标签:怎么 for 重要 线程 数组 常用 transient 学习 tle
Java集合框架
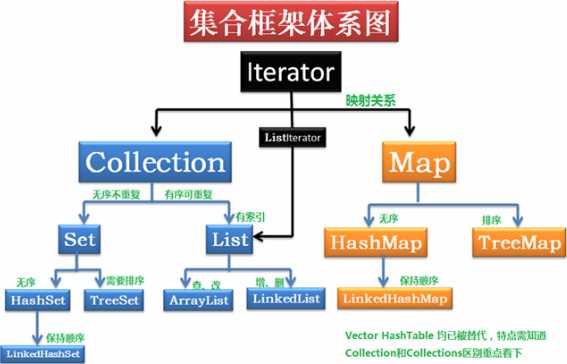
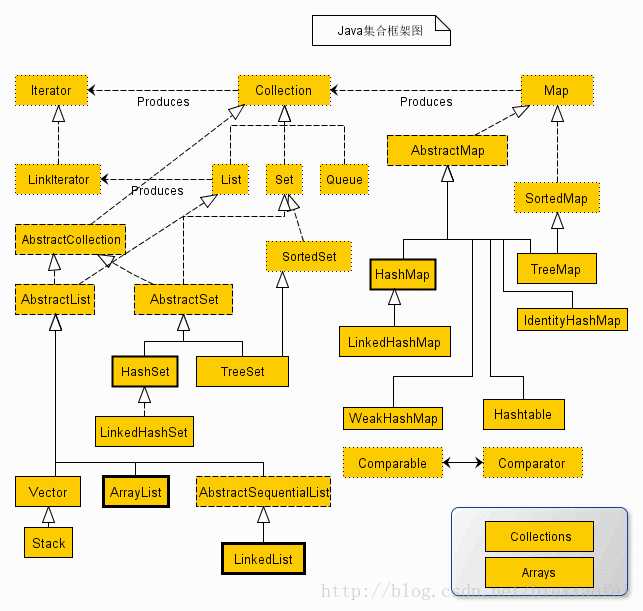
集合的引入:
数组的优势:是一种简单的线性序列,可以快速地访问数组元素,效率高。如果从效率和类型检查的角度讲,数组是最好的。
数组的劣势:不灵活。容量需要事先定义好,不能随着需求的变化而扩容。
泛型:
泛型是JDK1.5以后增加的,它可以帮助我们建立类型安全的集合。在使用了泛型的集合中,遍历时不必进行强制类型转换。JDK提供了支持泛型的编译器,将运行时的类型检查提前到了编译时执行,提高了代码可读性和安全性。

1 package boom.collection; 2 3 /** 4 * 泛型的测试 5 * 6 * @author Administrator 7 * 8 */ 9 public class GenericsTest { 10 11 public static void main(String[] args) { 12 MyCollection <String> mc = new MyCollection<String>(); 13 mc.set("泛型", 0); 14 15 String str = mc.get(0); 16 // 没有加泛型需要强制转型 17 // String str = (String) mc.get(0); 18 // Integer in = (Integer) mc.get(1); 19 20 } 21 22 } 23 24 class MyCollection <E>{ 25 // 定义Object类数组 26 Object[] objs = new Object[5]; 27 28 29 public void set(E e, int index) { 30 objs[index] = e; 31 } 32 33 public E get(int index) { 34 return (E) objs[index]; 35 } 36 }
Collection接口
Collection 表示一组对象,它是集中、收集的意思。Collection接口的两个子接口是List、Set接口。
1、List特点和常用方法
List是有序、可重复的容器。
有序: List中每个元素都有索引标记。可以根据元素的索引标记(在List中的位置)访问元素,从而精确控制这些元素。
可重复:List允许加入重复的元素。更确切地讲,List通常允许满足 e1.equals(e2) 的元素重复加入容器。
除了Collection接口中的方法,List多了一些跟顺序(索引)有关的方法
List接口常用的实现类有3个:ArrayList、LinkedList和Vector。
ArrayList查询效率高,增删效率低,线程不安全。我们一般使用它
1 package boom.collection; 2 3 import java.util.ArrayList; 4 import java.util.Collection; 5 import java.util.Iterator; 6 import java.util.List; 7 import java.util.ListIterator; 8 9 /** 10 * 测试collection接口的方法 List接口 11 * 12 * @author Administrator 13 * 14 */ 15 public class ListTest { 16 17 public static void main(String[] args) { 18 //test01(); 19 //test02(); 20 test03(); 21 22 } 23 24 /** 25 * 集合带索引顺序的相关方法 26 */ 27 public static void test03() { 28 List<String> list = new ArrayList<>(); 29 30 // 添加元素 31 list.add("京东"); 32 list.add("阿里"); 33 list.add("腾讯"); 34 list.add("百度"); 35 