标签:ble 学习 hide localhost url pytho range ima upgrade
本次爬取自如网房源信息所用到的知识点:
1. requests get请求
2. lxml解析html
3. Xpath
4. MongoDB存储
1. url: http://hz.ziroom.com/z/nl/z3.html?p=2 的p参数控制分页
2. get请求
1 # -*- coding: utf-8 -*- 2 import requests 3 import time 4 from requests.exceptions import RequestException 5 def get_one_page(page): 6 try: 7 url = "http://hz.ziroom.com/z/nl/z2.html?p=" + str(page) 8 headers = { 9 ‘Referer‘:‘http://hz.ziroom.com/‘, 10 ‘Upgrade-Insecure-Requests‘:‘1‘, 11 ‘User-Agent‘:‘Mozilla/5.0(WindowsNT6.3;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/68.0.3440.106Safari/537.36‘ 12 } 13 res = requests.get(url,headers=headers) 14 if res.status_code == 200: 15 print(res.text) 16 except RequestException: 17 return None 18 def main(): 19 page = 1 20 get_one_page(page) 21 if __name__ == ‘__main__‘: 22 main() 23 time.sleep(1)
1. 解析html文档, 目的: 测试XPath表达式
将获取的源码保存到当前文件夹下的"result.html"中, 然后通过XPath对其进行相应内容的提取, 当然你也可以使用某些在线工具.
1 from lxml import etree 2 #解析html文档 3 html = etree.parse("./resul.html",etree.HTMLParser()) 4 results = html.xpath(‘//ul[@id="houseList"]/li‘) 5 for result in results[1:]: 6 title = result.xpath("./div/h3/a/text()")[0][5:] if len(result.xpath("./div/h3/a/text()")[0]) >5 else "" 7 location = result.xpath("./div/h4/a/text()")[0].replace("[","").replace("]",‘‘) 8 area = " ".join(result.xpath("./div/div/p[1]/span/text()")).replace(" ","",1) #使用join方法将列表中的内容以" "字符连接 9 nearby = result.xpath("./div/div/p[2]/span/text()")[0] 10 print(title) 11 print(location) 12 print(area) 13 print(nearby)
2. 解析源代码
1 from lxml import etree 2 def parse_one_page(sourcehtml): 3 ‘‘‘解析单页源码‘‘‘ 4 contentTree = etree.HTML(sourcehtml) #解析源代码 5 results = contentTree.xpath(‘//ul[@id="houseList"]/li‘) #利用XPath提取相应内容 6 for result in results[1:]: 7 title = result.xpath("./div/h3/a/text()")[0][5:] if len(result.xpath("./div/h3/a/text()")[0]) > 5 else "" 8 location = result.xpath("./div/h4/a/text()")[0].replace("[", "").replace("]", ‘‘) 9 area = " ".join(result.xpath("./div/div/p[1]/span/text()")).replace(" ", "", 1) # 使用join方法将列表中的内容以" "字符连接 10 nearby = result.xpath("./div/div/p[2]/span/text()")[0] 11 yield { 12 "title": title, 13 "location": location, 14 "area": area, 15 "nearby": nearby 16 } 17 def main(): 18 page = 1 19 html = get_one_page(page) 20 print(type(html)) 21 parse_one_page(html) 22 for item in parse_one_page(html): 23 print(item) 24 25 if __name__ == ‘__main__‘: 26 main() 27 time.sleep(1)
1 def parse_one_page(sourcehtml): 2 ‘‘‘解析单页源码‘‘‘ 3 contentTree = etree.HTML(sourcehtml) #解析源代码 4 results = contentTree.xpath(‘//ul[@id="houseList"]/li‘) #利用XPath提取相应内容 5 for result in results[1:]: 6 title = result.xpath("./div/h3/a/text()")[0][5:] if len(result.xpath("./div/h3/a/text()")[0]) > 5 else "" 7 location = result.xpath("./div/h4/a/text()")[0].replace("[", "").replace("]", ‘‘) 8 area = " ".join(result.xpath("./div/div/p[1]/span/text()")).replace(" ", "", 1) # 使用join方法将列表中的内容以" "字符连接 9 #nearby = result.xpath("./div/div/p[2]/span/text()")[0].strip()这里需要加判断, 改写为下句 10 nearby = result.xpath("./div/div/p[2]/span/text()")[0].strip() if len(result.xpath("./div/div/p[2]/span/text()"))>0 else "" 11 yield { 12 "title": title, 13 "location": location, 14 "area": area, 15 "nearby": nearby 16 } 17 print(nearby) 18 #yield {"pages":pages} 19 def get_pages(): 20 """得到总页数""" 21 page = 1 22 html = get_one_page(page) 23 contentTree = etree.HTML(html) 24 pages = int(contentTree.xpath(‘//div[@class="pages"]/span[2]/text()‘)[0].strip("共页")) 25 return pages 26 def main(): 27 pages = get_pages() 28 print(pages) 29 for page in range(1,pages+1): 30 html = get_one_page(page) 31 for item in parse_one_page(html): 32 print(item) 33 34 if __name__ == ‘__main__‘: 35 main() 36 time.sleep(1)
