标签:grep 个人 查看 技术分享 技术 设备文件 映射 内置变量 shell实例
Shell本身是一个用C语言编写的程序,它是用户使用Unix/Linux的桥梁,用户的大部分工作都是通过Shell完成的。Shell既是一种命令语言,又是一种程序设计语言。作为命令语言,它交互式地解释和执行用户输入的命令;作为程序设计语言,它定义了各种变量和参数,并提供了许多在高级语言中才具有的控制结构,包括循环和分支。
它虽然不是Unix/Linux系统内核的一部分,但它调用了系统核心的大部分功能来执行程序、建立文件并以并行的方式协调各个程序的运行。因此,对于用户来说,shell是最重要的实用程序,深入了解和熟练掌握shell的特性极其使用方法,是用好Unix/Linux系统的关键。
Shell有两种执行命令的方式:
交互式(Interactive):解释执行用户的命令,用户输入一条命令,Shell就解释执行一条。
批处理(Batch):用户事先写一个Shell脚本(Script),其中有很多条命令,让Shell一次把这些命令执行完,而不必一条一条地敲命令。
ps:shell有另外一种解释,就是shell 是外壳,可以通过人与Linux之间的一种交互
Unix/Linux上常见的Shell脚本解释器有bash、sh、csh、ksh等,习惯上把它们称作一种Shell。我们常说有多少种Shell,其实说的是Shell脚本解释器。
bash:bash是Linux标准默认的shell。bash由Brian Fox和Chet Ramey共同完成,是BourneAgain Shell的缩写,内部命令一共有40个。
Linux使用它作为默认的shell是因为它有诸如以下的特色:
可以使用类似DOS下面的doskey的功能,用方向键查阅和快速输入并修改命令。
自动通过查找匹配的方式给出以某字符串开头的命令。
包含了自身的帮助功能,你只要在提示符下面键入help就可以得到相关的帮助。
sh:sh 由Steve Bourne开发,是Bourne Shell的缩写,sh 是Unix 标准默认的shell。
ash:ash shell 是由Kenneth Almquist编写的,Linux中占用系统资源最少的一个小shell,它只包含24个内部命令,因而使用起来很不方便。
csh:csh 是Linux比较大的内核,它由以William Joy为代表的共计47位作者编成,共有52个内部命令。该shell其实是指向/bin/tcsh这样的一个shell,也就是说,csh其实就是tcsh。
ksh:ksh 是Korn shell的缩写,由Eric Gisin编写,共有42条内部命令。该shell最大的优点是几乎和商业发行版的ksh完全兼容,这样就可以在不用花钱购买商业版本的情况下尝试商业版本的性能了。
ps:bash是 Bourne Again Shell 的缩写,是linux标准的默认shell ,它基于Bourne shell,吸收了C shell和Korn shell的一些特性。bash完全兼容sh,也就是说,用sh写的脚本可以不加修改的在bash中执行
创建第一个shell脚本:
mkdir shell
cd shell
vi first.sh --> sh代表shell脚本,不加也行
#!/bin/sh等价于#!/bin/bash
#!/bin/bash 告诉系统该脚本用什么解释器执行
echo "Hello Shell" 输入出语句
执行当前文件发现执行不了,是因为缺少权限,所以
chmod a+x first.sh #使脚本具有执行权限
./first.sh #执行脚本
加解释器运行:
/bin/bash ./first.sh
sh ./first.sh
不用赋予脚本执行权限;
不用再脚本第一行加#!/bin/bash,也是外面的生效
1、变量定义
定义变量时,变量名不加美元符号$如:
name=1705
注意:
变量名和等号之间不能有空格
变量名不能以数字、特殊符号开头、bash关键字,可以使用_开头
#!/bin/bash
name=1705 定义变量
2、变量取值
两种方式第一种:
#!/bin/bash
name=1705 定义变量
echo $name 打印变量 $变量
第二种确定变量的界限:
#!/bin/bash
name=1705 定义变量
name=bd1705 重新复制
echo ${name}qianfen 在打印变量的后添加字符串,不能使用+
可以使用”qianfeng” 最常用的方法变量界限${name}qianfen
这里{}这个方式是可选方式,需要识别界限的时候就可以添加
3、变量赋值
第一种:直接赋值
#!/bin/bash
name=1705
name=bd1705
echo $name
第二种:expr命令
可以将四则运算的结果赋值给变量
需要注意:
#!/bin/bash
name=`expr 2 + 2`
echo $name
4、只读变量
使用 readonly 命令可以将变量定义为只读变量,只读变量的值不能被改变。
下面的例子尝试更改只读变量,结果报错:
#!/bin/bash
name=1705
readonly name
name=1708
运行脚本,结果如下:
./readonly: line 4: name: readonly variable。
5、删除变量
使用 unset 命令可以删除变量。语法:
unset variable_name
变量被删除后不能再次使用。unset 命令不能删除只读变量。
实例
#!/bin/bash
name=1705
readonly name
age=17
unset age
echo $age
以上实例执行将没有任何输出。
6、变量类型:(局部变量(常用)、环境变量(系统变量)、shell变量)
运行shell时,会同时存在三种变量:
1) 局部变量 局部变量在脚本或命令中定义,仅在当前shell实例中有效,
其他shell启动的程序不能访问局部变量。
2) 环境变量(系统变量) 所有的程序,包括shell启动的程序,都能访问环境变量,
有些程序需要环境变量来保证其正常运行。必要的时候shell脚本也可以定义环境变量。
set可以查看所有的系统变量
echo $JAVA_HOME
会添临时存储到环境变量中重启或关闭就会消失,也可以通过unset name 撤销这变量(可以不讲)
3) shell变量 shell变量是由shell程序设置的特殊变量。
shell变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了shell的正常运行
7、shell变量的类型:
Shell变量中的类型比较简单:只有字符串类型,字符串可以用单引号,也可以用双引号,反引号。
‘ ‘:单引号中的原样输出,不识别变量、转义符等
" ":双引号识别变量和转义符等
` `:里面是命令
Ps:若是一个整数,那么在不进行运算的情况下即可以看成一个字符串也可以看做一个整数
在计算的情况下是一个整数
#!/bin/bash
a=1 这即可看做字符串也可以看做是整数
b=2
c=”I LOVE U” 只有添加单/双引号才能给字符串添加空格
echo `expr $a + $b` 一旦运算 a 和 b 中存储的是整数
echo ‘`expr $a + $b`’
echo “`expr $a + $b`”
拼接字符串
your_name="haha"
greeting="hello, $your_name !"