System.out.println(list);// [京东, 阿里, 腾讯, 百度] 36 37 // 在指定索引位置插入新元素:index[0] 38 list.add(0, "网易"); 39 System.out.println(list);// [网易, 京东, 阿里, 腾讯, 百度] 40 41 // 移除指定位置的元素:index[3] 42 list.remove(3); 43 System.out.println(list);// [网易, 京东, 阿里, 百度] 44 45 // 指定位置更改元素:index[0] 46 list.set(0,"Google"); 47 System.out.println(list);// [Google, 京东, 阿里, 百度] 48 // 获得更改的元素 49 System.out.println(list.get(0));// Google 50 51 52 list.add("阿里"); 53 System.out.println(list);// [Google, 京东, 阿里, 百度, 阿里] 54 // 顺序查找(角标0开始)指定的元素下标 55 System.out.println(list.indexOf("阿里"));// 2 56 // 从后往前找 57 System.out.println(list.lastIndexOf("阿里"));// 4 58 59 60 } 61 62 /** 63 * ArrayList_操作多个List_并集和交集及两个list之间操作元素 64 */ 65 public static void test02() { 66 List<String> list01 = new ArrayList<String>(); 67 list01.add("AAA"); 68 list01.add("BBB"); 69 list01.add("CCC"); 70 71 List<String> list02 = new ArrayList<String>(); 72 list02.add("DDD"); 73 list02.add("CCC"); 74 list02.add("EEE"); 75 76 // 打印list01集合元素内容 77 System.out.println(list01); // [AAA, BBB, CCC] 78 79 // 把list02集合里所有的元素都添加到list01集合里:在末尾进行添加 80 list01.addAll(list02); 81 System.out.println(list01); // [AAA, BBB, CCC, DDD, CCC, EEE] 82 83 // 把list02集合里的所有元素添加到01集合里指定的位置,根据索引 84 list01.addAll(2, list02); 85 System.out.println(list01);// [AAA, BBB, DDD, CCC, EEE, CCC, DDD, CCC, EEE] 86 87 // 01集合里是否包含02集合的所有元素 :true or false 88 System.out.println(list01.contains(list02)); // false 89 90 91 // 先进行打印,方便看效果 92 System.out.println("list01:"+list01); // list01:[AAA, BBB, DDD, CCC, EEE, CCC, DDD, CCC, EEE] 93 System.out.println("list02:"+list02); // list02:[DDD, CCC, EEE] 94 95 //移除集合01和集合02中都包含的元素,返回01集合 96 //list01.removeAll(list02); 97 //System.out.println(list01);// [AAA, BBB] 98 99 // 取本集合01和集合02中都包含的元素,移除非交集元素,返回01集合 100 list01.retainAll(list02); 101 System.out.println(list01); // [DDD, CCC, EEE, CCC, DDD, CCC, EEE] 102 103 } 104 105 /** 106 * List接口常用方法 107 */ 108 public static void test01() { 109 List<String> list = new ArrayList<String>(); 110 // 判断集合是否为空 111 System.out.println(list.isEmpty());// true 112 113 // 添加add,按下标顺序添加 114 list.add("国产001"); 115 list.add("国产002"); 116 list.add("国产003"); 117 118 System.out.println(list.isEmpty());// false 119 120 // 打印 list自动调用toString方法 121 System.out.println(list.toString()); // [国产001, 国产002, 国产003] 122 System.out.println("集合的长度:" + list.size());// 集合的长度:3 123 124 // 指定位置索引添加元素 125 list.add(0, "new");// 在下标0的位置添加新元素 "new" 126 System.out.println(list); // [new, 国产001, 国产002, 国产003] 127 128 // 移除 129 list.remove(0);// 移除下标为0的元素 130 System.out.println(list);// [国产001, 国产002, 国产003] 131 132 // 根据下标修改某个元素的值 133 // index[1]的位置更改为 "改" 134 list.set(1, "改"); 135 System.out.println(list);// [国产001, 改, 国产003] 136 137 // 测试集合是否包含指定的元素:true or false 138 System.out.println("是否包含指定元素:" + list.contains("国产"));// false 139 System.out.println("是否包含指定元素:" + list.contains("国产003"));// true 140 141 // 清空集合所有的元素 142 list.clear(); 143 System.out.println("清空所有元素:" + list); // 清空所有元素:[] 144 145 } 146 }
运行效果参照图: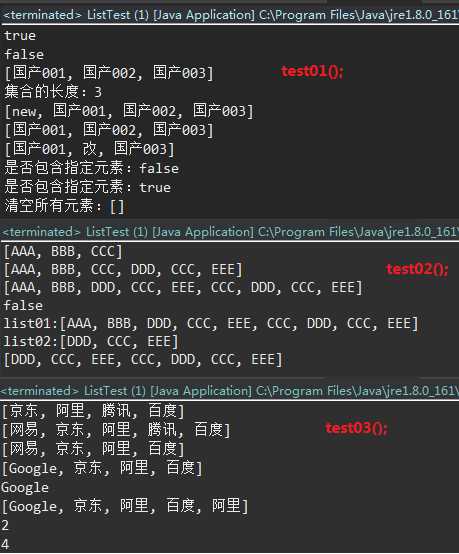
ArrayList_底层JDK源码解读
ArrayList底层是用数组实现的存储。 特点:查询效率高,增删效率低,线程不安全。我们一般使用它。
1、数组长度是有限的,而ArrayList是可以存放任意数量的对象,长度不受限制。
2、那么它是怎么实现的呢?
本质上就是通过定义新的更大的数组,将旧数组中的内容拷贝到新数组,来实现扩容。 ArrayList的Object数组初始化长度为10,如果我们存储满了这个数组,需要存储第11个对象,就会定义新的长度更大的数组,并将原数组内容和新的元素一起加入到新数组中。
LinkedList:底层用双向链表实现的存储。特点:查询效率低,增删效率高,线程不安全。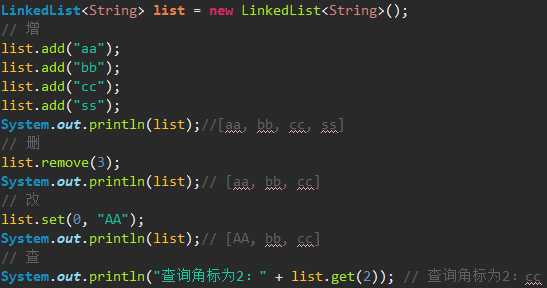
Vector:Vector底层是用数组实现的List,相关的方法都加了同步检查,因此“线程安全,效率低”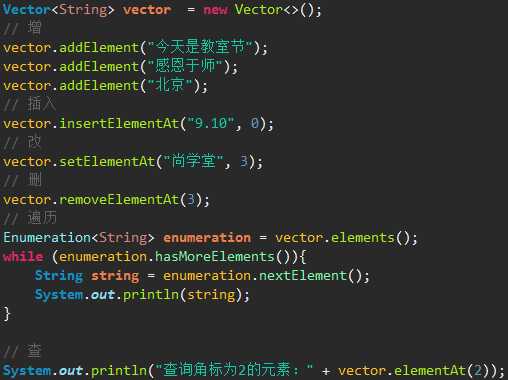
2、Set接口继承自Collection,Set接口中没有新增方法,方法和Collection保持完全一致。我们在前面通过List学习的方法,在Set中仍然适用。
Set容器特点:无序、不可重复。无序指Set中的元素没有索引,我们只能遍历查找;不可重复指不允许加入重复的元素。更确切地讲,新元素如果和Set中某个元素通过equals()方法对比为true,则不能加入;甚至,Set中也只能放入一个null元素,不能多个。
Set常用的实现类有:HashSet、TreeSet等,我们一般使用HashSet。