需确保MongoDB已启动服务, 否则必然会存储失败
1 def save_to_mongodb(result): 2 """存储到MongoDB中""" 3 # 创建数据库连接对象, 即连接到本地 4 client = pymongo.MongoClient(host="localhost") 5 # 指定数据库,这里指定ziroom 6 db = client.iroomz 7 # 指定表的名称, 这里指定roominfo 8 db_table = db.roominfo 9 try: 10 #存储到数据库 11 if db_table.insert(result): 12 print("---存储到数据库成功---",result) 13 except Exception: 14 print("---存储到数据库失败---",result)

1 # -*- coding: utf-8 -*- 2 3 import requests 4 import time 5 import pymongo 6 from lxml import etree 7 from requests.exceptions import RequestException 8 def get_one_page(page): 9 ‘‘‘获取单页源码‘‘‘ 10 try: 11 url = "http://hz.ziroom.com/z/nl/z2.html?p=" + str(page) 12 headers = { 13 ‘Referer‘:‘http://hz.ziroom.com/‘, 14 ‘Upgrade-Insecure-Requests‘:‘1‘, 15 ‘User-Agent‘:‘Mozilla/5.0(WindowsNT6.3;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/68.0.3440.106Safari/537.36‘ 16 } 17 res = requests.get(url,headers=headers) 18 if res.status_code == 200: 19 return res.text 20 return None 21 except RequestException: 22 return None 23 def parse_one_page(sourcehtml): 24 ‘‘‘解析单页源码‘‘‘ 25 contentTree = etree.HTML(sourcehtml) #解析源代码 26 results = contentTree.xpath(‘//ul[@id="houseList"]/li‘) #利用XPath提取相应内容 27 for result in results[1:]: 28 title = result.xpath("./div/h3/a/text()")[0][5:] if len(result.xpath("./div/h3/a/text()")[0]) > 5 else "" 29 location = result.xpath("./div/h4/a/text()")[0].replace("[", "").replace("]", ‘‘) 30 area = " ".join(result.xpath("./div/div/p[1]/span/text()")).replace(" ", "", 1) # 使用join方法将列表中的内容以" "字符连接 31 #nearby = result.xpath("./div/div/p[2]/span/text()")[0].strip()这里需要加判断, 改写为下句 32 nearby = result.xpath("./div/div/p[2]/span/text()")[0].strip() if len(result.xpath("./div/div/p[2]/span/text()"))>0 else "" 33 data = { 34 "title": title, 35 "location": location, 36 "area": area, 37 "nearby": nearby 38 } 39 save_to_mongodb(data) 40 #yield {"pages":pages} 41 def get_pages(): 42 """得到总页数""" 43 page = 1 44 html = get_one_page(page) 45 contentTree = etree.HTML(html) 46 pages = int(contentTree.xpath(‘//div[@class="pages"]/span[2]/text()‘)[0].strip("共页")) 47 return pages 48 def save_to_mongodb(result): 49 """存储到MongoDB中""" 50 # 创建数据库连接对象, 即连接到本地 51 client = pymongo.MongoClient(host="localhost") 52 # 指定数据库,这里指定ziroom 53 db = client.iroomz 54 # 指定表的名称, 这里指定roominfo 55 db_table = db.roominfo 56 try: 57 #存储到数据库 58 if db_table.insert(result): 59 print("---存储到数据库成功---",result) 60 except Exception: 61 print("---存储到数据库失败---",result) 62 63 def main(): 64 pages = get_pages() 65 print(pages) 66 for page in range(1,pages+1): 67 html = get_one_page(page) 68 parse_one_page(html) 69 70 if __name__ == ‘__main__‘: 71 main() 72 time.sleep(1)
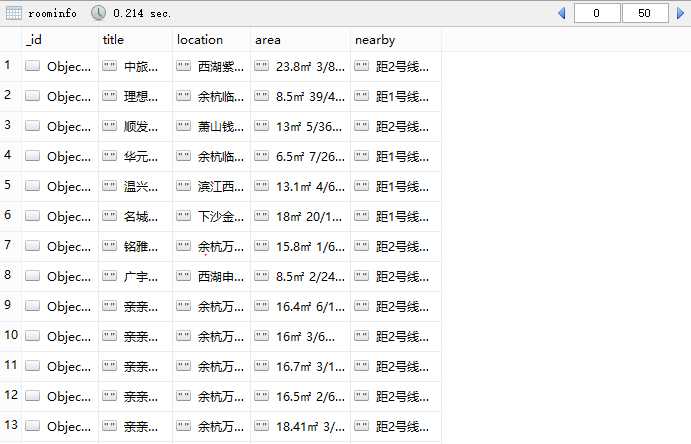
1. 在第三步中XPath使用注意事项
title = result.xpath("./div/h3/a/text()") 此处的点‘.‘不能忘记, 它表示当前节点, 如果不加‘.‘, ‘/‘就表示从根节点开始选取
2. 在第四步获取多个页面时出现索引超出范围错误
nearby = result.xpath("./div/div/p[2]/span/text()")[0].strip() IndexError: list index out of range
造成这种错误原因有两种:
1) [index] index超出list范围
2) [index] index索引内容为空
因为这里的nearby的index是0, 排除第一种情况, 那么这里就是空行了, 加句if判断就可以解决
nearby = result.xpath("./div/div/p[2]/span/text()")[0].strip() #改写以后: nearby = result.xpath("./div/div/p[2]/span/text()")[0].strip() if len(result.xpath("./div/div/p[2]/span/text()"))>0 else ""
以上主要是对爬虫过程学习的总结, 若有不对的地方, 还请指正, 谢谢!
因还在学习中, 价格部分会用到图片识别, 有待完善.
标签:ble 学习 hide localhost url pytho range ima upgrade
原文地址:https://www.cnblogs.com/star-zhao/p/9637588.html
