标签:赋值 逻辑运算符 block 帮助信息 工程 更改 line 交换 put
学习一门编程语言,通常是学习该语言的以下几个部分的内容:
掌握上面的内容,就算是对一门编程语言入门了,剩下的就是不断的在使用和总结中去提升了。本节我们先来说一说学习Python时的准备工作以及Python的基础语法。
在任意一个目录下创建一个hello.py文件,我们来输出一个经典语句"Hello World!"
print("Hello, World")执行hello.py这个python脚本的方式是:
python hello.py
输出为:
Hello, World
当然也可以直接进入python解释器交互式终端去执行print("Hello, World"),如下图所示:
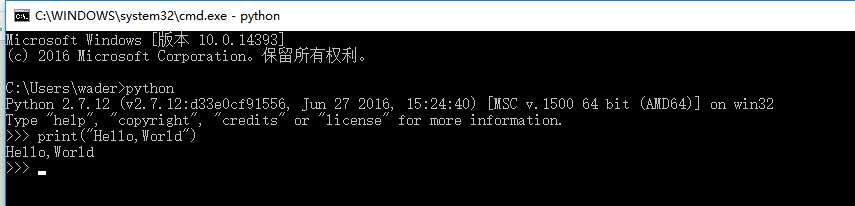
思考:为什么打印一句“Hello World”已经成为很多人学习一门新语言的第一句代码?
有人说,这是学习一门语言入门的象征,因为写完了这个我就可以对别人说“我会写xx语言的程序了”。本人认为要理解为什么Hello World如此简单,却又如此广为人知并被传颂,只需要想清楚一个问题:这个程序带给我们什么?
它告诉我们在这个编程语言中基本的输出语句是怎样的,这很重要;
它告诉我们要怎样去执行这个编程语言编写的程序,这同样很重要。
如果不知道上述两个问题,我们将寸步难行。
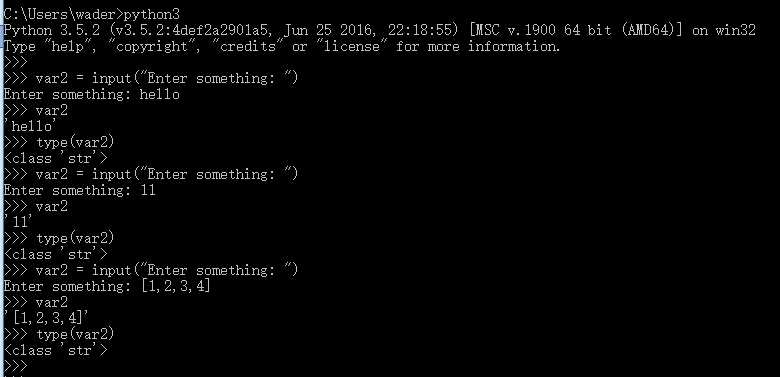
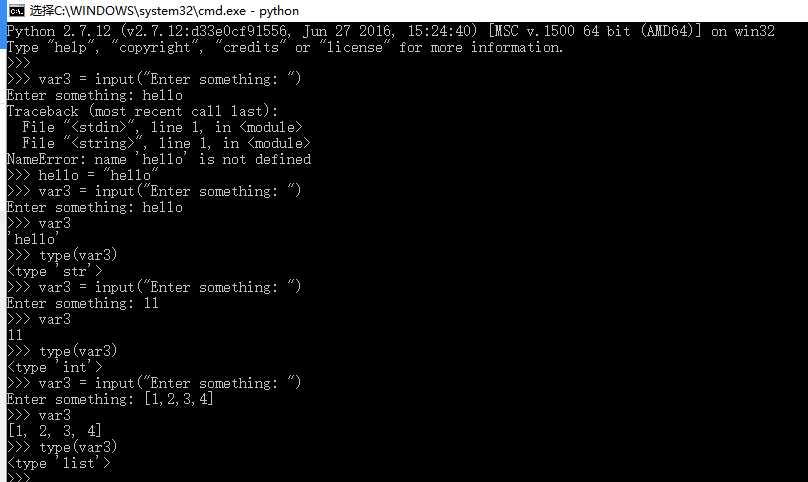
我们分别使用Python2.7 和 Python3.5的解释器提供的交互式终端来分别执行以下两条指令:
print("Hello, World")
print "Hello, World"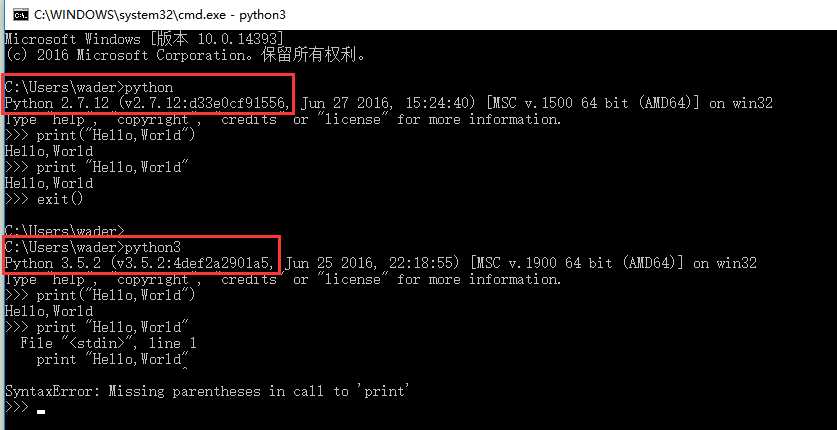
通过上图的执行结果会发现,print "Hello, World" 这条语句在Python2.7中可以正常执行,而在Python 3.5中会报错,也就是说Python 3.x与Python 2.x是不兼容的。这貌似是Python开发者犯的一个错误,而事实是Guido Van Rossum(Python语言的最初创建者)故意为之。Guido的本意就是想不考虑太多向后兼容性的问题,去适当地清理一下Python 2.x中不合理的内容,而不是把Python 3.x简单的当做对Python 2.x的更新版本。
实际上,Python 3.0在2008年12月就已经发布了,Python官方在2010年年中发布2.7时宣布,2.7将是Python 2.x的最后一个主发布版本。其实Python 2.7 是向Python 3.x的一个过渡版本,里面支持了一些Python 3.x的特性。
2014年11月,Python官方宣布Python 2.7将会被支持到2020年,并再次确认了不会有Python 2.8发布,希望用户尽快迁移到Python 3.4+ 。3.x正在处于积极开发状态,并且在过去5年里已经发布了多个稳定版本,包括2012年的3.3,2014年的3.4,2015年的3.5。这意味着最近所有的标准库更新将默认只能在Python 3.x中可用。