HashSet:采用哈希算法实现,底层实际是用HashMap实现的(HashSet本质就是一个简化版的HashMap),因此,查询效率和增删效率都比较高。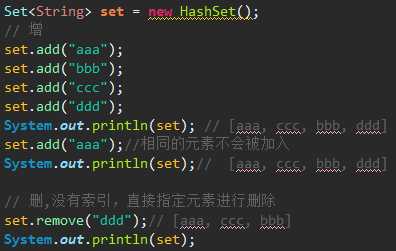
TreeSet:底层实际是用TreeMap实现的,内部维持了一个简化版的TreeMap,通过key来存储Set的元素。
(1) 由于是二叉树,需要对元素做内部排序。 如果要放入TreeSet中的类没有实现Comparable接口,则会抛出异常:java.lang.ClassCastException。
(2) TreeSet中不能放入null元素。
Map接口
Map就是用来存储“键(key)-值(value) 对”的。 Map类中存储的“键值对”通过键来标识,所以“键对象”不能重复。
Map 接口的实现类有HashMap、TreeMap、HashTable、Properties等。
HashMap和HashTable
HashMap采用哈希算法实现,是Map接口最常用的实现类。 由于底层采用了哈希表存储数据,我们要求键不能重复,如果发生重复(是否重复通过equals方法),新的键值对会替换旧的键值对。特点:HashMap在查找、删除、修改方面都有非常高的效率。
HashTable类和HashMap用法几乎一样,底层实现几乎一样,只不过HashTable的方法添加了synchronized关键字确保线程同步检查,效率较低。
HashMap与HashTable的区别
1. HashMap: 线程不安全,效率高。允许key或value为null。
2. HashTable: 线程安全,效率低。不允许key或value为null。
example
1 package boom.collection; 2 3 import java.util.HashMap; 4 import java.util.Map; 5 6 /** 7 * 测试HashMap 8 * @author Administrator 9 * 10 */ 11 public class MapTest { 12 13 public static void main(String[] args) { 14 Map<Integer, String> map = new HashMap<>(); 15 // Object put(Object key,Object value)存放键值对 16 map.put(1, "百度"); 17 map.put(2, "阿里"); 18 map.put(3, "京东"); 19 map.put(4, "删除"); 20 // Object get(Object key) 通过键值对找到值对象 21 System.out.println(map.get(1)); 22 23 // Object remove(Object key) 通过键对象删除对应的键值对 24 System.out.println("删除Key为3的键值对:" + map.remove(4)); 25 System.out.println(map); 26 27 // 键值对的数量 28 System.out.println("包含键值对的数量:" + map.size()); 29 30 // 判断是为空 31 System.out.println("Map是否为空:" + map.isEmpty()); 32 33 Map<Integer, String> map2 = new HashMap<>(); 34 map2.put(4,"网易"); 35 map2.put(5,"Google"); 36 // 将map2里所有的键值对添加到map对象里 37 map.putAll(map2); 38 System.out.println(map); 39 40 41 System.out.println("map里是否包含键对象对应的键值对" + map.containsKey(3)); 42 System.out.println("map2里是否包含值对象对应的键值对" + map2.containsValue("BiaDu")); 43 44 // 存放重复的测试:新的会替换就的键值对 ,是否重复是通过equals判断 45 map.put(1, "Google"); 46 System.out.println(map); 47 } 48 }
HashMap底层实现详解?????
