标签:append lex test 表达 inf imp 循环 inter turn
(1)迭代器协议
字符串、元组、列表、字典、集合、文件对象这些都不是可迭代对象,只不过在for循环中,调用了他们内部的__iter__方法,把他们变成了可迭代对象
然后for循环调用可迭代对象的的__next__方法去取值,而且for循环会捕捉StopIateration异常,以终止迭代
x=‘hello’
for i in x: print(i)
for循环相当于:
x=‘hello‘ iter_test=x.__iter__() print(iter_test) print(iter_test.__next__())
相当于:
x=‘hello‘
iter_1=x.__iter__()
print(next(iter_1))
遵循迭代器协议的对象叫做可迭代对象,即iter_1是一个可迭代对象;next()函数:就是在调用iter_l.__next__()
(2)生成器
生成器就是一种数据类型,这种数据类型自动实现了迭代器协议(其他的数据类型需要调用自己内置的__inter__()方法),生成器就是可迭代对象
生成器函数:使用yield语句而不是return语句返回结果
(3)三元表达式:
条件成立时的返回值(可做函数处理) 条件 条件不成立时的返回值(可做函数处理)
name=‘wangqiang‘ # name=‘quyao‘ res=‘男生‘ if name == ‘wangqiang‘ else ‘nvsheng‘ print(res)
三元表达式可以只有两元,但不能是四元及其以上
(4)列表解析
egg_list=[] for i in range(10): egg_list.append(‘鸡蛋%s‘ %i) print(egg_list)
输出结果为:[‘鸡蛋0‘, ‘鸡蛋1‘, ‘鸡蛋2‘, ‘鸡蛋3‘, ‘鸡蛋4‘, ‘鸡蛋5‘, ‘鸡蛋6‘, ‘鸡蛋7‘, ‘鸡蛋8‘, ‘鸡蛋9‘]
用列表解析的方法:
l=[‘鸡蛋%s‘ %i for i in range(10)] print(l)
列表解析的缺点是,生成的列表是放在内存中,处理数据较大时占内存空间较大
LMJ=(‘鸡蛋%s‘ %i for i in range(10)) #生成器表达式 print(LMJ) print(LMJ.__next__()) print(LMJ.__next__()) print(next(LMJ))
其中将列表[‘鸡蛋%s‘ %i for i in range(10)]转换成生成器表达式即LMJ=(‘鸡蛋%s‘ %i for i in range(10)),本身变成一个可迭代对象,next(LMJ)和LMJ.__next__()实现的功能相同
总结:
1.把列表解析的[]换成()得到的就是生成器表达式
2.列表解析和生成器表达式都是一种便利的编程方式,只不过生成器表达式更节省内存
(5)深浅拷贝
==>浅copy:只copy第一层,列表,字典类型copy内容改变,原内容也会改变
a=[[1,2],3,4] b=a[:] #相当于b=a.copy() b[1]=‘alex‘ print(b) print(a)
运行结果为:
[[1, 2], ‘alex‘, 4]
[[1, 2], 3, 4]
拷贝和修改的过程如下:
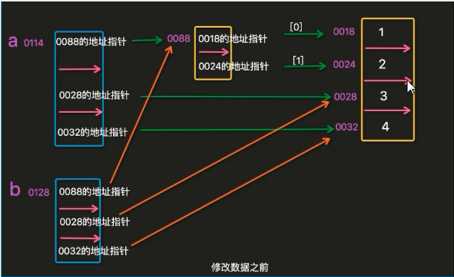
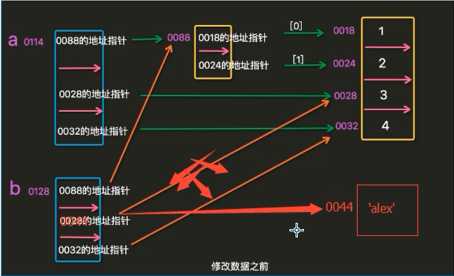
此时由于a[1]的地址指针没有修改,故列表a不发生变化
a=[[1,2],3,4] b=a[:] #相当于b=a.copy() b[0][0]=8 print(b) print(a)
运行结果为:
[[8, 2], 3, 4]
[[8, 2], 3, 4]
拷贝和修改的过程如下:
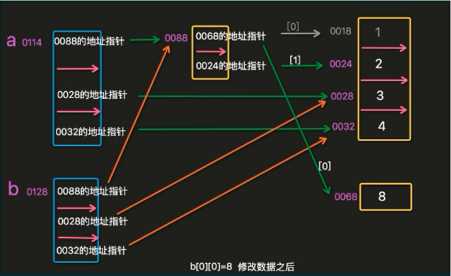
此时,列表a中第一个元素的第一位的地址指针发生改变,故列表a和列表b同时发生变化
==>深copy:克隆一份(需要单独的一个模块来进行,这个模块叫做copy)
import copy a=[[1,2],3,4] b=copy.deepcopy(a) b[0][0]=8 print(b) print(a)
运行结果为:
[[8, 2], 3, 4]
[[1, 2], 3, 4]
此时,列表a不会发生变化
标签:append lex test 表达 inf imp 循环 inter turn
原文地址:https://www.cnblogs.com/quyao/p/9656538.html