标签:lin 中国 返回 处理 基于 以太网 存储 work hid
说起IBM的LinuxONE以及Oracle的Exadata,相信在IT行业从事基础架构工作的同业们都不陌生。最直观的印象就是:它们都是大型服务器,体积非常庞大,价格非常昂贵,一个是IBM的拳头产品,一个是Oracle的拳头产品。
在去IOE的浪潮之下,可能我们很少去关注其中的细节了。但是对于企业而言,IT如何能够以最优的性价比来设计最合理的企业IT基础架构来支撑业务才是我们IT人最终的目标。如果我们以专业的角度去论证IT性价比,或许我们需要来面对它们的抉择。这个时候我们就需要把这个体积庞大的东西剖开来看看里面到底装了什么?是不是值得我们去选择?
Exadata 里装了些什么?
1、Exadata的硬件架构
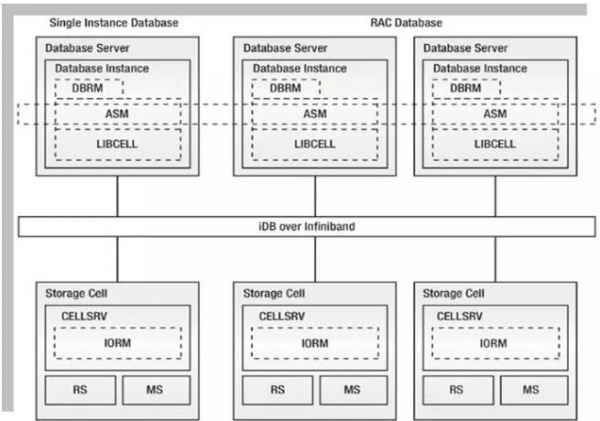
图1展示的是Oracle Exadata的硬件架构图,主要分为三层:最上层为Oracle RAC服务器实例层,中间层为IDB over Infiniband高速网络层,最下层为智能存储网络实例层。从硬件架构本身来看似乎没有什么特别的地方。依然是计算层、网络层、存储层等传统架构,只不过是在网络层进行了Infiniband的网络硬件升级,在存储层加了一些SSD快速闪盘等等。
这些硬件的升级以及硬件的这种架构是撑Exadata所有特性的必要条件,因为Exadata中的软件智能扫描特性是需要Oracle特殊的通讯协议IDB来支撑,而IDB又是需要Infiniband中的RDS协议来支撑。Exadata中的智能闪存缓存技术特性是需要存储层的SSD来支撑。整个硬件体系架构中由以下几类主要模块组成:
数据库节点:全机架有八个运行Oracle Linux 或 Oracle Solaris 的节点。
存储单元:磁盘是连接到被称为存储单元的另一种服务器。
磁盘:每个单元包含自己的磁盘。根据配置的不同,可以是高性能磁盘,或者是高容量磁盘。
闪存磁盘:每个单元还有闪存磁盘。可提供给计算节点,也可用作数据库集群的二级高速缓存。
Infiniband:单元和节点通过高速、低延迟的 infiniband 进行连接。
以太网交换机:外界可通过 infiniband 进行通信,也可通过以太网进行通信。
KVM 交换机:通过一个键盘、视频和鼠标交换机直接物理连接到各个节点和单元。
2、Exadata的软件技术特性
Oracle Exadata的软件技术特性有很多:智能扫描特性(Smart Scan)、存储索引特性、混合列压缩特性(EHCC)、智能闪存缓存(Smart Flash Cache)等。下面我们来分别剖析每一种特性在Exadata当中的作用以及彼此之间的有机联系。
一、智能扫描特性
这一特性可以用一个词来概括,那就是——offload。这就是Exadata的核心思想,将数据的过滤、计算等处理offload到分散的存储节点,减少存储到数据库节点的数据传输,并分散数据节点的计算压力,这估计也是Exadata的存储节点比DB节点多的缘故之一吧。
列投影:就是过滤扫描的列,如果有的列SQL并不相关那么就不传输到数据库实例节点。
谓词过滤:对where条件中的过滤谓词下派到存储节点预处理,减少数据传输。
存储索引:这里的索引并非数据库层含义的索引,其实质是在存储节点的内存上建立一个存储数据的索引结构,记录存储片段的区间最大最小值,这样存储根据谓词的过滤条件加上存储索引即可直接排除一些根本不需要的存储I/O。
函数下派:将一些函数计算下派到存储节点,用于分散计算压力与减少数据传输。