在Python 3.x中,输出语句需要使用print()函数,该函数接收一个关键字参数,以此来代替Python 2.x中的大部分特殊语法。下面是几个对比项:
| 目标 | Python 2.x的实现 | Python 3.x的实现 |
|---|---|---|
| 拼接并输出多个值 | print "The result is", 2+3 | print("The result is", 2+3) |
| 打印一个元祖(1,2,3) | print(1,2,3) 或 print (1,2,3) | print((1,2,3)) |
| 输出一个内容并且不换行 | print “Hello”, | print("Hello", end=" ") |
| 输出一个新空白行 | print() | |
| 将输出内容输出到标准错误输出文件 | print >>sys.stderr, "fatal error" | print("fatal error", file=sys.stderr) |
| 自定义多个输出内容之间的分隔/拼接符 | N/A | print("There are <", 2**32, "> possibilites!", sep="") |
Python 2.x中使用的默认字符编码为ASCII码,要使用中文字符的话需要指定使用的字符编码,如UTF-8;Python 3.x中使用的默认字符编码为Unicode,就不存在这个问题了。
python 2.x中如果要给多个变量同时赋值,要求=号右边的表达式返回结果的个数要与=号左边接收值的变量个数相等,不能多,也不能少。如:
a,b,c = (1,2,3) # 正常,a=1, b=2, c=3
a,b,c = range(5) # 报错,ValueError: too many values to unpack
a,b,c,d,e = [1,2,3] # 报错,ValueError: need more than 3 values to unpack python 3.x中允许=号昨边的变量数小于=号右边表达式返回的结果的个数,但是需要有1个且只能有1个字典类型的变量来接收多余的返回值。与python 2.x相同的是 python 3.x中=号左边的变量数也是不能多与=号右边表达式的返回值个数,但是错误提示语更清晰了。
a,b,c = (1,2,3) # 正常,a=1, b=2, c=3
a,*b,c = range(5) # 正常,a=0, b=[1,2,3], c=4
a,b,c,d,e = [1,2,3] # 报错,ValueError: not enough values to unpack (expected 5, got 3)| Old Name | New Name |
|---|---|
| _winreg | winreg |