HashMap底层实现采用了哈希表,这是一种非常重要的数据结构。
TreeMap使用和底层原理_Comparable接口_HashTable特点(HashTable: 线程安全,效率低。不允许key或value为null。)
TreeMap是红黑二叉树的典型实现。我们打开TreeMap的源码,发现里面有一行核心代码:private transient Entry<K,V> root = null;
root用来存储整个树的根节点。我们继续跟踪Entry(是TreeMap的内部类)的代码:
TreeMap和HashMap实现了同样的接口Map,用法对于调用者来说没有区别。HashMap效率高于TreeMap;在需要排序(comparable)的Map时才选用TreeMap。
example
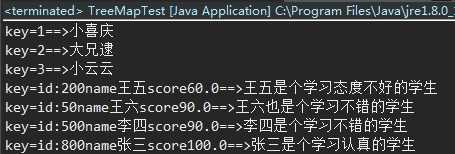
1 package boom.collection; 2 /** 3 * TreeMap测试 4 */ 5 import java.util.Map; 6 import java.util.TreeMap; 7 8 /** 9 * 10 * @author Administrator 11 * 12 */ 13 public class TreeMapTest { 14 15 public static void main(String[] args) { 16 Map<Integer, String> treemap1 = new TreeMap<>(); 17 treemap1.put(002, "大兄逮"); 18 treemap1.put(003, "小云云"); 19 treemap1.put(001, "小喜庆"); 20 21 // 遍历 增强for 按照key递增的方式排序 22 for (Integer key : treemap1.keySet()) { 23 System.out.println("key=" + key + "==>" + treemap1.get(key)); 24 } 25 26 // 看comparable比较效果 27 Map<Student, String> map = new TreeMap<>(); 28 map.put(new Student(800, "张三", 100), "张三是个学习认真的学生"); 29 map.put(new Student(500, "李四", 90), "李四是个学习不错的学生"); 30 map.put(new Student(200, "王五", 60), "王五是个学习态度不好的学生"); 31 map.put(new Student(50, "王六", 90), "王六也是个学习不错的学生"); 32 33 for (Student key : map.keySet()) { 34 System.out.println("key=" + key + "==>" + map.get(key)); 35 } 36 37 } 38 } 39 // 自定义排序comparable,按照学生的分数进行排序 40 class Student implements Comparable<Student>{ 41 int id; 42 String name; 43 double score; 44 45 public Student(int id, String name, double score) { 46 super(); 47 this.id = id; 48 this.name = name; 49 this.score = score; 50 } 51 52 // 实现comparable方法 53 @Override 54 public int compareTo(Student o) {// 负数:小于,0:等于,整数:大于 55 /** 56 * 按照score递增进行排序[递减把比较符号倒置即可] 如:if (this.score < o.score) 57 */ 58 59 if (this.score > o.score) { 60 return 1; 61 } else if (this.score < o.score) { 62 return -1; 63 } else { 64 // 分数相同的按照id进行比较 65 if (this.id > o.id) { 66 return 1; 67 } else if (this.id < o.id) { 68 return -1; 69 } else { 70 // id相同的情况下,就说明是同一个人 71 return 0; 72 } 73 } 74 } 75 76 // 重写toString方法 77 @Override 78 public String toString() { 79 return "id:" + id + "name" + name + "score" + score; 80 } 81 82 }
标签:怎么 for 重要 线程 数组 常用 transient 学习 tle
原文地址:https://www.cnblogs.com/cao-yin/p/9608250.html