解压/解密的下派:这个主要是计算压力的分散,数据传输不一定减少。
伪列下派:伪列一般需要消耗计算资源,下派可以分散计算压力并且减少数据传输。
块初始化下派:传统的块初始化是由数据库实例节点完成并写入存储节点,而Exadata将块儿初始化的工作下派给存储独立完成,这可以减少计算与传输。
二、 智能闪存缓存特性
这个特性指的就是利用SSD盘缓存机械盘的数据,这能够大大提升I/O速度(对查询)。存储软件具有两项主要功能,这些功能使其可充分利用闪存硬件。第一项功能是智能闪存缓存,该功能可在闪存中暂存活动的数据库对象。第二项功能是智能闪存日志记录,该技术可加速数据库日志记录的关键功能。最后,Oracle Database 的部署需要任务关键型灵活性,而 Oracle Exadata Storage Server 软件与 Oracle Database 可以携手提供这种灵活性。
智能闪存缓存的自动化管理:Exadata 智能闪存缓存将频繁访问的数据保存在速度极快的闪存存储中,同时将大部分数据保存在成本效益很高的磁盘存储中。此过程自动进行,无需用户执行任何操作。
在闪存缓存中定位对象:存储软件和数据库实例可提供优先处理功能,可优先缓存某些数据库对象。例如,对象可在缓存中定位且始终缓存,或对象会被认定为从不缓存的对象。此控制由新的存储子句属性 CELL_FLASH_CACHE 提供,它可被分配给数据库表、索引、分区和 LOB 列。
从闪存缓存创建闪存盘:保留缓存的分区并将其用作逻辑闪存盘。对于每个 Exadata 单元,闪存盘保留的空间按十六个单元磁盘分配。在这些基于闪存的单元磁盘上创建网格磁盘(驻留在物理单元磁盘上的逻辑磁盘),且将网格磁盘分配给自动存储管理 (ASM) 磁盘组。
数据库日志记录闪存:在 OLTP 工作负载中,数据库记录写入的快速响应时间是关键。数据库管理员 (DBA)配置恢复日志组和镜像日志文件以提高可用性,但低速磁盘性能对恢复日志写入等待时间和系统性能具有负面影响 — 日志写入等待完成到最低速磁盘的写入。
三、混合列压缩(EHCC)
对于传统的数据库,数据是以行的方式保存在据库块中,这种保存方式对于OLTP应用非常适合,但是对于大数据量的OLAP应用就显得没有那么高效了,而且随着历史数据的积累,历史数据会占用大量的空间,这些数据几乎不可能会被改动,但是却仍然会被一些DSS或者OLAP应用所查询,而这些查询往往并不关心一行数据的所有列,而只是关心特定的一些列,所以,列式存储对于这种应用无疑要优于行式存储。EHCC特性的出现就很好的解决了这种困难,一方面它会以列式保存数据;另一方面它会对数据进行压缩。它是支撑Exadata智能扫描特性中非常重要的一项技术。
四、存储索引技术(Exadata Storage Index)
存储索引功能是在Exadata 11.2.1.2.0 版本(V2 )上引入的新特性,它主配合智能扫描(smart scan)功能,来消除一个查询所不需要的IO请求。它在内存中保存表数据的汇总信息,并通过内部机制来控制和访问这些数据结构。每1M大小的磁盘空间上都会对应一个存储索引的条目,这个条目中维护着这个区域中最大不超过8列的最大值(MAX)和最小值(MIN)。在我们运行查询的时候,cellsrv进程就会根据这个查询里的表对象和谓词通过hash算法到内存中寻找存储索引,如果没有找到,则在返回结果集之后,建立存储索引。当第二次运行的时候,cellserv发现了已经建立了索引,则直接使用存储索引来减少IO操作。它也是支撑智能扫描特性必不可少的一项关键技术。
LinuxONE 里装了些什么?