| ConfigParser | configparser |
| copy_reg | copyreg |
| Queue | queue |
| SocketServer | socketserver |
| markupbase | _markupbase |
| repr | reprlib |
| test.test_support | test.support |
如果是要开发一个新项目,不用考虑与老项目的兼容问题,最好是使用Python 3,因为就像Python官方说的那样,Python 3才是Python语言的将来。现在很多第三方类库已经完成了或者正在积极完成对Python 3的支持,只是有些项目由于过于庞大,很难在短时间内完成。我们需要考虑的最大问题在于,新项目中是否存在必须的第三方类库,且该类库当前还不支持Python 3。如果不存在这个问题,那坚定的选择Python 3吧。
这是只是简单说下Python中变量的定义和使用,方便继续下面的内容。事实上,Python中变量的使用确实很简单:
name = "wader"
age =28
print("Name: ", name,) # Name: wader
print("Age : ", age) # Age : 28python定义变量无需指定变量类型,python解释器会在运行时自动推断变量的数据类型。我们可以通过type()方法来查看变量类型:
type(name) # str
type(age) # int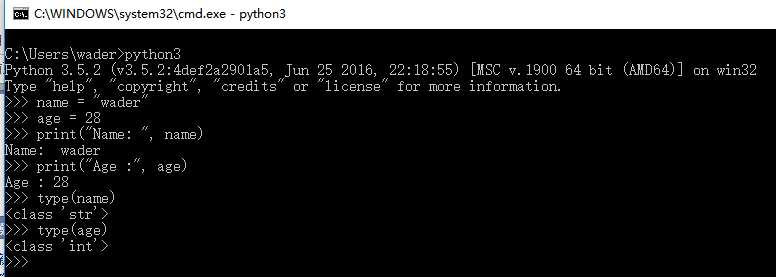
事实上,Python中没有语法约束下的常量,仅仅是用完全大写字母的变量来表示这个变量不应该被改变。
COUNT = 10很多时候都需要与用户进行交互,通过用户输入的内容来做下一步操作。这里需要说明的是,Python 2 与Python 3中接收用户输入的方法是不一样的。
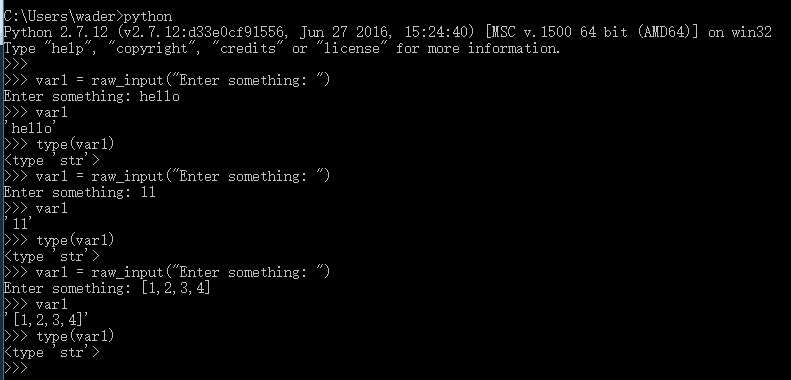
Python 2中接收用户输入时,主要使用的是raw_input()函数:
name = raw_input("Enter your name: ")
print "Your name is ", name
Python 3中接收用户输入时,主要使用的是input()函数:
name = input("Enter your name: ")
print("Your name is ", name)
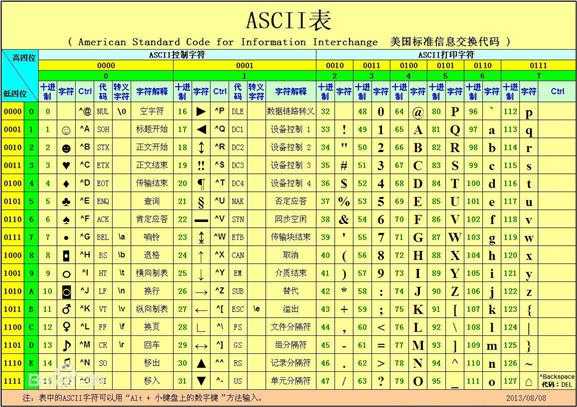
计算机只认识0和1组成的二进制序列,因此任何文件中的内容要想被计算机识别或者想存储在计算机上都需要转换为二进制序列。那么字符与二进制序列怎么进行想换转换呢?于是人们尝试建立一个表格来存储一个字符与一个二进制序列的对应关系。
