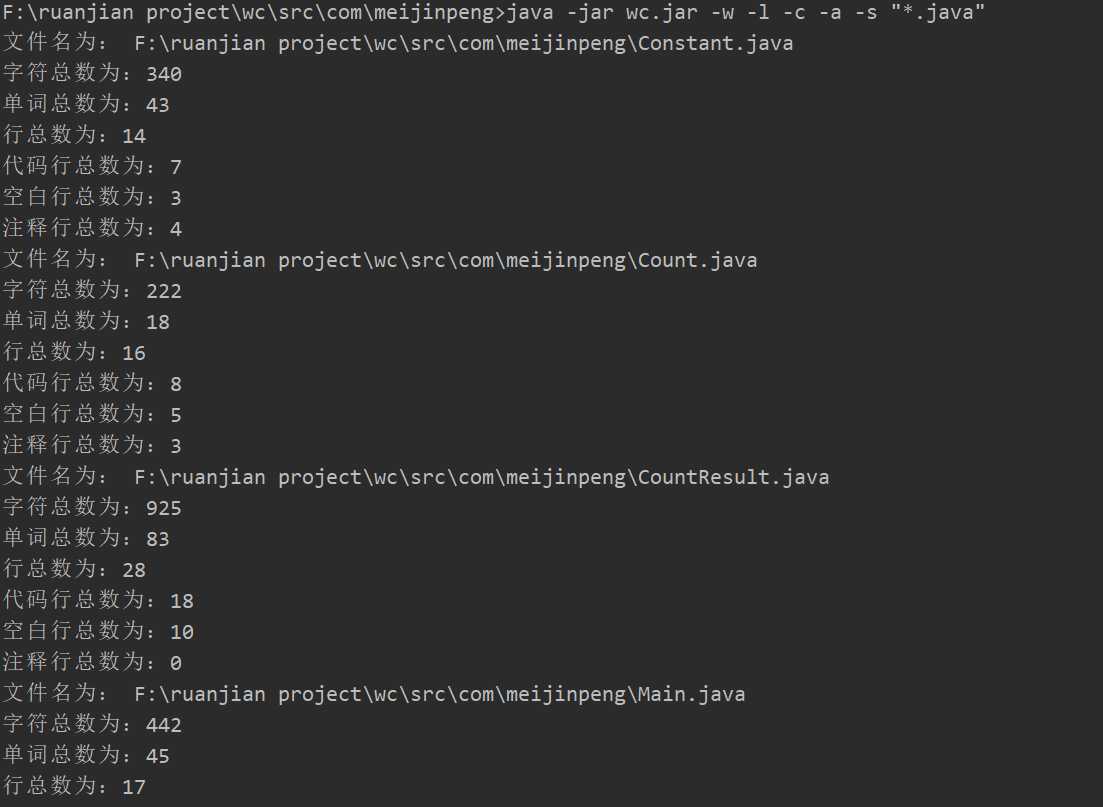
使用测试-w,-l,-c,-a,-s 测试项目下的所有.java文件,测试代码覆盖率如下:
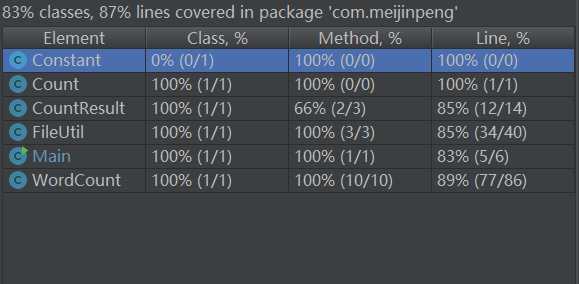

总体来说,该项目受益良多,之前也做过类似的项目,但并没有按照软件工程的操作来做,急于完成需求,导致做出来的项目需要不停的测试与修改,花费的时间更多,但这次合理的规划时间使得该项目能够更快的完成。而且此项目也让我学习到了挺多新东西,比如正则表达式的使用,线程池的使用等,这些都说明要使得技术不断进步,就必须实践多点项目,总结多点项目经验。虽然和计划的对比还是效率不够好,但这是刚刚开始实践这种模式的项目开发,后续可以更快更好的去分配时间开发项目。
标签:private nat comm arraylist rem eve this length 功能实现
原文地址:https://www.cnblogs.com/pmjin/p/9638080.html