echo $greeting
获取字符串长度
string="abcdef"
echo ${#string}
输出 6
提取子字符串
以下实例从字符串第 2 个字符开始截取 4 个字符:
string="this is 1511A class"
echo ${string:0:4}
输出 this
查找子字符串
查找字符 "i 或 s" 的位置:
string="this is 1511A class"
echo `expr index "$string" is`
输出 3 (注意""不能去掉)
ps:特殊变量
$?:表示上一个命令退出的状态 0代表正常退出
$$:表示当前进程编号
$0:表示当前脚本名称
$n:表示n位置的输入参数(n代表数字,n>=1)
#!/bin/bash
echo “第一个参数:=”$1
echo “第一个参数:=”$2
./firstfile.sh hello world
bash支持一维数组(不支持多维数组),并且没有限定数组的大小。
类似与C语言,数组元素的下标由0开始编号。
获取数组中的元素要利用下标,下标可以是整数或算术表达式,其值应大于或等于0。
1、定义数组
在Shell中,用括号来表示数组,数组元素用"空格"符号分割开。定义数组的一般形式为:
数组名=(值1 值2 ... 值n)
例如:
array_name=(value0 value1 value2 value3)
或者
array_name=(
value0
value1
value2
value3
)
还可以单独定义数组的各个分量:
array_name[0]=value0
array_name[1]=value1
array_name[n]=valuen
可以不使用连续的下标,而且下标的范围没有限制。
2、读取数组(没有也不会报数组越界异常,就是查询不出来)
读取数组元素值的一般格式是:
${数组名[下标]}
例如:
valuen=${array_name[n]}
使用@或者*符号可以获取数组中的所有元素,例如:
echo ${array_name[@]}
3、获取数组的长度
获取数组长度的方法与获取字符串长度的方法相同,例如:
# 取得数组元素的个数
length=${#array_name[@]}
# 或者
length=${#array_name[*]}
4、取得数组单个元素的长度
lengthn=${#array_name[n]}
5、数组循环遍历
以"#"开头的行就是注释,会被解释器忽略。(除第一行的解释器以外)
sh里没有多行注释,只能每一行加一个#号。
注:
如果在开发过程中,遇到大段的代码需要临时注释起来,过一会儿又取消注释,怎么办呢?
每一行加个#符号太费力了,可以把这一段要注释的代码用一对花括号括起来,定义成一个函数,没有地方调用这个函数,这块代码就不会执行,达到了和注释一样的效果。
Shell 和其他编程语言一样,支持多种运算符,包括:
算数运算符 + - * / % =
原生bash不支持简单的数学运算,但是可以通过其他命令来实现expr 最常用。
expr 是一款表达式计算工具,使用它能完成表达式的求值操作。
例如,两个数相加(注意使用的是反引号 ` 而不是单引号 ‘):
#!/bin/bash
val=`expr 3 + 3`
echo "两数之和为 : $val"
执行脚本,输出结果如下所示:
两数之和为 : 6
Ps:表达式和运算符之间要有空格,例如 2+2 是不对的,必须写成 2 + 2,这与我们熟悉的大多数编程语言不一样。
完整的表达式要被 ` ` 包含,注意这个字符不是常用的单引号,在 Esc 键下边。
下表列出了常用的算术运算符,假定变量 a 为 10,变量 b 为 20:
运算符 说明 举例
+ 加法 `expr $a + $b` 结果为 30。
- 减法 `expr $a - $b` 结果为 10。
* 乘法 `expr $a \* $b` 结果为 200。 需要注意的是* 需要转义一下
/ 除法 `expr $b / $a` 结果为 2。
% 取余 `expr $b % $a` 结果为 0。
= 赋值 a=$b 将把变量 b 的值赋给 a
关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
下表列出了常用的关系运算符,假定变量 a 为 10,变量 b 为 20:
运算符 说明 举例
-eq (==) 检测两个数是否相等,相等返回 true。 [ $a -eq $b ] 返回 false。
-ne (!=) 检测两个数是否不相等,不相等返回 true。 [ $a -ne $b ] 返回 true。
-gt(>) 检测左边的数是否大于右边的,如果是,则返回 true。[ $a -gt $b ] 返回 false。
-lt(<) 检测左边的数是否小于右边的,如果是,则返回 true。[ $a -lt $b ] 返回 true。
-ge(>=) 检测左边的数是否大等于右边的,如果是,则返回 true。[ $a -ge $b ] 返回 false。
-le(<=) 检测左边的数是否小于等于右边的,如果是,则返回 true。[ $a -le $b ] 返回 true。
单一的if:(表达式必须有空格)
if [条件表达式是] --> [ $a -eq $b ]
then
执行的语句
fi
写成一句版本:if [ ] ; then echo "" ;fi
if else :(表达式必须有空格,else后不能有then)
If [条件表达式式] --> [ $a -eq $b ]
then
执行语句1
else
执行语句2
fi
if else-if else :(elif后必须有then)
if [条件表达式式] --> [ $a -eq $b ]
then
执行语句1
elif [条件表达式式] --> [ $a -eq $b ]
then
执行语句2
else
执行语句3
fi
#!/bin/bash
a=10
b=10
if [ $a -eq $b ]
then
echo "$a -eq $b: a 等于 b"
Fi
a=10
b=20
if [ $a -ne $b ]
then
echo "$a -ne $b: a 不等于 b"
Fi
a=10
b=20
if [ $a -gt $b ]
then
echo "$a -gt $b: a 大于 b"
else
echo "$a -gt $b: a 小于 b"
fi
if [ $a -lt $b ]
then
echo "$a -lt $b: a 小于 b"
elif [ $a -ge $b ]
then
echo "$a -lt $b: a 大于等于 b"
elif [ $a -le $b ]
then
echo "$a -le $b: a 小于等于 b"
else
echo “都不对”
fi
布尔和逻辑运算符
布尔运算符 说明 举例
! 非运算,表达式为 true 则返回 false,否则返回 true。 [ ! false ] 返回 true。
-o 或运算,有一个表达式为 true 则返回 true。 [ $a -lt 20 -o $b -gt 100 ] 返回 true。
-a 与运算,两个表达式都为 true 才返回 true。 [ $a -lt 20 -a $b -gt 100 ] 返回 false。
#!/bin/bash
a=10
b=20
if [ ! $a -lt $b ]
then