最早建立这个字符与十进制数字对应的关系的是美国,这张表被称为ASCII码(American Standard Code for Information Interface, 美国标准信息交换代码)。ASCII码是基于拉丁字母的一套电脑编程系统,主要用于显示现代英语和其他西欧语言。它被设计为用1个字节来表示一个字符,所以ASCII码表最多只能表示2**8=256个字符。实际上ASCII码表中只有128个字符,剩余的128个字符是预留扩展用的。
随着计算机的普及和发展,很过国家都开始使用计算机。大家发现ASCII码预留的128个位置根本无法存储自己国家的文字和字符,因此各个国家开始制定各自的字符编码表,其中中国的的字符编码表有GB2312和GBK。
后来随着世界互联网的形成和发展,各国的人们开始有了互相交流的需要。但是这个时候就存在一个问题,每个国家所使用的字符编码表都是不同的。比如我们发送一句“你好,我好喜欢你演的爱情动作电影!”给岛国的仓老师,苍老师电脑上用的是日本的字符编码表,因此她的电脑无法正确显示我们发送的内容。这个时候,人们希望有一个世界统一的字符编码表来存放所有国家所使用的文字和符号,这就是Unicode。Unicode又被称为 统一码、万国码、单一码,它是为了解决传统的字符编码方案的局限性而产生的,它为每种语言中的每个字符设定了统一并且为之一的二进制编码。Unicode规定所有的字符和符号最少由2个字节(16位)来表示,所以Unicode码可以表示的最少字符个数为2**16=65536。
为什么已经有了Unicode还要UTF-8呢?这是由于当时存储设备是非常昂贵的,而Unicode中规定所有字符最少要由2个字节表示。人们认为像原来ASCII码中的字符用1个字节就可以了,因此人们决定创建一个新的字符编码来节省存储空间。UTF-8是对Unicode编码的压缩和优化,它不在要求最少使用2个字节,而是将所有字符和符号进行分类:
UTF-8是目前最常用,也是被推荐使用的字符编码。
我们上面提到过,一般在两个地方会用到字符编码:
磁盘写入或读取数据时使用的字符编码是由编辑器指定的工程或文件的字符编码决定的,这与Python解释器是无关的;但是Python程序执行时,将Python脚本文件加载到内存时所使用的字符编码是主要问题所在。在Python 2中,Python解释器默认使用的是ASCII码,此时如果要运行的程序中如果有中文Python解释器就会报错。
print("你好,世界")SyntaxError: Non-ASCII character ‘\xe4‘ in file C:/Users/wader/PycharmProjects/LearnPython/day01/code.py on line 1, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
这是因为Python解释器执行该程序时试图从ASCII编码表中查找中文字符对应的二进制序列,但是发现找不到。此时要想该程序正常运行,就需要在python脚本文件的开始位置声明该文件的所使用的字符编码:
# -*- coding:utf-8 -*-
print("你好,世界")需要说明的是:
Python 3的解释器默认使用Unicode编码,它本身是可以对中文字符进行编码和解码的,所以即便不指定字符编码也能正常运行,但是还是建议保留字符编码的声明。
通常python脚本都是跑在Linux上的,为了让python脚本文件可以像shell脚本那样可以直接调用执行,我们通常需要在python文件最开始的位置指定python解释器:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
print("你好,世界")不建议写python解释器的绝对路径,如:
#!/usr/bin/python
# -*- coding:utf-8 -*-
print("你好,世界")因为这样写的话,将来要想更换python解释器是非常麻烦的。
关于注释,有两个原则:
块注释,顾名思义,应该是对一个代码块的注释。显然,对某个代码块的注释信息应该写在这个代码块的前面,并且缩进到与该代码块相同的级别。块注释的每一行都要以#号加上单个空格开始(注释中的缩进文本除外):
# 计算变量a与变量b的和
# 然后打印计算值
a = 10
b = 20
sum = a + b
print("sum: %d" % sum)说明: Python中的单行注意与多行注意都是以# 号来标识的。如果注释信息只有一行,则为单行注释;如果注释信息有多行,则为多行注释。另外如果多行注释中有多个段落,则段落之间可以以一个#加单个空格的空注释行隔开。
如果要注释的代码块只有一行代码,且注释信息也很短,也可以把直接注释要写在代码的后面,这就是 行内注释 。行内注释要求代码与#号之间至少要有2个空格,同时#号与注释内容之间至少要有1个空格。
print("你好,世界") # 打印一行文本另外,行内注释并不被推荐使用。
文档字符串通常用来为某个模块、函数、类或方法提供比注释更详细的使用说明、注意事项、使用用例等帮助信息。文档字符串以三个引号(单引号和双引号都可以,通常都使用双引号)将字符串包起来。由于文档字符串表现形式类似于Python的多行字符串,因此很多人把它当做Python中的多行注释来用。
PEP 276 中对“什么是好的文档字符串的书写格式”进行了一些定义:
来看下Python 3中一些内置函数的文档字符串实例:
def print(self, *args, sep=‘ ‘, end=‘\n‘, file=None): # known special case of print
"""
print(value, ..., sep=‘ ‘, end=‘\n‘, file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments:
file: a file-like object (stream); defaults to the current sys.stdout.
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
flush: whether to forcibly flush the stream.