1、LinuxONE的硬件架构
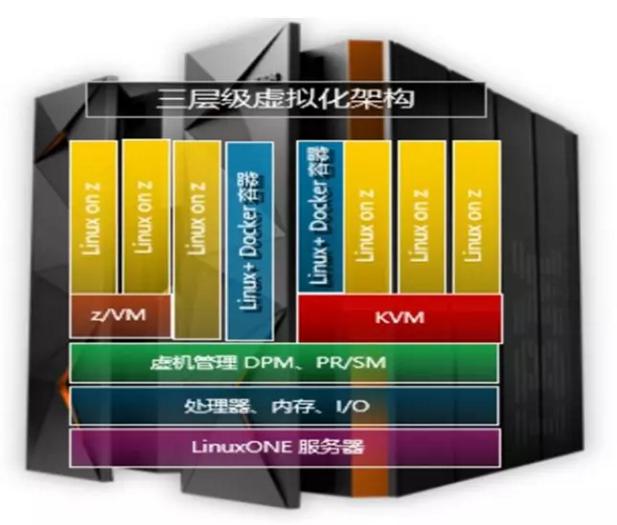
图2 展示的是IBM LinuxONE的硬件架构。它没有像Exadata那样的计算存储分离。而是整合了足够强大硬件能力的服务器。并且在此基础之上实现了平台层的多层虚拟化架构。
首先,在LinuxONE的里面包含的是超强处理能力的计算资源硬件池和超高吞吐能力的IO资源池。所有的这些硬件资源池都是横向平等的关系。基于这个庞大的硬件资源池,又可以在此基础上做三层虚拟化架构:
第一层:通过DPM或PR/SM实现微码级逻辑分区。也就是所谓的逻辑分区。大型关键数据库可以直接部署在LPAR分区,赋予更接近硬件的资源调度及强大纵向扩展能力。
第二层:基于逻辑分区之上形成的KVM标准化开源虚拟化逻辑分区。
第三层:可以基于KVM虚拟化技术形成的平台建立基于Docker技术虚拟出大批量容器载体,以支持某些维服务或者是Devops场景需要。
对于IBM的LinuxONE来讲,其实它没有什么应用软件特性可言,因为它不与任何应用作绑定。也就不会有任何基于某一款软件产品而定制化的软件技术特性。而它具备的是优秀的平台特性,包括它的开放性、扩展性以及高效性等等。下面我们分别就其平台的这些特性做以说明:
一、开放性
LinuxONE的开放性要从以下几点来进行说明:
1. 全面支持主流开源软件:LinuxONE特性之一号称是"由你做主的Linux",它全面支持主流开源软件,任由开发者选择自己所熟悉和偏爱的开源工具,支持包括Apache Spark、Node.js、MongoDB、MariaDB、PostgreSQL、Chef和Docker等一长串的名单。这些技术能够实现优于其它大型主机的运行,且具备引人瞩目的性能优势。
2. 支持Linux开源大型主机项目:Linux基金会是一个致力于促进Linux发展和协同开发的非营利组织。IBM不断地将对Linux基金会创立的“开源大型主机项目”作出支持,并凭借贡献出的大型机代码推动该项目的发展。这不仅有助于在大型机上加入个性化的性能,还能更好地满足企业和开发者对安全性、可用性和高性能的要求。
3. 面向新经济:由于IBM对OpenStack 云计算平台行业标准的大力支持,其他基于 OpenStack 的行业云管理解决方案同样可以在 LinuxONE 上运行。企业移动解决方案的核心是可以安全地将企业的核心记录和数据扩展到移动应用中,LinuxONE同样具有很好的支持特性。行业标准的 Hadoop 框架系列也是其重要的支持对象。IBM的 DevOps 方法通过一个开放的、基于标准的工具平台支持持续交付,加之市场领先的过程框架Scaled Agile Framework (SAFe) ,使LinuxONE提供了一个全面的过程和工具框架。
二、高性能
如果论服务器的的纵向性能,还是要属IBM的服务器,这主要取决于它的强大的CPU。从单个CPU的处理能力来讲,5GHz、4级高速缓存(>12GB)、独有的多线程技术可以达到140多个可配置核心等都是其他的硬件厂商无法比拟的。另外,SIMD单指令多数据流向量分析技术以及独有的I/O专用SAP处理器技术都是造就它具备强大性能的前提条件。
从IO处理能力上来讲,IO带宽可以达到800多GB/s,而且还有内存级机内高速网络Hipersocket来支撑其内部通讯,跨机器远程内存访问技术RDMA也为其的横向IO能力提供了必不可少的技术保障。
三、扩展性
说到LinuxONE的扩展性,其实可以从两个方面来分析。一方面是其单机内的扩展能力,另外一个方面是多机组成的整体扩展能力。就单机而言,它可以支持8000多虚拟机、200多万容器。而且这种机内扩展的灵活性主要取决于其多级虚拟化架构的支持。而多机的横向扩展能力主要取决于虚拟化技术体系的支撑,由于其对开源KVM虚拟化技术的支持,由于其对Docker容器技术的支持,那么一定会继承这些开源云计算技术框架带来的无限的横向扩展能力。
Exadata & LinuxONE 到底有啥差异?