echo "正常结果"
else
echo "取!后的结果"
fi
if [ $a -lt 100 -a $b -gt 15 ]
then
echo "$a -lt 100 -a $b -gt 15 : 返回 true"
else
echo "$a -lt 100 -a $b -gt 15 : 返回 false"
fi
if [ $a -lt 100 -o $b -gt 100 ]
then
echo "$a -lt 100 -o $b -gt 100 : 返回 true"
else
echo "$a -lt 100 -o $b -gt 100 : 返回 false"
fi
逻辑运算符
&& 逻辑的 AND [[ $a -lt 100 && $b -gt 100 ]] 返回 false
|| 逻辑的 OR [[ $a -lt 100 || $b -gt 100 ]] 返回 true
#!/bin/bash
a=10
b=20
if [[ $a -lt 100 && $b -gt 100 ]]
then
echo "返回 true"
else
echo "返回 false"
fi
if [[ $a -lt 100 || $b -gt 100 ]]
then
echo "返回 true"
else
echo "返回 false"
fi
字符串运算符
下表列出了常用的字符串运算符,假定变量 a 为 "abc",变量 b 为 "efg":
运算符 说明 举例
= 检测两个字符串是否相等,相等返回 true。 [ $a = $b ] 返回 false。
!= 检测两个字符串是否不相等,不相等返回 true。 [ $a != $b ] 返回 true。
-z 检测字符串长度是否为0,为0返回 true。 [ -z $a ] 返回 false。
-n 检测字符串长度是否不为0,不为0返回 true。 [ -n $a ] 返回 true。
str 检测字符串是否为空,不为空返回 true。 [ $a ] 返回 true。
Ps:获取字符串的长度${#变量名}
实例
字符串运算符实例如下:
#!/bin/bash
a="abc"
b="efg"
if [ $a = $b ]
then
echo "$a = $b : a 等于 b"
else
echo "$a = $b: a 不等于 b"
fi
if [ $a != $b ]
then
echo "$a != $b : a 不等于 b"
else
echo "$a != $b: a 等于 b"
fi
if [ -z $a ]
then
echo "-z $a : 字符串长度为 0"
else
echo "-z $a : 字符串长度不为 0"
fi
if [ -n $a ]
then
echo "-n $a : 字符串长度不为 0"
else
echo "-n $a : 字符串长度为 0"
fi
if [ $a ]
then
echo "$a : 字符串不为空"
else
echo "$a : 字符串为空"
fi
执行脚本,输出结果如下所示:
abc = efg: a 不等于 b
abc != efg : a 不等于 b
-z abc : 字符串长度不为 0
-n abc : 字符串长度不为 0
abc : 字符串不为空
文件运算符
属性检测描述如下:
操作符 说明 举例
常用:
-d file 检测文件是否是目录,如果是,则返回 true。 [ -d $file ] 返回 false
-f file 检测文件是否是普通文件(既不是目录,也不是设备文件),如果是,则返回 true。 [ -f $file ] 返回 true。
-r file 检测文件是否可读,如果是,则返回 true。 [ -r $file ] 返回 true。
-w file 检测文件是否可写,如果是,则返回 true。 [ -w $file ] 返回 true。
-x file 检测文件是否可执行,如果是,则返回 true。 [ -x $file ] 返回 true。
-s file 检测文件是否为空(文件大小是否大于0),不为空返回 true。 [ -s $file ] 返回 true。
-e file 检测文件(包括目录)是否存在,如果是,则返回 true。 [ -e $file ] 返回 true。
#!/bin/bash
file="/home/shell/first.sh"
if [ -r $file ]
then
echo "文件可读"
else
echo "文件不可读"
fi
if [ -w $file ]
then
echo "文件可写"
else
echo "文件不可写"
fi
if [ -x $file ]
then
echo "文件可执行"
else
echo "文件不可执行"
fi
if [ -f $file ]
then
echo "文件为普通文件"
else
echo "文件为特殊文件"
fi
if [ -d $file ]
then
echo "文件是个目录"
else
echo "文件不是个目录"
fi
if [ -s $file ]
then
echo "文件不为空"
else
echo "文件为空"
fi
if [ -e $file ]
then
echo "文件存在"
else
echo "文件不存在"
fi
不常用:
-b file 检测文件是否是块设备文件,如果是,则返回 true。 [ -b $file ] 返回 false。
-c file 检测文件是否是字符设备文件,如果是,则返回 true。 [ -c $file ] 返回 false。
-g file 检测文件是否设置了 SGID 位,如果是,则返回 true。 [ -g $file ] 返回 false。
-k file 检测文件是否设置了粘着位(Sticky Bit),如果是,则返回 true。 [ -k $file ] 返回
false。
-p file 检测文件是否是具名管道,如果是,则返回 true。 [ -p $file ] 返回 false。
-u file 检测文件是否设置了 SUID 位,如果是,则返回 true。 [ -u $file ] 返回 false。
for 、 while 、 until
for 变量 in 范围
do
执行语句
done
#!/bin/bash
for i in 1 2 3
do
echo $i
Done
for i in `seq 1 100`
do
echo $i
done
Ps:seq用于产生从某个数到另外一个数之间的所有整数
for i in {1..100}
do
echo $i
done
for((i = 1;i<=100;i++))
do
echo $i
done
ps:这里写的代码都可以缩成一行写不过每一句结束使用;号隔开
for i in {1..3};do echo $i;done
while [条件]
do
执行
done
#!/bin/bash
i=1
while [ $i -le 100 ]
do
echo $i
#变量自增
#i=`expr $i + 1 `
如下是let命令
let "i++"
done
i=1
while (($i <=100))
do
echo $i
let i++
done
until
until命令和while命令类似,while能实现的脚本until同样也可以实现,但区别是while循环在条件为真时继续执行循环而until则在条件为假时执行循
也就是相当于条件取!