"""
pass
def ord(*args, **kwargs): # real signature unknown
""" Return the Unicode code point for a one-character string. """
pass
def exit(*args, **kwargs): # real signature unknown
pass当Python内置的核心模块提供的功能无法满足我们的需求时就需要导入外部模块,而导入模块的功能有两种方式:
例如,要想查看或更改python查找模块的路径列表就需要使用sys模块下的path变量;若需要执行系统命令可以使用os模块下的system()方法。
import sys
from os import system
print(sys.path)
print(system("ping www.baidu.com"))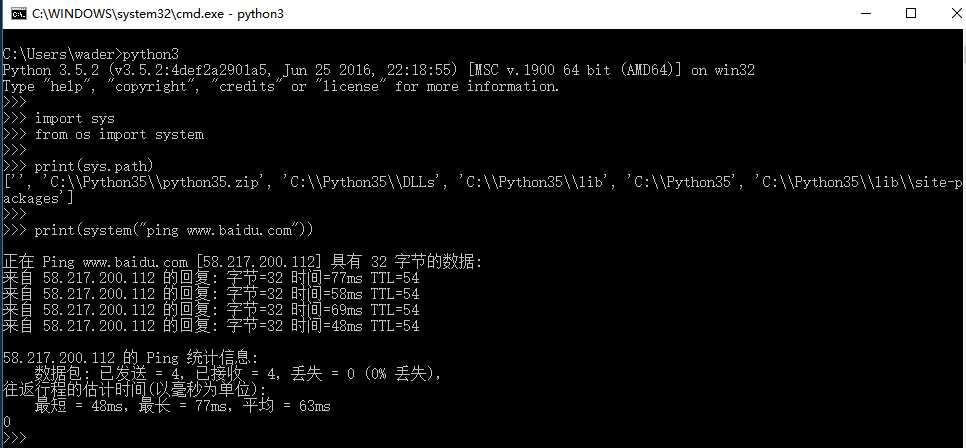
我们在写shell脚本时,经常会通过接受执行脚本时传入的变量来做相应的操作,来保证脚本的灵活性。比如我们要写一个脚本来调用ping命令对指定的域名进行ping测试,这时候显然将域名当做参数传递给脚本要比把域名写死在脚本中灵活的多。shell中可以只用$1,$2这样的特殊变量来获取传入的参数,而python中需要用sys模块下的argv变量来获取。
sys.argv是一个列表,与shell相同,其第一个元素是当前脚本的名称,之后才是传入的参数。
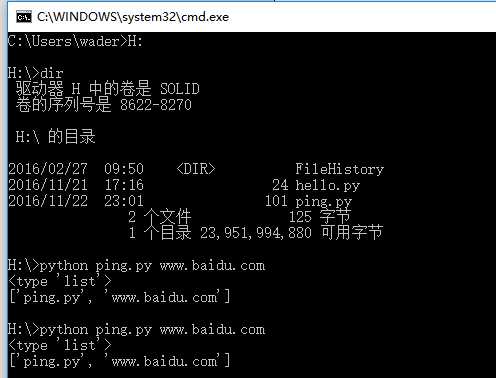
编写一个ping.py,内容如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import sys
import os
print(type(sys.argv))
print(sys.argv)执行该脚本,结果如下图所示:
在Java和C语言中用花括号{}包起来的部分就是一个代码块,shell脚本中的代码块是由专门的开始和结束标识的,而python中的代码块是靠“缩进对齐”来表示的。下面我们分别一个if-else的条件判断来对这几个语言的代码块表示方式做一个对比:
...
int a = 3;
int b = 5;
int big_num;
if(a > b){
big_num = a;
}else{
big_num = b;
}
System.out.println(big_num)
...declare -i a=3
declare -i b=5
declare -i big_num
if [ $a -gt $b ];then
big_num=$a
else
big_num=$b
fi
echo $big_numa = 3
b = 5
if a > b:
big_num = a
else:
big_num = b
print(big_num)在之前的文章我们已经解释过:Python是一个动态的、强类型的、解释型的编程语言。而实际上,解释型语言与编译型语言的界限正在变得模糊。包括Python在内的很多高级编程语言,会将源代码先编译成特定类型的中间代码,然后再由解释器去执行,这样可以提高执行效率。Python的解释器同时也是生成Python中间代码的编译器,.pyc文件就是存放Python中间代码的文件。执行Python代码时,如果该源码文件导入了其他的.py文件,那么执行过程中会自动生成一个与导入的.py文件同名的.pyc文件。
标签:赋值 逻辑运算符 block 帮助信息 工程 更改 line 交换 put
原文地址:https://www.cnblogs.com/langqi250/p/9651824.html