标签:设置 linu 存在 user 云服务器 主从模式 make about wait
linux安装单机版redis已经在另一篇文章说过了,下边来搞集群,环境是新浪云服务器:
redis3.0以后开始支持集群。
前言:redis用什么做集群?
用一个叫redis-trib.rb的ruby脚本。redis-trib.rb是redis官方推出的管理redis集群的工具,集成在redis的源码src目录下(redis-xxx/src/)。是基于redis提供的集群命令封装成简单、便捷、实用的操作工具。redis-trib.rb是redis作者用ruby完成的。所以redis集群需要先安装ruby环境。
先瞅瞅在哪:进入到redis的源代码目录,就可以看到redis-trib.rb脚本
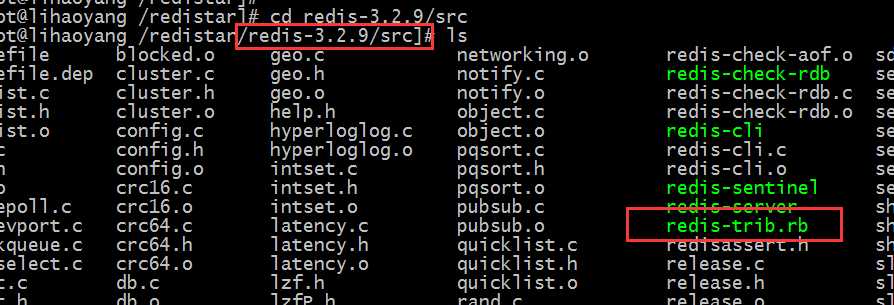
正文,一:安装ruby环境:(前提条件)
上文已经说了,redis集群是用的ruby脚本,所以要想执行该脚本,需要ruby环境。
安装ruby环境:
yum install ruby
yum install rubygems (ruby包的管理器,用来下载ruby的包)


显示Nothing todo,说明服务器已经安装了ruby。
二:安装ruby包redis-3.3.0.gem
redis-trib.rb的运行需要的ruby包,正如我们的java程序需要的jar包一样。
这个包和redis版本不是非得匹配,只要支持就行,我在网上找了个和redis -3.2.9版本接近的3.3.0版本。切换到redistar目录,用secureCRT的rz命令redis-3.3.0.gem上传到redistar目录,这个包安装到哪都行,只是提供一个环境而已。
用的secureCRT的rz命令上传到服务器,进入到redistar目录,执行rz命令,即可上传文件。

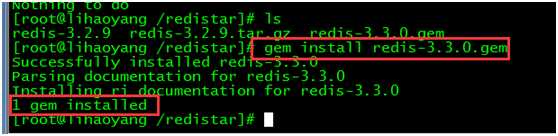
执行gem install redis-3.0.0.gem命令安装。
安装完成:
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
这里是介绍性东西:
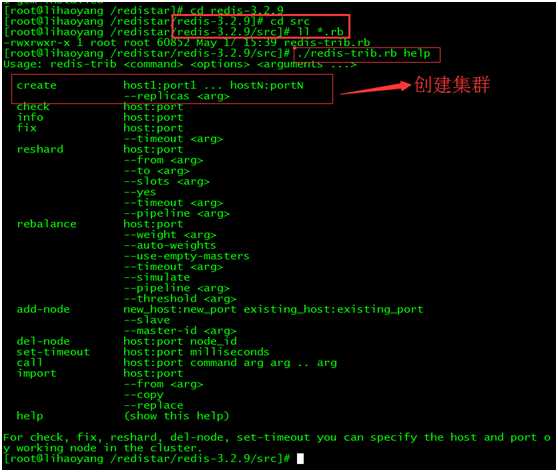
进入到redis的src目录,用ll *.rb找到redis-trib.rb文件,
执行命令./redis-trib help 可以查看该工具包提供的命令和功能