#!/bin/bash
i=1
while (($i >100))
do
echo $i
let i++
done
ps:
打印出 root目录下的文件夹和文件名称
#!/bin/bash
file="/root"
for f in `ls $file`
do
echo $f
done
$#:表示传递参数的个数
$*和$@:表示传递多个参数,在不添加双引号的情况下都是按照一个一个的输入
#!/bin/bash
for i in $*或$@
do
echo $i
done
echo “参数个数:”$#
./for.sh 1 2 3 4 5
$*和$@如果双引号引起来的时候$*会将传入的参数看做是一个整体,$@不变
for i in ”$*”
do
echo $i
done
echo “参数个数:”$#
./for.sh 1 2 3 4 5
shell循环支持break和continue
case必须有in,一个段落结束必须用双;;号,esac整个case结束标识
case 值 in
条件1)
执行语句
;;
条件1)
执行语句
;;
esac
ps:读取内容使用 read -p(提示语句)变量
请输入一个月份输出对应的天数
#!/bin/bash
while :
do
read -p "请输入一个月份:" month
case $month in
2)
echo "28天"
break
;;
1|3|5|7|8|10|12)
echo "31天"
break
;;
4|6|9|11)
echo "30天"
break
;;
*) --> * 代表上面都没有匹配上后的结果
echo "没有这个月份"
continue
;;
esac
done
function 方法名(){
执行体
return 值
}
ps:
1.可以带function 方法名()定义,也可以直接 方法名() 定义,不带任何参数。
2.参数返回,可以显示加:return 返回,如果不加,将以最后一条命令运行结果,作为返回值
无返回值无参数
#!/bin/bash
function func1(){
echo "this is my first function"
}
echo "-------开始-------"
firstfun
echo "-------结束-------"
有返回值无参数
function func2(){
echo "请输入两个数:"
echo "输入第一个数字为:"
read fnum
echo "输入第二个数字为:"
read snum
echo "输入两个数分别为:$fnum and $snum"
return $(($fnum + $snum)) --> 这样写 等价于 `expr $fnum + $snum`
}
func2
echo "输入两个函数之和为:$?"
函数返回值在调用该函数后通过 $? 来获得。
ps:所有函数在使用前必须定义。这意味着必须将函数放在脚本开始部分,直至shell解释器首次发现它时,才可以使用。调用函数仅使用其函数名即可。
函数参数
在Shell中,调用函数时可以向其传递参数。在函数体内部,通过 $n 的形式来获取参数的值,例如,$1表示第一个参数,$2表示第二个参数...
无返回值有参数
function func3(){
echo "第1个参数:$1"
echo "第2个参数:$2"
echo "第10个参数:$10"
echo "第10个参数:${10}"
echo "参数个数:$#"
echo "输出所有参数:$*"
}
func3 1 2 3 4 5 6 7 8 9 34 73
ps:
$10 不能获取第十个参数,获取第十个参数需要${10}。当n>=10时,需要使用${n}来获取参数。参数用空格分开
Shell 文件引入
和其他语言一样,Shell 也可以包含外部脚本。这样可以很方便的封装一些公用的代码作为一个独立的文件。
Shell 文件包含的语法格式如下:
. 文件路径 # 注意点号(.)和文件名中间有一空格
或
source 文件路径
案例:
vi 1.sh
#!/bin/bash
name=‘123‘
vi 2.sh
chmod a+x 2.sh
#!/bin/bash
. /root/shell/1.sh
#source /home/shell/1.sh
echo $name
执行:
./2.sh
shell的语法检测:相当于java的编译
#!/bin/bash
echo "welcome to shell debug"
for i in 1 2 3 4 5 6
do
echo $i
done
echo "shell debug is over"
1、shell语法检测:
sh -n ./test.sh (sh是/bin/sh 是系统提供的可执行脚本)
2、shell的普通调试:
sh -x ./test.sh
进入调试模式后,Shell依次执行读入的语句,产生的输出中有的带加号,有的不带,如下。
带加号表示该条语句是Shell执行的。
不带加号表示该语句是Shell产生的输出。
shell的中断调试:(在shell中添加一个睡眠,保证可以有时间中断调试 sleep 3 睡眠3秒执行下一个语句)
#!/bin/bash
echo "welcome to shell debug"
for i in 1 2 3 4 5 6
do
echo $i
sleep 3
done
echo "shell debug is over"
在调试过程中可以按Ctrl + Z中断调试,观察结果,然后再按fg键继续调试即可。(先按f在按g键)
使用调试工具-bashdb
脚本比较大时,通过-x参数调试时已不方便时.
上传
解压可以跟路径
tar -xzvf bashdb-4.4-0.92.tar.gz -C /usr/src
进入到对应的目录
cd /usr/src/bashdb-4.4-0.92
生成makefile文件
./configure
安装
make install
调试方法
调试命令:
./bashdb --debugger 文件所在路径
【常用命令】
l 列出当前行上下各5行,总共10行
q|quit 退出
h 帮助
/for/ 向后搜索字符串for
?for? 向前搜索字符串for
x 1+2 计算算术表达式的值
!! ls -laRt 执行shell命令
n 执行下一条语句
s 4 单步执行4次,如遇到函数则进入函数里面
b 4 在行号4处设置断点
del 4 删除行号为4的断点
c 10 一直执行到行号10处
R|run 重新执行当前调试脚本
finish 执行到程序最后
将当前时间格式化:
date +"%Y%m%d" 或者 date +"%Y-%m-%d"
获取当天前后日期:(x为正数即是向前,负数则是向后)
date -d "x days ago" +%Y%m%d
date -d "x weeks ago" +%Y%m%d
date -d "x months ago" +%Y%m%d
date -d "x years ago" +%Y%m%d
定时任务
crontab -e 开启定时任务
crontab -r 删除定时任务
minute hour day month week command 顺序:分 时 日 月 周