通过前面的章节,我们对这两个服务器有了一个整体的认识:Exadata的体积里面除了有一大堆硬件资源之外,更多的是它的软件技术特性。而LinuxONE的体积里面除了有其先进的硬件资源池,更重要的是它的平台特性。无论他们有什么样的特性,最终是要服务于我们的业务场景,那么接下来我们就从业务场景出发来看看这二者之间的差异。
首先,Exadata的软件特性,无论是它的智能扫描还是它的智能闪存等软件特性,终究目的是要解决数据库实例的IO问题。传统模式下,如果没有这些特性,那么数据库实例读取的数据没有任何过滤和处理,基本上是1:1的模式,那么IO的压力会非常大,尤其是在分析型数据库的场景下。经过了这些数据的过滤技术、数据的列模式读取技术、智能的数据移动技术等等,再结合着Infiniband硬件的强大协议支持,那么数据库实例耗费在IO上的资源就会成百倍甚至更高数量的减少,整体上数据库集群的处理能力就会得到质的飞跃。但是千万不要忘记,这个有效性仅仅适用于分析型的Oracle数据库应用。因为只有这种因为才会在IO上产生如此巨大的瓶颈效应。
然后,LinuxONE的平台特性,它的开放性使之与开源世界有一种与生俱来的生态性,意味着它不是为某一个商业产品或者软件而定制的平台,而是尽可能去容纳尽可能多的软件。一方面是说它的包容性够好,另外一方面其实也说明了它对于任何软件的支持都不会到极致的状态。再说它的高性能,无可厚非LinuxONE的高性能来自于它强大的处理器,没有几个能与之比拟,从另外一个角度说明它本身的计算密度足可以支撑各种负载密集型应用。最后,从它的灵活性上讲,其是来自于它本身的微码层的虚拟化技术以及它对开源KVM、Docker容器技术等充分支持。正是由于它对虚拟化技术支持的宽容性和灵活性,使得它可以支撑传统性的高负载应用,也可以支持互联网业务的轻量型敏捷应用。LinuxONE大规模高密度整合各种应用负载,极大的节省了空间,耗电,网络,软件和人力开销,降低了整体拥用成本TCO。
总结来看,Exadata为分析型Oracle数据库应用量身定制,所有的软硬件设计都是定制化的设计。而LinuxONE是一种相对比较通用的平台,它想尽一切办法去包容更多的应用类型,所以它不为任何应用而定制,只为容纳更多应用。从这个意义上讲,二者的选择取决于我们要跑什么样的业务类型。
作者:赵海,毕业于大连理工大学系统工程研究所。2007年加入IBM,任软件工程师,主要从事日本生命保险等项目的软件开发工作。2009年开始专注于日本松下电器项目的系统运维及优化工作。2011年加入惠普中国,任高级系统工程师,专注于客户案例解决及方案咨询工作。2013年加入IBM Devops Solution Team,参加云计算项目建设及部署,以及后期的咨询及解决方案提供工作。2014年加入某城商银行系统规划设计中心,任系统架构师,专注于银行数据中心解决方案规划及设计工作。
[转帖]“剖开” LinuxONE 和 Exadata,架构专家解读里面到底有什么
标签:lin 中国 返回 处理 基于 以太网 存储 work hid
原文地址:https://www.cnblogs.com/jinanxiaolaohu/p/9669621.html
{kind=link}