-rwxrwxr-x 1 root root 60852 May 17 15:39 redis-trib.rb
[root@lihaoyang /redistar/redis-3.2.9/src]# ./redis-trib.rb help
Usage: redis-trib <command> <options> <arguments ...>
create host1:port1 ... hostN:portN
--replicas <arg>
check host:port
info host:port
fix host:port
--timeout <arg>
reshard host:port
--from <arg>
--to <arg>
--slots <arg>
--yes
--timeout <arg>
--pipeline <arg>
rebalance host:port
--weight <arg>
--auto-weights
--use-empty-masters
--timeout <arg>
--simulate
--pipeline <arg>
--threshold <arg>
add-node new_host:new_port existing_host:existing_port
--slave
--master-id <arg>
del-node host:port node_id
set-timeout host:port milliseconds
call host:port command arg arg .. arg
import host:port
--from <arg>
--copy
--replace
help (show this help)
For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
下边是从别人文章找的解释:
可以看到redis-trib.rb具有以下功能:
ClusterNode 和 RedisTrib 。 ClusterNode 保存了每个节点的信息, RedisTrib 则是redis-trib.rb各个功能的实现。暂且只关注创建集群的功能。先简单介绍下redis-trib.rb脚本的使用,以create为例:
create host1:port1 ... hostN:portN
--replicas <arg>
host1:port1 ... hostN:portN 表示子参数,这个必须在可选参数之后, --replicas <arg> 是可选参数,带 的表示后面必须填写一个参数,像 --slave 这样,后面就不带参数,掌握了这个基本规则,就能从help命令中获得redis-trib.rb的使用方法。
例子:create创建集群
create命令可选replicas参数,replicas表示需要有几个slave。
有一个slave的集群的创建命令如下:
$ruby redis-trib.rb create--replicas 1 10.180.157.199:6379 10.180.157.200:6379 10.180.157.201:6379 10.180.157.202:6379 10.180.157.205:6379 10.180.157.208:6379
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
三:搭建我们的集群:
集群中有三个节点的集群,每个节点有一主一备。需要6台虚拟机。
搭建一个伪分布式的集群,使用6个redis实例来模拟。
1,在user/local 下创建redis-cluster目录:
mkdir redis-cluster

在创建redis01目录

进入usr/local/redis,把redis-cli、redis-server、redis.conf复制到/usr/local/redis-cluster/redis01目录

查看:

说明:这里安装redis单机版的时候,只用了make命令,没有make install,然后把redis-cli、redis-server、redis.conf三个文件copy到了自己手动建的/usr/local/redis目录,
如果用[root@bogon redis-3.0.0]# make install PREFIX=/usr/local/redis安装的redis单机版,还会有其他几个文件在/usr/local/redis目录,至于区别用途还不很清楚。
第一步:创建6个redis实例,端口号从7001~7006
第二步:修改redis的配置文件,后端启动daenonize改为yes是之前安装单机版已经做过的。
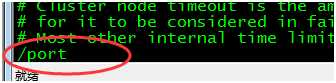
1、 修改端口号,进入vim编辑模式后,非insert模式下(insert了按esc即可退出)输入/port 回车可快速定位

2,打开cluster-enable前面的注释。:wq!保存编辑

3,复制redis01到当前目录,cp是复制,-r是连带子目录一并复制,并起名redis02、redis03、redis04、redis05、redis06
cp –r redis01/ redis02

修改redis02、redis03、redis04、redis05、redis06的端口号为7002、7003、7004、7005、7006
4:把创建集群的ruby脚本复制到redis-cluster目录下。
进入redis源码redistar/redis-3.2.9/src去copy:
cp *.rb /usr/local/redis-cluster/ *通配符,src目录只有一个.rb文件就是redis-trib.rb

查看
:
启动6个redis实例,一个一个去启动有点复杂,在redis-cluster目录创建一个脚本来启动6个实例:
cd /usr/local/redis-cluster
vim startall.sh就会打开vim编辑器,创建一个空的文本:
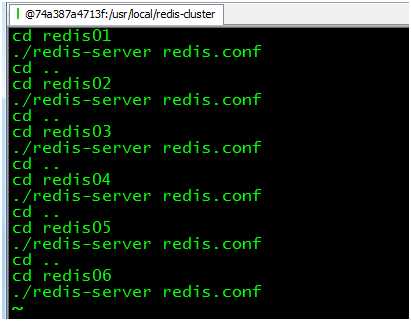
:wq!保存脚本,创建成功:
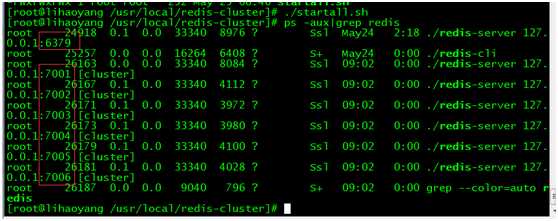
执行./startall.sh 提示permission denied说明权限不足,执行命令chmod 777 startall.sh修改权限