中间是tab隔开
minute: 表示分钟,可以是从0到59之间的任何整数。
hour: 表示小时,可以是从0到23之间的任何整数。
day: 表示日期,可以是从1到31之间的任何整数。
month: 表示月份,可以是从1到12之间的任何整数。
week: 表示星期几,可以是从0到7之间的任何整数,这里的0或7代表星期日。
command:要执行的命令,可以是系统命令,也可以是自己编写的脚本文件。
星号(*):代表所有可能的值,例如month字段如果是星号,则表示在满足其它字段的制约条件后每月都执行该命令操作。
逗号(,):可以用逗号隔开的值指定一个列表范围,例如,“1,2,5,7,8,9”
中杠(-):可以用整数之间的中杠表示一个整数范围,例如“2-6”表示“2,3,4,5,6”
正斜线(/):可以用正斜线指定时间的间隔频率,例如“0-23/2”表示每两小时执行一次。同时正斜线可以和星号一起使用,例如*/10,如果用在minute字段,表示每十分钟执行一次
例子:
每隔一分钟向目录下写文件
*/1 * * * * echo "hello world" >> /root/test.log
tail -f test.log 监控文件
同步时间
date查看当前时间
Linux服务器运行久时,系统时间就会存在一定的误差
ntpdate -u 地址
没有命令就yum install -y ntpdate
ntp常用服务器:
中国国家授时中心:210.72.145.44
NTP服务器(上海) :ntp.api.bz
阿里云NTP:ntp1.aliyun.com (数字1-7都可以以)
这两个命令相当于linux下shell中的框架
介绍第一个方法
cut [选项] 文件名 默认分割符是制表符(tab)
选项:
-f 列号: 提取第几列
-d 分隔符: 按照指定分隔符分割列
创建一个文件 vi cut.log
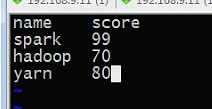
cut -f 2 cut.log 提取第二列
cut -f 1,2 cut.log 提取第一,二列
查看passwd文件下
cut -d ":" -f 1,3 /etc/passwd 以:分割,提取第1和第3列
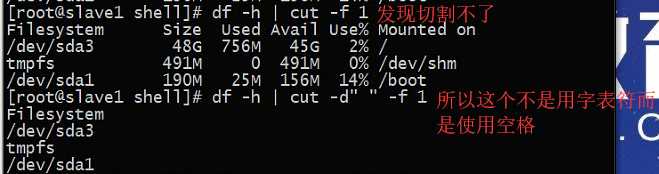
我们是以空格切分的但是需要注意的是我们在使用cat中的空格是一个空格所以

这样切割不会有任何输出,理论上我们查看的是第二行,但实际因为这个空是默认后面第一个空格所以我们得不到第二列 而是 空格后面的空格
所以我们要的到第二列要获取所有空格码?
cut的局限性 不能分割空格 df -h 不能使用cut分割
awk
一个强大的文本分析工具
把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
语法:awk ‘条件1{动作1}条件2{动作2}...’文件名
条件(Pattern):
一般使用关系表达式作为条件: > >= <=等
动作(Action):
格式化输出
流程控制语句
df -h | awk ‘{print $1}‘ 显示第一列
df -h | awk ‘{print $1 $2}‘ 显示第一列和第二列
df -h | awk ‘{print $1 "\t" $2}‘ 显示第一列和第二列 \t分割
这里并没有条件而是直接输出数据
这里还可以使用printf 打印 但是没有换行 建议使用 print
FS内置变量