再执行./startall.sh, ps -aux|grep redis查看redis运行情况,6379是之前的redis没有停止
可以看到端口7001、7002、7003、7004、7005、7006的redis都起来了。
5:创建集群。
基于上边分割线内的介绍:在redis-cluster目录下执行以下命令:
./redis-trib.rb create --replicas 1 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006
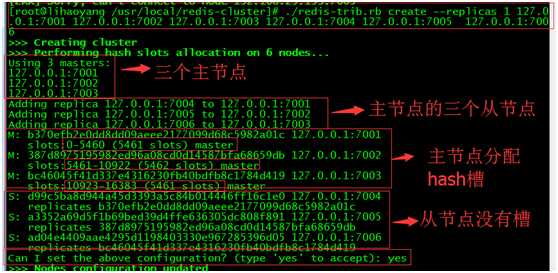
[root@lihaoyang /usr/local/redis-cluster]# ./redis-trib.rb create --replicas 1 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 >>> Creating cluster >>> Performing hash slots allocation on 6 nodes... Using 3 masters: 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 Adding replica 127.0.0.1:7004 to 127.0.0.1:7001 Adding replica 127.0.0.1:7005 to 127.0.0.1:7002 Adding replica 127.0.0.1:7006 to 127.0.0.1:7003 M: b370efb2e0dd8dd09aeee2177099d68c5982a01c 127.0.0.1:7001 slots:0-5460 (5461 slots) master M: 387d8975195982ed96a08cd0d14587bfa68659db 127.0.0.1:7002 slots:5461-10922 (5462 slots) master M: bc46045f41d337e4316230fb40bdfb8c1784d419 127.0.0.1:7003 slots:10923-16383 (5461 slots) master S: d99c5ba8d944a45d3393a5c84b014446ff16c1e0 127.0.0.1:7004 replicates b370efb2e0dd8dd09aeee2177099d68c5982a01c S: a3352a69d5f1b69bed39d4ffe636305dc808f891 127.0.0.1:7005 replicates 387d8975195982ed96a08cd0d14587bfa68659db S: ad04e4409aae4295d1198403330e967285396d05 127.0.0.1:7006 replicates bc46045f41d337e4316230fb40bdfb8c1784d419 Can I set the above configuration? (type ‘yes‘ to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join.... >>> Performing Cluster Check (using node 127.0.0.1:7001) M: b370efb2e0dd8dd09aeee2177099d68c5982a01c 127.0.0.1:7001 slots:0-5460 (5461 slots) master 1 additional replica(s) S: a3352a69d5f1b69bed39d4ffe636305dc808f891 127.0.0.1:7005 slots: (0 slots) slave replicates 387d8975195982ed96a08cd0d14587bfa68659db S: ad04e4409aae4295d1198403330e967285396d05 127.0.0.1:7006 slots: (0 slots) slave replicates bc46045f41d337e4316230fb40bdfb8c1784d419 M: bc46045f41d337e4316230fb40bdfb8c1784d419 127.0.0.1:7003 slots:10923-16383 (5461 slots) master 1 additional replica(s) S: d99c5ba8d944a45d3393a5c84b014446ff16c1e0 127.0.0.1:7004 slots: (0 slots) slave replicates b370efb2e0dd8dd09aeee2177099d68c5982a01c M: 387d8975195982ed96a08cd0d14587bfa68659db 127.0.0.1:7002 slots:5461-10922 (5462 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. [root@lihaoyang /usr/local/redis-cluster]#
集群搭建好了
测试集群
[root@lihaoyang /usr/local/redis-cluster]# redis01/redis-cli -h 192.168.25.153 -p 7002 –c
说明:-h+host –p+端口号 –c 是要连接集群,注意坑,不加会报错的
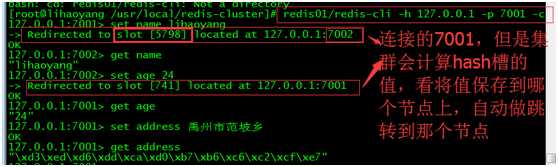
可以看到连接的是7001的节点,set name的时候计算了存在哪个hash槽上,会跳转到那个槽对应的节点。
不写-c的坑:

----------------------先写到这里,明天在补充,2017-05-25:23:20
首先,我们来看一下创建集群命令中 --replicas 1,这个代表什么意思呢?1其实代表的是一个比例,就是主节点数/从节点数的比例。那么想一想,在创建集群的时候,哪些节点是主节点呢?哪些节点是从节点呢?答案是将按照命令中IP:PORT的顺序,先是3个主节点,然后是3个从节点。这一点可以通过上面的2张图片印证。
其次,注意到图中slot的概念。slot对于Redis集群而言,就是一个存放数据的地方,就是一个槽。对于每一个Master而言,会存在一个slot的范围,而Slave则没有。在Redis集群中,依然是Master可以读、写,而Slave只读。数据的写入,实际上是分布的存储在slot中,这和以前1.X的主从模式是不一样的(主从模式下Master/Slave数据存储是完全一致的),因为Redis集群中3台Master的数据存储并不一样。这一点将在后续的实验中得到验证。
第五步:验证Redis集群搭建是否成功


到这里,Redis集群的搭建就完毕了,See U~
标签:设置 linu 存在 user 云服务器 主从模式 make about wait
原文地址:https://www.cnblogs.com/yaowen/p/9674636.html