可以发现打印的数据第一行没有分割是因为FS是一个内置变量会先读取文件的第一行,所以为了保证第一行的读取修改为:
cat /etc/passwd | awk ‘BEGIN {FS=":"} {print $1 "\t" $2 "\t" $3 }‘
输出可登陆用户的用户名和UID,这里使用FS内置变量指定分隔符为:,而且使用BEGIN保证第一行也操作,因为awk命令会在读取第一行后再执行条件
指定分隔符还可以用-F更简单
cat /etc/passwd | awk -F: ‘{print $1 "\t"$3 }‘ 效果同上
ps: awk 的默认分隔符是空格,所以要是分割空格的话可以直接省略-F
df -h | awk ‘{print $1}’

BEGIN 在所有数据读取之前执行
在输出之前使用BEGIN输出内容
awk ‘BEGIN {printf "first Line \n"}
END 在所有数据执行之后执行
所有命令执行完后,输出一句"The End"
awk ‘END {printf "The End \n"}
过滤sda3硬盘并打印第五行以%分割取后面的结果
df -h | grep sda3 | awk ‘{print $5}‘ | awk -F% ‘{print $1}‘
过滤sda3硬盘并打印第五行以%分割取第一行
df -h | grep sda3 | awk ‘{print $5}‘ | cut -d"%" -f 1
获取所有用户信息里的用户名:
cat /etc/passwd | awk -F: ‘{print $1}‘
awk -F: ‘{print $1}‘ /etc/passwd
获取当前机器的ip地址:
# ifconfig eth0 | grep ‘inet addr‘ | awk -F: ‘{print $2}‘ | awk ‘{print $1}‘
sed: stream editor
s e d是一个非交互性文本流编辑器。它编辑文件或标准输入导出的文本拷贝。标准输入可 能是来自键盘、文件重定向、字符串或变量,或者是一个管道的文本。
ps: s e d 并不与初始化文件打交道, 它操作的只是一个拷贝,然后所有的改动如果没有重定向到一个文件,将输出到屏幕。
语法:sed [选项]’[动作]’ 文件名
常用选项:
-n 使用安静(silent)模式。显示经过sed特殊处理的数据。
-e 允许多点编辑。
-i 直接修改读取的档案内容,而不是由屏幕输出。
|
命令 |
功能描述 |
|
a\ |
新增, a 的后面可以接字串,在下一行出现 |
|
c\ |
替换 |
|
d |
删除 |
|
i\ |
插入, i 的后面可以接字串 |
|
p |
打印 |
|
s |
查找并替换,例如 1,20s/old/new/g |
sed ‘2p‘ cut.log 显示第二行和所有数据
sed -n ‘2p‘ cut.log 显示第二行
sed ‘2a HBase’cut.log 在第二行后面添加数据
sed ‘2i hive 60’cut.log 在第二行前添加数据
sed ‘2a hive \
hbase \
flume’cut.log
在第2行之后 添加多行 以换行的形式可以添加多行
sed ‘2c hbase 80’cut.log 替换第二行数据
ps:g全局替换的意思
sed ‘s/spark/spark2.0/g’ cut.log 把cut.log文件中的spark替换为spark2.0,并输出
sed -e ‘2s/spark/spark2.0/g; 4s/yarn//g‘ cut.log 同时进行多个替换
sed –i ‘s/spark/spark2.0/g’ cut.log 要想真正替换,需要使用-i参数
使用sed获取机器的ip地址
ifconfig eth0 | grep ‘inet addr:‘| sed ‘s/^.*addr://g‘ | sed ‘s/ Bcast.*$//g‘
ps:^开始正则表达式$结束正则表达式
快照和克隆:
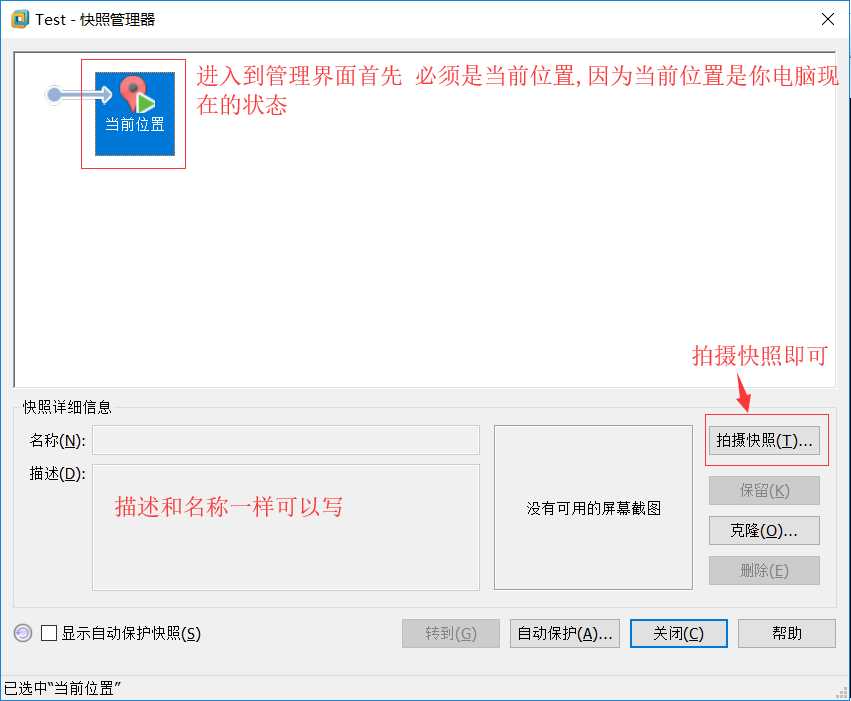
什么是快照?
快照相当于将机器在某一个时间点的状态保存下来,若以后出现任何问题都可以通过这个快照回复到快照时的状态
快照操作很简单
ps:需要做快照的话建议在关机以后第一时间进行快照自作,开机状态也可以但是个人不太推荐
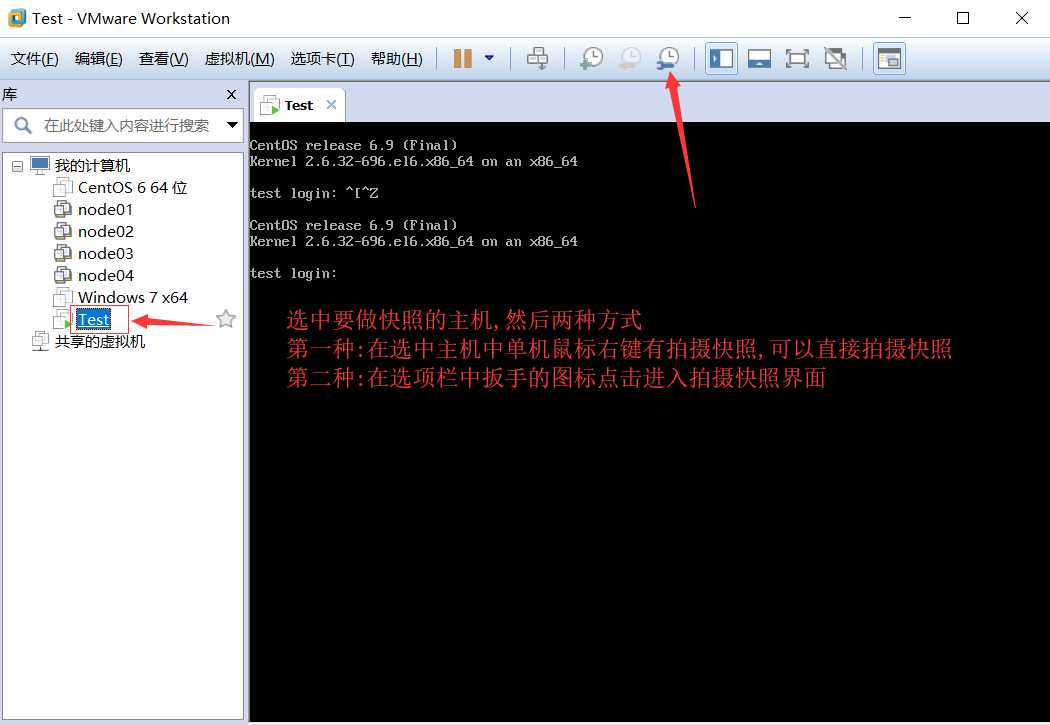
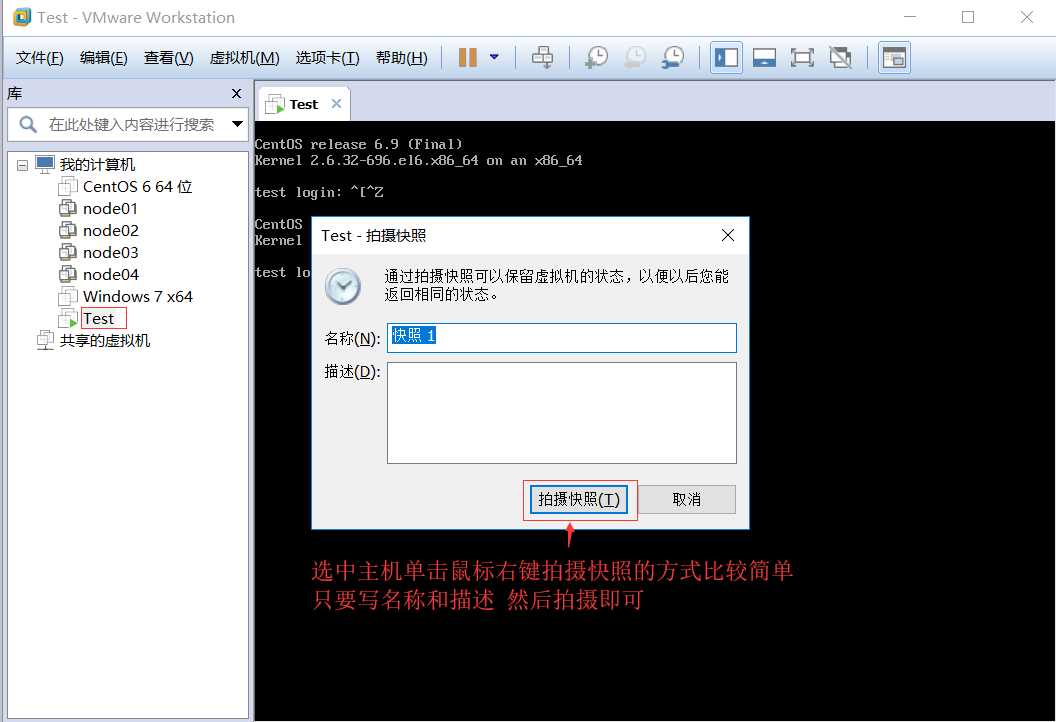
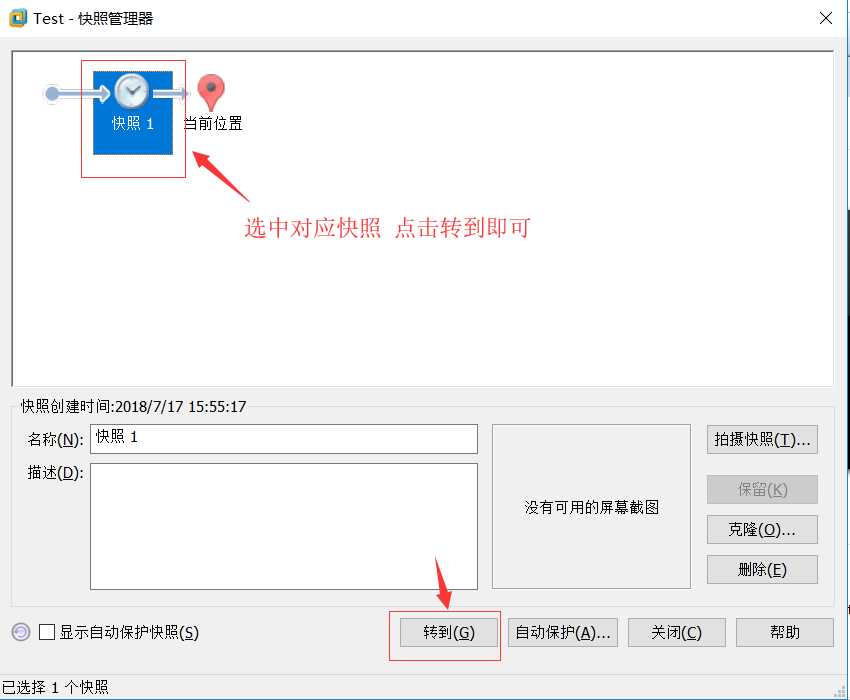
若想恢复到上一个拍摄快照的时间点(当时系统的样子也很简单)
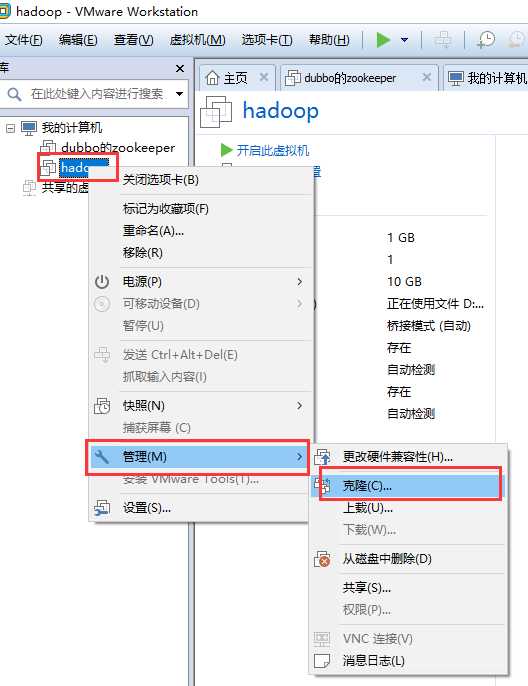
克隆:
无论是hadoop还是Spark都需要集群,不可能是一台机器,通过光盘安装成本台高,所以我们使用克隆的方式来创建出4台机器
克隆一定要在关机状态下完成
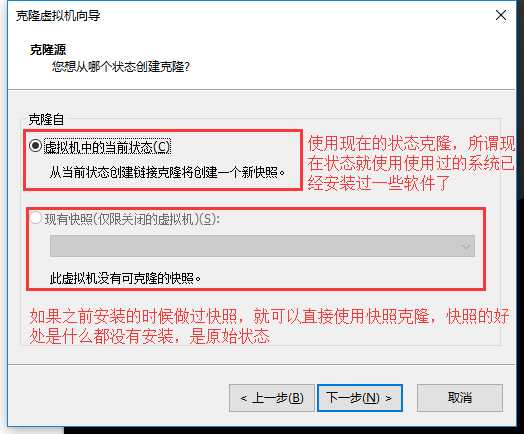
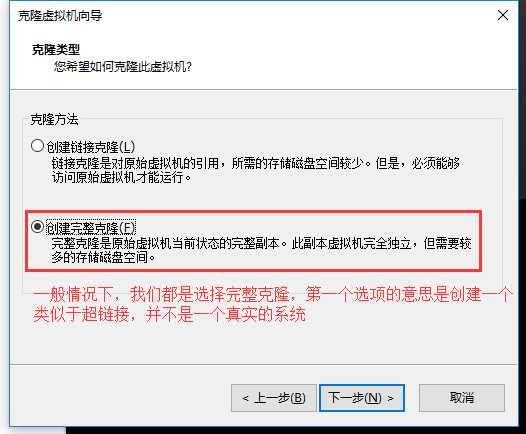
克隆完后需要修改几个位置
1.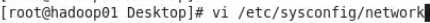
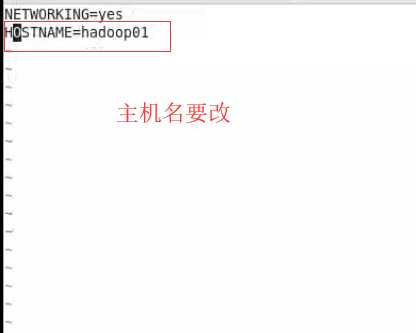
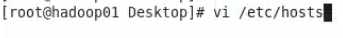 若之前修改过就不需要改了没有的话 就是修改IP和 对应的名字 修改的时候建议修改windows中的hosts这样就可以在外部访问时使用名字C:\Windows\System32\drivers\etc下的hosts修改 写的方式和linux中hosts一直就行
若之前修改过就不需要改了没有的话 就是修改IP和 对应的名字 修改的时候建议修改windows中的hosts这样就可以在外部访问时使用名字C:\Windows\System32\drivers\etc下的hosts修改 写的方式和linux中hosts一直就行
2.ip地址和硬件地址
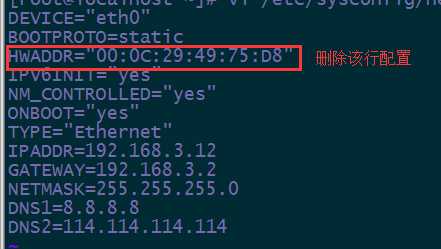
vi /etc/sysconfig/network-scripts/ifcfg-eth0中的修改mac配置信息 和注释UUID(#注释)
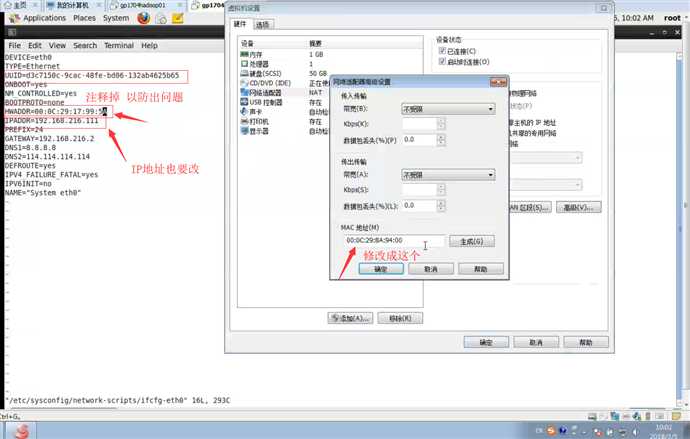
修改网卡信息:

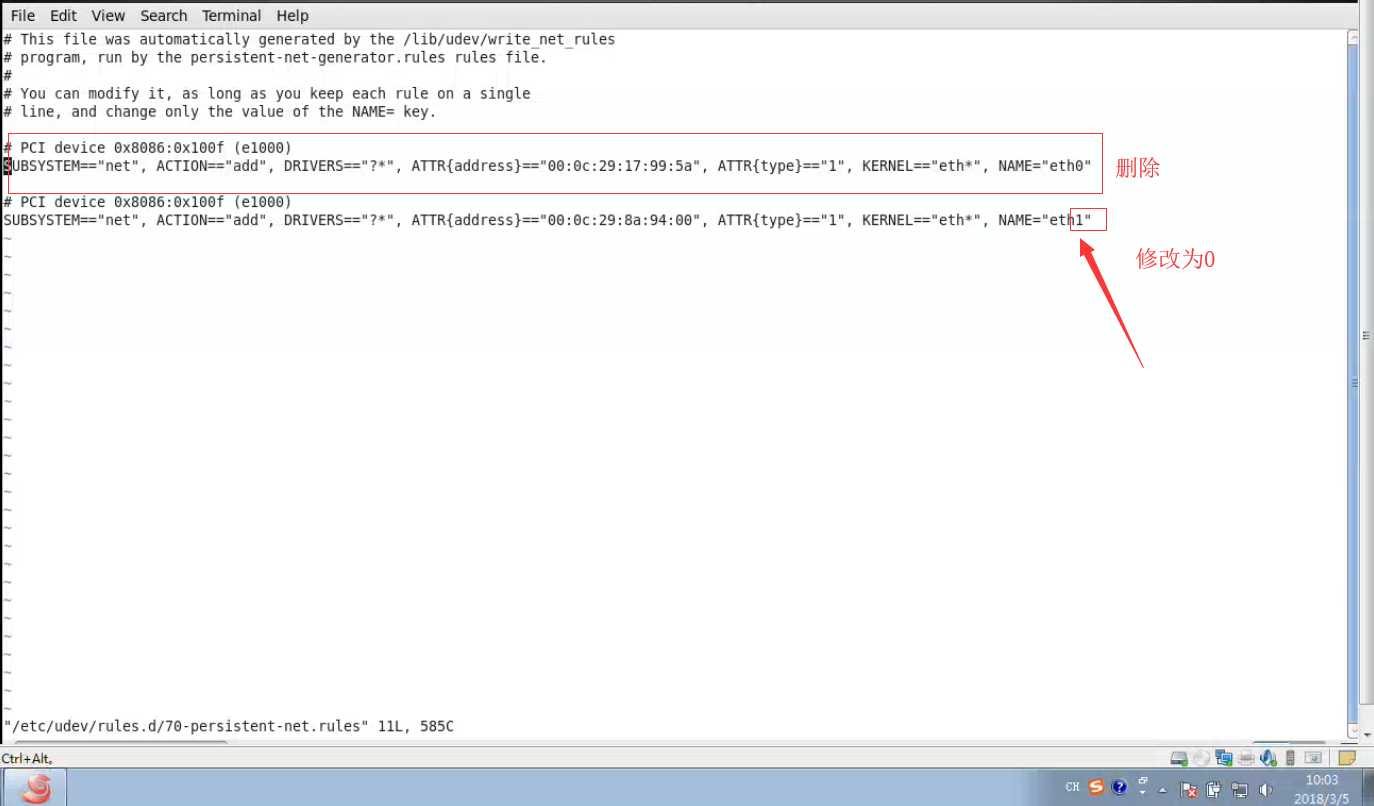
3,重启系统 reboot
1,直接删除/etc/sysconfig/network-scripts/ifcfg-eth0中的mac配置信息和UUID
2,直接删除文件 /etc/udev/rules.d/70-persistent-net.rules

4,重启系统 reboot
ps: 做完这些一定要重启机器
标签:grep 个人 查看 技术分享 技术 设备文件 映射 内置变量 shell实例
原文地址:https://www.cnblogs.com/lijun199309/p/9663336.html